Semantische Suche & Retrieval Engines
Systeme zur gezielten Informationsgewinnung aus komplexen Daten – durch semantisches Verständnis statt Schlagwortsuche.

Zugriff auf verteilte Daten durch intelligente Suchsysteme
Die meisten Informationen sind bereits vorhanden – sie sind nur nicht zugänglich. Klassische Suchsysteme scheitern an Heterogenität, fehlendem Kontext und dem schlichten Umfang verfügbarer Inhalte.
ontolux entwickelt Retrieval-Architekturen, die aus Daten nutzbares Wissen machen – für Suchsysteme, LLM-Anwendungen oder interne Wissensplattformen.
Im Zentrum steht nicht die Benutzeroberfläche, sondern das System dahinter: Die Kombination aus Vektorindizierung, semantischer Klassifikation, Hybrid-Retrieval und kontextsensitiver Relevanzbewertung – auch bei Millionen PDFs oder komplexen Forschungsdaten.

Vorgehen
Architektur nach Informationsbedarf
ontolux gestaltet Retrieval-Architekturen entlang konkreter Nutzungsszenarien: Welche Inhalte werden gesucht? Welche Strukturen liegen vor? Welche Art von Antwort wird erwartet?
Dabei stehen semantische Konzepte, technische Datenflüsse und tatsächliche Suchvorgänge im Fokus – nicht nur Indexe oder Tools.
Zentrale Designentscheidungen im Prozess:
- Auswahl zwischen Vektorisierung, Klassik-Indizierung oder hybriden Formen
- Einbindung von Metadaten, Zugriffszonen und Rollenrechten in die Indexlogik
- Integration von Wissensgraphen, RAG-Komponenten oder LLMs zur semantischen Anreicherung
Lösungen
Semantische Suche in der Praxis

Vektorindizierung & Embedding-Strategien
Semantische Repräsentationen für Dokumente, PDFs oder Protokolle – mit Auswahl und Training geeigneter Embedding-Modelle, abgestimmt auf Fachdomänen wie Wissenschaft, Recht oder Verwaltung.

Hybrid Retrieval & Wissensgraphen
Kombination klassischer und vektorbasierten Suche – ergänzt durch semantische Netze und Graphlogiken zur Kontextualisierung heterogener Inhalte.

Metadaten & Filterlogik
Nutzung struktureller Kontextdaten wie Typ, Quelle, Aktualität oder Gültigkeit – zur präziseren Steuerung der Relevanzentscheidung.

RAG-Systeme & Chat with your Data
Interaktive Systeme auf Basis von Retrieval-Augmented Generation – inklusive Dokumentation, Versionskontrolle und kontrollierbarer Datenbasis für dialogorientierte Nutzung.
Mehrwerte
Datenhoheit und Systemverständnis
ontolux entwickelt Suchsysteme, die intern betreibbar, nachvollziehbar und regulierungskonform sind – mit voller Kontrolle über Relevanz, Zugriff und Verhalten.
Nicht jede Organisation kann auf externe Suchanbieter oder SaaS-Produkte setzen – besonders nicht bei sensiblen Daten, regulatorischen Vorgaben oder proprietärem Wissen.
ontolux liefert nicht nur Suchfunktionalität, sondern semantische Infrastruktur mit vollständiger Kontrollfähigkeit – sichtbar, konfigurierbar, auditierbar.
Zusätzliche Kontrollmechanismen und Mehrwerte:
- Granulare Zugriffskontrolle auf Indizes, Vektorräume und Schnittstellen
- On-Premise-Skalierung für große Datenmengen (z. B. Millionen PDF-Dokumente)
- Auditierbare RAG-Komponenten mit Versionierung, Logging und Recovery
- Relevanztests, semantische Benchmarks und kontinuierliches Qualitätsmonitoring
Cases
Beispielhafte Anwendungskontexte

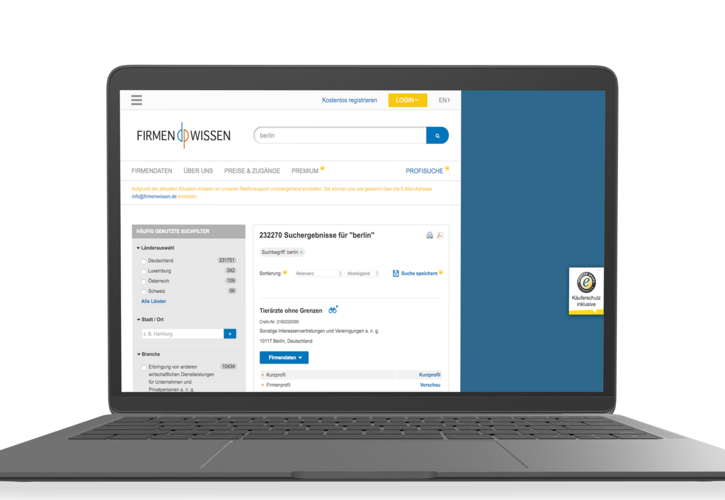
Interne Wissensdatenbanken mit semantischer Suche und Filterlogik

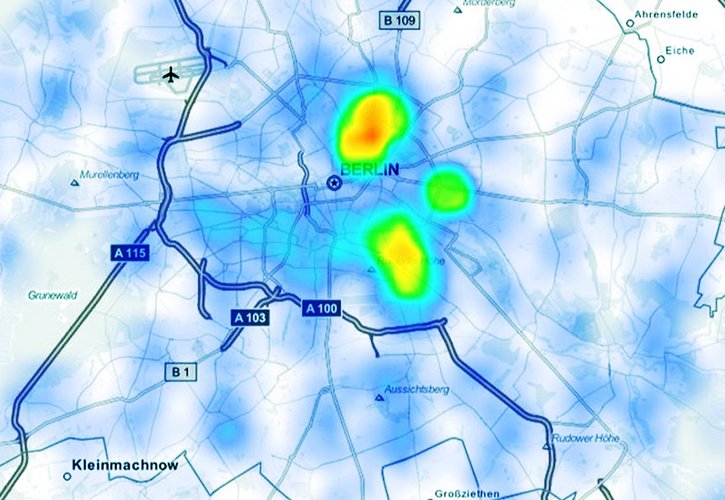
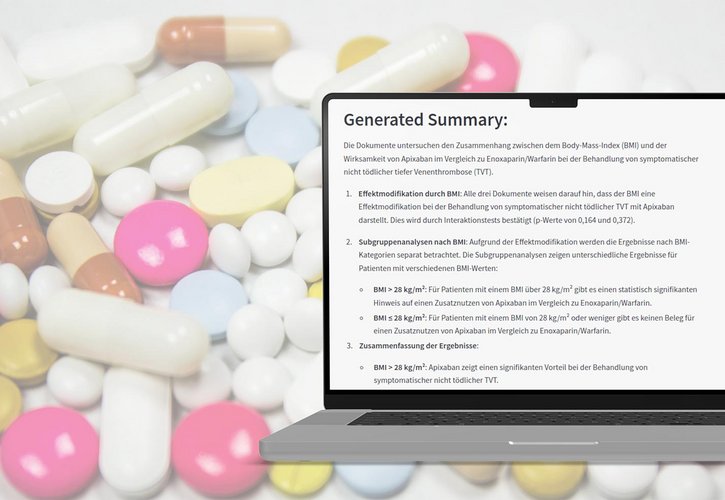
Recherchesysteme in der Wissenschaft inkl. Zitationsgraphen oder Paper-Ähnlichkeit
Juristische Suchportale mit kombinierten Normen- und Urteilsdatenbanken
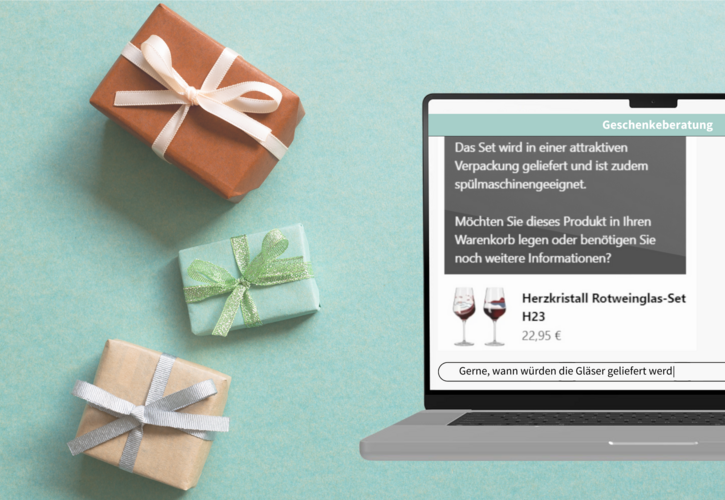
Chatbots mit direktem Zugriff auf eigene Dokumente – über RAG & Retrieval Layer
Unsere Technologien
Erfolgsgeschichten

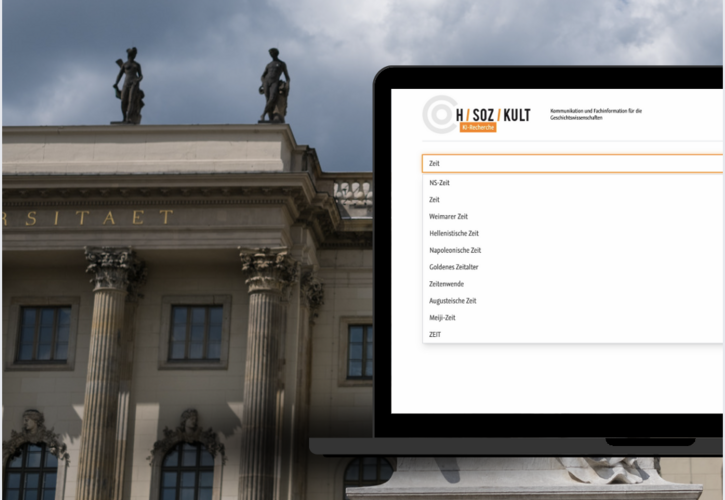



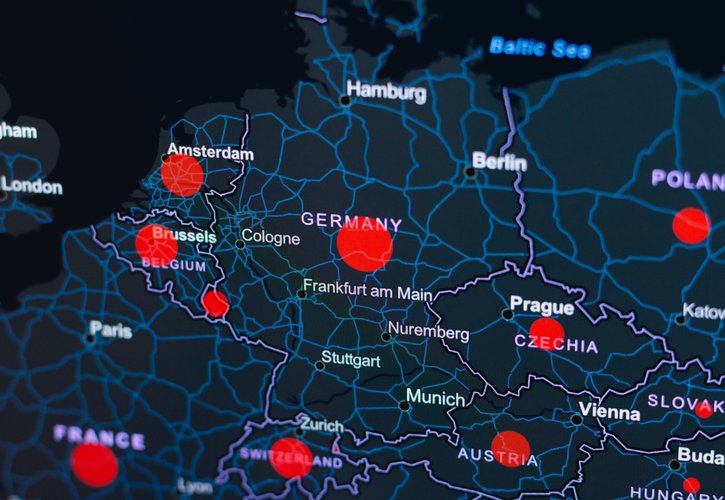
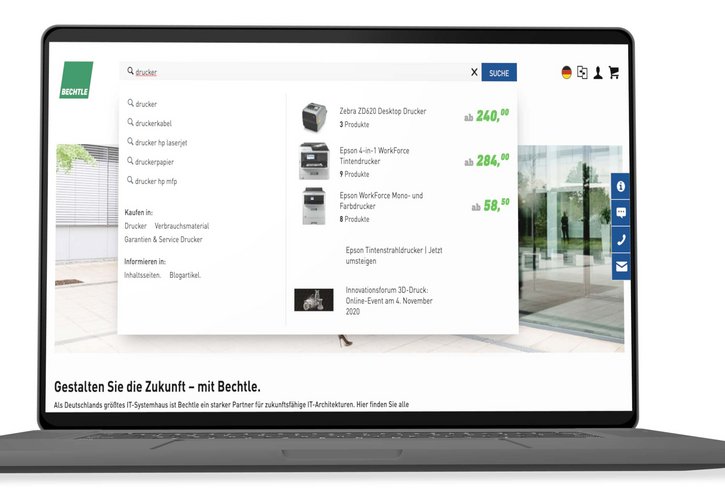





Sprechen Sie uns an
Semantische Suche ist kein Feature – sie ist ein Architekturprinzip. ontolux unterstützt beim Aufbau skalierbarer, erklärbarer und kontrollierter Retrieval-Systeme – von der Indizierung bis zur LLM-Integration.

*Ihre Daten werden vertraulich behandelt und nicht an Dritte weitergegeben. Lesen Sie dazu mehr in unserer Datenschutzerklärung.