
Machine Learning Consulting für automatisierte Geschäftsprozesse
Effektivität und Effizienz durch intelligente Algorithmen steigern.
Suchen Sie professionelles Machine Learning Consulting, um komplexe, wiederkehrende Handlungen zu automatisieren? Mit Machine Learning lassen sich schnell und effizient Muster erkennen, Vorhersagen treffen und Prozesse optimieren. Als Ihre Experten für Machine Learning Consulting beraten wir Sie dabei, Potenziale zu identifizieren und Ihre Workflows nachhaltig zu verbessern.
MACHINE LEARNING
Problemlösung mit selbstlernenden Systemen
Machine Learning ist ein Teilgebiet der Künstlichen Intelligenz. Dabei lernen IT-Systeme, selbstständig aus großen Datenmengen Muster, Zusammenhänge und Abhängigkeiten zu erkennen und auf unbekannte Daten anzuwenden. Damit IT-Systeme selbständig solche Entscheidungen treffen können, müssen die Algorithmen trainiert und ein auf die Fragestellung bezogenes Modell entwickelt werden. Der Trainingsprozess erfolgt zyklisch, wobei bestehende Modelle getestet und kontinuierlich optimiert werden.
Unternehmen können so automatisiert Entscheidungen treffen und die Effizienz ihrer Prozesse deutlich verbessern.
Wahrscheinlichkeiten berechnen
Vorhersagen treffen
Prozesse optimieren
Schlussfolgerungen ziehen
Fehler und Defekte erkennen
Unsere Leistungen im Machine Learning Consulting
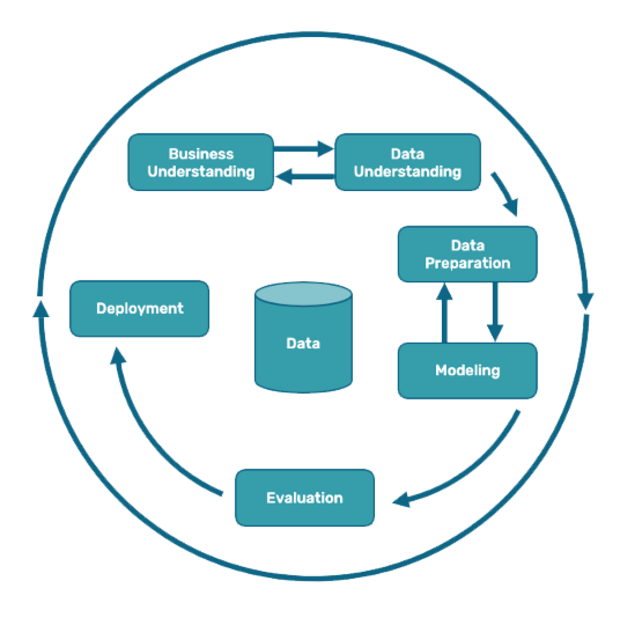
Wir helfen Ihnen, Ihre Daten und Prozesse in Hinblick auf den Einsatz von Machine Learning zu bewerten und vorzubereiten, sowie ein passendes Modell für Ihren Anwendungsfall zu identifizieren, zu trainieren und in Produktion zu bringen.
Business Understanding
Für den erfolgreichen Einsatz von Machine Learning Consulting müssen Erwartungen und Geschäftsnutzen in Einklang gebracht werden. Als Basis hierfür dient oft unsere KI-Potenzialanalyse.
Data Understanding
Welche Daten stehen zur Verfügung und welche Daten sind notwendig für automatisierte Prozesse. Wir verschaffen uns einen ersten Überblick über die zur Verfügung stehenden Daten und deren Qualität, um Datenqualität Ihres Vorhabens zu bewerten.
Daten Aufbereitung
Um ein Modell mit entsprechenden Daten trainieren zu können, sind ausreichend gelabelte Trainingsdaten notwendig. Wir eruieren vorhandene Daten nach Art und Menge, schließen ggf. Datenlücken, evaluieren Wege zur Datenerhebung und identifizieren mögliche Qualitätsprobleme.
Architektur und Modelle
Ganz gleich, welche Fragestellung Sie beantworten möchten – mit unserer Expertise wählen wir die passende Architektur und Modelle aus, die den größtmöglichen Trainingserfolg erzielen und auf Ihr Ziel ausgerichtet sind.
Modelltraining
Vor einem Training bestimmen wir die passende Architektur für die gelabelten Daten und trainieren je nach Fragestellung und Ziel mit bereits vorhandenen, individuell angepassten oder auch neuen eigenen Modellen. Unser Ziel: ein kundenindividuelles Modell mit den besten Ergebnissen.
Evaluation
In Form eines Workshops präsentieren und visualisieren wir Ihnen die Ergebnisse aus der Trainingsphase und bewerten gemeinsam, inwieweit das trainierte Modell bereits erfolgreich produktiv eingesetzt werden kann oder noch weiter angepasst und optimiert werden sollte.
GUTE GRÜNDE
Unsere Datenexpertise für Ihren Erfolg
Wir arbeiten sowohl in unseren Forschungs- als auch unseren Kundenprojekten mit unterschiedlichen Modellen und Methoden. Wir verarbeiten sowohl strukturierte als auch unstrukturierte Daten und sind in der Lage, Informationen aus Texten, Bildern, Audios oder Videos für das maschinelle Lernen aufzubereiten. Dabei setzen wir Neuronale Netze, Support Vector Machines oder klassische Expertensysteme ein. Aber auch für numerische Daten haben wir Big-Data- und BI-Lösungen zur Hand.

Service
NLP
Natural Language Processing (NLP) ist ein Teilbereich der künstlichen Intelligenz, der sich mit der Wechselwirkung zwischen menschlicher Sprache und Computern beschäftigt. Es verwendet Algorithmen und Techniken, um menschliche Sprache in eine für Computer verständliche Form umzuwandeln und ermöglicht so die Verarbeitung, Analyse und Generierung von Texten. NLP wird in einer Vielzahl von Anwendungen eingesetzt, darunter maschinelles Übersetzen, Chatbots, Textanalyse, Informationsextraktion und Sentimentanalyse. Wir unterstützen Sie mit der passenden Technologie von der Konzeption bis zur Produktivsetzung.
Service
Deep Learning
Deep Learning ist eine leistungsstarke Technologie im Bereich der künstlichen Intelligenz, die es ermöglicht, komplexe Muster in unstrukturierten Daten zu erkennen und zu interpretieren. Im Gegensatz zu herkömmlichen Machine Learning-Verfahren, bei denen Features manuell extrahiert werden müssen, kann Deep Learning mittels künstlicher neuronaler Netze automatisch relevante Merkmale aus Bildern, Texten, Sprache und sogar sensorischen Daten erlernen.
Deep Learning eröffnet neue Horizonte für datengesteuerte Entscheidungen und ermöglicht Unternehmen, wertvolle Erkenntnisse aus ihren umfangreichen Datenquellen zu gewinnen.

Service
Computer Vision
Computer Vision ist der Schlüssel zur visuellen Wahrnehmung von Maschinen. Es verleiht Computern die Fähigkeit, Bilder und Videos zu verstehen, zu analysieren und darauf basierende Entscheidungen zu treffen, ähnlich wie der Mensch es vermag. Computer Vision wird u.a. in der Bilderkennung eingesetzt, um Objekte und Muster in Bildern zu identifizieren. Diese Fähigkeit findet in der Sicherheitsüberwachung, medizinischen Bildgebung und automatisierten Qualitätskontrolle vielfältige Anwendungen. Wir unterstützen Sie bei der Implementierung von Computer Vision in Ihrem Unternehmen und maßgeschneiderte Lösungen zu entwickeln.
Service
Data Analytics
Data Analytics ist ein entscheidendes Instrument in der Welt der Datenwissenschaft. Durch den Einsatz fortschrittlicher statistischer und mathematischer Methoden werden große Datenmengen analysiert, um wertvolle Erkenntnisse und Muster zu gewinnen. Mit Data Analytics können Unternehmen fundierte Entscheidungen treffen, Prozesse optimieren und die Kundenzufriedenheit steigern. Unsere Experten nutzen Algorithmen wie maschinelles Lernen und Data Mining, um Trends zu identifizieren, Risiken zu minimieren und Chancen zu erkennen.

Service
Data Engineering
Data Engineering umfasst die Sammlung, Aufbereitung und Transformation von Daten in eine für Maschinen verständliche Form. Es ermöglicht die Schaffung von robusten Datenpipelines, die die Grundlage für datengetriebene Entscheidungsprozesse und maschinelles Lernen bilden. Ob für die Optimierung von Geschäftsprozessen, die Vorhersage von Trends oder die Entwicklung von KI-Anwendungen, Data Engineering spielt eine zentrale Rolle bei der Gewinnung wertvoller Erkenntnisse aus Daten.

Service
ML-Ops
Machine Learning Operations (ML-Ops) bezieht sich auf die effiziente Verwaltung und Skalierung von Machine-Learning-Modellen in Produktionsumgebungen. ML-Ops kombiniert bewährte DevOps-Praktiken mit spezialisierten Werkzeugen und Prozessen, um die Bereitstellung, Überwachung und Aktualisierung von KI-Modellen zu automatisieren. Dies ist entscheidend, um die Leistung von KI-Anwendungen zu optimieren, Kosten zu senken und sicherzustellen, dass Modelle in Echtzeit präzise und zuverlässig arbeiten.

Service
Hosting und Deployment
Für die Testphase und vor der Komprimierung sind meist große Serverkapazitäten von mehreren Grafik- oder Tensor-Prozessoren vonnöten. Um hierbei Ressourcen und Lasten optimal zu verteilen, setzen wir auf Container-Orchestrierung mit Kubernetes. Ganz gleich ob in der Cloud oder auf dedizierten Servern - wir sorgen für einen kostengünstigen und sicheren Rechenbetrieb, unterstützen beim Deployment Prozess und beraten Sie zu geeigneten Angeboten und Sicherheitsaspekten.
Überzeugen Sie sich selbst
Kundenprojekte

G+J Digital Products
Für die Erstellung einer Content Curation Engine werden Texte aus 1.500 Web-Datenquellen für Redakteure aufbereitet, mit verschiedenen Methoden des Maschine Learning nach sprachlicher und inhaltlicher Qualität bewertet und klassifiziert.
Entitätenerkennung
Klassifizierung der Mediathek
Sprachliche Analyse mit Machine Learning & NLP

PMG
Alle Texte in der PMG Pressedatenbank werden semantisch mit NLP Methoden analysiert, klassifiziert und unter Verwendung von maschinellem Lernen angereichert, um die Suchfunktion auf dem Portal zu optimieren.
Entitätenerkennung
Semantische Analyse
Schlüsselworterkennung

DAB
Für die Digitalagentur Berlin wurden 10.000 Förderanträge analysiert und inhaltlich ausgewertet, um schneller die Förderziele und Themen der Unternehmen sowie deren konkret geförderten Anschaffungen zu verstehen.
Klassifikation von Förderzielen
Themenerkennung
Enitätenerkennung
Was ist die Definition von Machine Learning?
Maschinelles Lernen ist ein Zweig der KI, bei dem Computer mithilfe von Algorithmen aus Daten lernen und Vorhersagen und Entscheidungen treffen, ohne explizit programmiert zu werden. Es ermöglicht, Muster und Zusammenhänge in den Daten zu erkennen und daraus zu lernen, um zukünftige Aufgaben besser zu bewältigen.
_________
Was ist der Unterschied zwischen Machine Learning, Deep Learning, und Natural Language Processing?
Machine Learning nutzt Algorithmen zur Mustererkennung und Vorhersagen ohne explizite Programmierung. Deep Learning basiert auf neuronalen Netzen und lernt tiefe Merkmalsstrukturen. Natural Language Processing konzentriert sich auf Sprachverarbeitung und -verständnis durch Computer.
_________
Was ist der Unterschied zwischen KI und Machine Learning?
KI ist ein Oberbegriff für Computerprogramme, die menschenähnliche Denkprozesse ausführen. Machine Learning ist eine Teilmenge der KI. Sie konzentriert sich darauf, Algorithmen zu entwickeln, die es einem Computer ermöglichen aus Daten zu lernen und Vorhersagen zu treffen, ohne explizit programmiert zu werden. Kurz gesagt, Machine Learning ist eine Methode, mit der KI-Systeme geschaffen werden können.
_________
Welche 4 Arten von Algorithmen Machine Learning gibt es?
Es gibt überwachtes Lernen (Supervised Learning), unüberwachtes Lernen (Unsupervised Learning), bestärkendes Lernen (Reinforcement Learning) und semi-überwachtes Lernen (Semi-Supervised Learning).
Beim überwachten Lernen werden gelabelte Trainingsdaten verwendet, um Vorhersagen oder Klassifikationen zu machen. Beim unüberwachten Lernen werden Strukturen in unbekannten Daten entdeckt, ohne dass sie gelabelt sind. Beim bestärkenden Lernen lernt der Algorithmus durch Belohnungen oder Strafen. Semi-überwachtes Lernen nutzt sowohl gelabelte als auch ungelabelte Daten, um Modelle zu trainieren und ermöglicht es, große Datensätze mit begrenzten gelabelten Daten zu verarbeiten.
_________
Welche Anwendungen gibt es für überwachtes Maschinelles Lernen in modernen Unternehmen?
Einige gängige Beispiele für den Einsatz von überwachtem Machine Learning in Unternehmen sind Predictive Analytics, Klassifizierung, Anomalieerkennung und Sprachverarbeitung. In Predictive Analytics werden Vorhersagen über zukünftige Ereignisse oder Trends getroffen, während Klassifizierung Daten in verschiedene Kategorien einteilt. Anomalieerkennung dient dazu, ungewöhnliche Muster aufzudecken, die auf potenzielle Probleme hinweisen könnten. Die Sprachverarbeitung umfasst die automatische Spracherkennung und -übersetzung sowie die Analyse von Textdaten. Überwachtes Machine Learning eignet sich daher besonders im Kundenservice, aber auch in der Medizin, Logistik und für die Analyse von Produktions bzw. Fertigungsprozessen.
_________
Was ist der Unterschied zwischen einem Expertensystem und Machine Learning?
Expertensysteme basieren auf vordefiniertem Wissen und werden für konkrete Probleme entwickelt, während Maschinelles Lernen auf Daten basiert und Muster und Zusammenhänge in den Daten erkennt, um intelligente Entscheidungen zu treffen. Expertensysteme sind in spezialisierten Bereichen wie Medizin oder Finanzen üblich, während maschinelles Lernen in verschiedenen Anwendungen wie Predictive Analytics, Bilderkennung und Sprachverarbeitung eingesetzt wird.
_________
Wann eignet sich Machine Learning besonders?
Wenn für wiederkehrende Tätigkeiten, die beschreibbar und komplex sind auch ausreichende und passende Daten vorliegen, dann sollten Sie darüber nachdenken, Algorithmen die Arbeit übernehmen zu lassen.
_________
Kontakt
Sprechen Sie uns an
