
Textdaten automatisiert verwerten
Mittels Text Mining können unstrukturierte Textinhalte strukturiert und für digitale Prozesse und Lösungen nutzbar gemacht werden. Verschaffen Sie sich einen Wissensvorsprung und profitieren Sie von den Informationen, die in Ihren Textdaten liegen. Als Text Mining-Spezialist unterstützen wir Sie, Ihre Textdaten so zu verwerten, dass Sie Ihren Nutzern und Kunden Mehrwerte liefern können.

TEXT MINING
Mit Text Mining Erlebnisse schaffen
Fast 80 Prozent aller Daten liegen in Textform wie E-Mails, Dokumenten, Kommentaren, PDFs, Dokumentationen und ähnlichem vor. Um sie für automatisierte Prozesse und Anwendungen zu nutzen, müssen diese Daten in strukturierte Daten verwandelt werden. Erst durch Text Mining-Verfahren werden natürlichsprachige Texte maschinell verstehbar. Diese Verfahren bilden die Grundlage, um Informationen aus Textdaten zu extrahieren, mit zusätzlichen Informationen anzureichern und daraus datengetriebene KI-basierte Anwendungen zu entwickeln.
Unsere Leistungen
Als Spezialist für Text Mining haben wir Verfahren und Algorithmen entwickelt, mit denen wir nahezu 100 Prozent eines Textes automatisiert verstehen.
Beratung
Wir zeigen Ihnen, welche internen und externen Informationen Sie sich zunutze machen können und beraten beim Aufbau datengesteuerter Prozesse.
NLP & ML
Wir analysieren und verstehen automatisiert deutsche und englischsprachige Texte. Mit Hilfe von Natural Language Processing erkennen wir die Bedeutung, reichern Textdaten mit zusätzlichen Informationen an und optimieren sie durch Machine Learning.
Integration
Wir implementieren Text Mining-Frameworks in Ihre Systemstruktur, binden externe Wissensdatenbanken und Expertensysteme an und schaffen automatisierte Text Mining-Anwendungen. Je nach Wunsch stellen wir Ihnen diese als Software-as-a-Service oder On-Premise zur Verfügung.
Coden
Auf Basis der extrahierten Informationen erstellen wir datenbasierte Anwendungen, die Ihre Informationen auswertbar machen, zusätzliche Services bieten oder Prozesse vereinfachen.

Service
Entities
Die Entitätenerkennung ist eine unserer Kernkomponenten und wird stetig weiterentwickelt. Dabei nutzen wir eine Kombination aus Machine Learning und einem lexikonbasierten Verfahren, bei dem wir auf Millionen von Daten aus Wikidata und Wikipedia zurückgreifen. Die genutzten Algorithmen sind zudem auf spezielle Domains erweiterbar (Gesundheit, Recht, ...), wodurch Sie auch aus Ihrem individuellen, domänenspezifischen Wissen in Ihren Textdaten optimalen Nutzen ziehen.

Service
Named Entity Recognition (NER)
In Wikidata nicht vorhandene Entitäten lassen sich automatisch erkennen. Mithilfe des NER-Verfahrens können anhand des Kontexts und der Satzstruktur Entitäten wie Personen, Organisationen oder Orte erkannt werden. Sie sind damit völlig unabhängig von einem zu pflegenden Lexikon bzw. Wissensdatenbank. Man kann das auch das Lieschen-Müller- oder Otto-Normalbürger-Problem nennen.

Service
Disambiguierung (NERD)
Viele Wörter haben mehrere Bedeutungen und sind erst im Kontext klar zuordenbar. Um diese aus Texten zu erkennen, werden zunächst Kandidaten für Entitäten erkannt und mit den anderen im Kontext vorkommenden Entitäten vektorbasiet verglichen. Das Modul erkennt für Sie die wichtigsten Informationen in Texten, wie beispielsweise Personen, Orte, Organisationen, Events, aber auch je nach Domäne z.B. Krankheiten oder Paragrafen. NERD ist eine wesentliche Technik in vielen NLP-Anwendungen, einschließlich Empfehlungssystemen und Frage-Antwort-Systemen.

Service
Sentiment Analysis
Nutzer hinterlassen über Kommentare ihre Meinungen, deren gezielte Analyse ein Stimmungsbild zur Marke, Produkten und Services zulässt. Auf Basis statistischer Verfahren ermitteln wir positive und negative Wörter und ermittelt einen Gesamtscore Ihres Textes. Dadurch sind Sie in der Lage, schneller auf Meinungsbilder zu reagieren, Quellen zu identifizieren, Ihre Services zu verbessern und Trends zu erkennen.

Service
Klassifikation
Unsere Textklassifikation ordnet Ihre Dokumente automatisch Kategorien zu und erleichtert Ihnen damit das Datenmanagement. Unsere Modelle lassen sich für jede kundenspezifische Anforderung anpassen. Dazu trainieren wir mit Natural Language Processing neuronale Netze auf Ihre gewünschten Klassen. Zudem bringen wir ein vortrainiertes Modelle für Nachrichtenmeldungen mit, welches Texte den Kategorien Internet, Kultur, Wirtschaft, Reisen, Wissenschaft, Politik, Sport, Auto/Technik zuordnet.

Service
Schlüsselworterkennung
Wir extrahieren die wichtigsten Schlüsselwörter (tags) aus Texten. Wir benutzen hierzu statistische Algorithmen, Machine Learning und Techniken der natürlichen Sprachverarbeitung (NLP), um Ihre Daten zu analysieren. Die Schlüsselworterkennung bildet die Basisfunktion, um Textdateien zu strukturieren oder zu clustern. Die gewonnenen Tags eignen sich zur Indexierung, Filterung oder zur weiteren Dimensionsreduktionen von Texten.

Service
Gesetze
Wir sind in der Lage, im Text referenzierte Paragrafen zu erkennen und in strukturierte Form zu bringen. Dabei setzen wir sowohl auf Machine Learning als auch regelbasierte Verfahren. Die Auswertung von rechtlichen Texten zum Beispiel im Bereich Steuern und Finanzen wird damit vereinfacht und bietet die Basis zur weiteren maschinellen Verarbeitung.
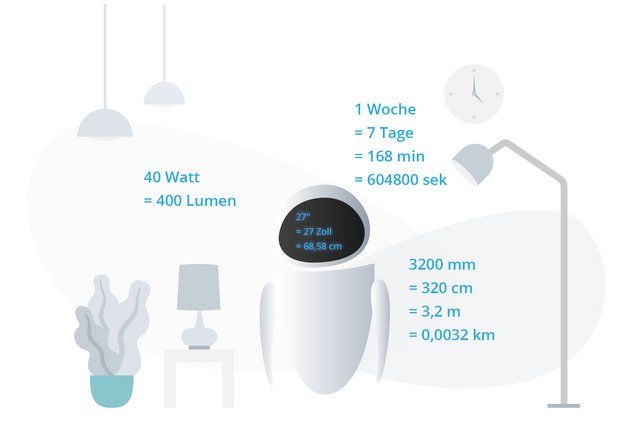
Service
Maßeinheiten
In vielen Texten kommen physikalische Maßeinheiten vor. Dazu zählen u.a. Zeit-, Längen-, Gewichts-, Temperatur- oder Währungsangaben uvm. Wir extrahieren über ein regelbasiertes Verfahren die Daten und wandelt diese bei Bedarf in eine Basiseinheit um. Von der automatisierten Maßeinheitenerkennung profitieren vor allem technisch orientierte Branchen.

Service
Zeitangaben
Wir extrahieren Zeitangaben aus Texten und filtert konkrete Datumsangaben oder Zeiträume heraus. Dazu nutzen wir regelbasierte Verfahren und stellen anhand eines festgelegten Referenzdatums einen Bezug her, so dass Zeiträume oder relative Angaben wie “gestern”, "letzte Woche" oder "vor vier Jahren" erkannt werden.

Service
Ähnlichkeiten
Um Ähnlichkeiten in unterschiedlichen Texten festzustellen und um Duplikate in Texten zu finden, ermöglicht unser Fingerprint Modul eine schnelle Lösung. Wir liefern für jedes Dokument einen Vektor, der zur Berechnung der Ähnlichkeit von Dokumenten verwendet werden kann. Dadurch ist es möglich, ähnliche Dokumente (Near Duplicates) zu filtern und zu clustern. Neue Meldungen und Dokumente lassen sich so einfach abgleichen.

BRANCHEN
Text Mining für die öffentliche Verwaltung
Ministerien, Behörden und Einrichtungen der öffentlichen Hand stehen vor der Herausforderung, interne Abläufe zu digitalisieren und ihre Dienstleistungen im Rahmen des OZG über Portale bereitzustellen. Viele Vorgänge erfordern die automatische Verarbeitung von Texten, die als Akten, Formulare, Berichte oder wissenschaftliche Publikationen vorliegen. Um in natürlichsprachigen Texten enthaltene Informationen in digitalen Anwendungen nutzen zu können, müssen sie mit Text Mining Verfahren maschinell lesbar und interpretierbar gemacht werden.
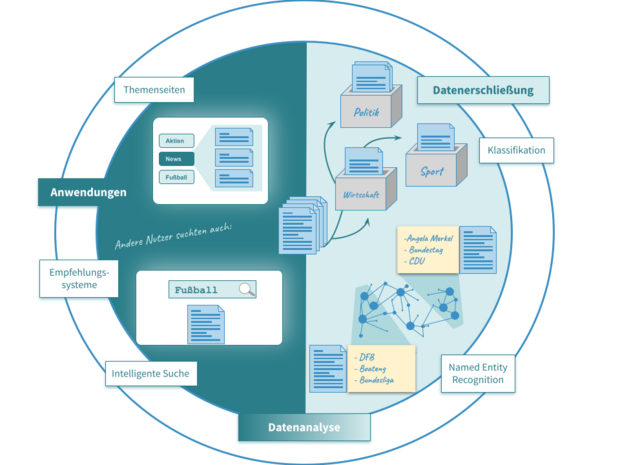
BRANCHEN
Text Mining für die Medienbranche
Zur Entlastung von Redakteuren und erfolgreicher Prozessautomatisierung gilt es, redaktionelle Textdaten wirklich zu verstehen. ontolux nutzt Text-Mining-Methoden, um semantische Zusammenhänge innerhalb von und zwischen Texten sichtbar zu machen. Von einer initialen Erschließung Ihrer Medien bis hin zu einer tiefergehenden Analyse, die in individuellen Software-Lösungen resultiert, unterstützt ontolux die redaktionelle Arbeit.
Überzeugen Sie sich selbst
Kundenprojekte

G+J Digital Products
Für die Erstellung einer Content Curation Engine werden Texte aus 1.500 Web-Datenquellen für Redakteure aufbereitet, Informationen extrahiert und nach ausgewählten Kriterien herausgefiltert.
Entitätenerkennung
Klassifizierung der Mediathek
Optimierte Suche und Empfehlungssystem

PMG
Alle Texte in der PMG Pressedatenbank werden semantisch analysiert, klassifiziert, angereichert und indexiert, um die Suchfunktion auf dem Portal zu optimieren.
Indexierung und Anreicherung
Semantische Analyse
Optimierte Portal-Suche
Wir-liefern.org
Mittels eines NLP-Frameworks werden die von verschiedenen Charity-Anbietern eingetragenen Angebote klassifiziert, verschlagwortet und für die Website-Suche aufbereitet.
Text-Klassifikation
Semantische Verschlagwortung
Verbesserte Suche
Was versteht man unter Text Mining?
Text Mining ist ein Analyseverfahren, indem mithilfe von Algorithmen aus unstrukturierten Daten sinnvolle Erkenntnisse und Strukturen erzeugt werden. Die Algorithmen greifen dabei auf linguistische sowie statistische Methoden zurück.
So lassen sich bspw. E-Mails oder PDFs nach bestimmten Kriterien auswerten, um nützliche Insights daraus zu generieren.
_________
Was sind NLP-Frameworks?
NLP-Frameworks stellen technische Grundgerüste dar, wo Entwickler schon auf vorgefertigte Funktionen in Bezug auf Natural Language Processing zurückgreifen können.
Whitepaper: NLP-Frameworks im Vergleich

Was sind Wissensgraphen?
Wissensgraphen sind Wissensdatenbanken, die auf ein grafisch-strukturiertes Datenmodell basieren. Wissensgraphen werden verwendet, um Verbindungen zwischen Entitäten, Objekten, Events etc. herzustellen und aufzuzeigen. Wir stellen einen Wissensgraphen auf Basis von Wikipedia bereit.
_________
Was bedeutet Named Entity Recognition und Disambiguation (NERD)?
Bei der Entity Recognition (Entitäten-Erkennung) werden Texte daraufhin untersucht, welche Entitäten der realen Welt entsprechen (typischerweise Personen).
Die Funktion wird mit Entity Linking oder Disambiguation verknüpft, dadurch werde die Entitäten eindeutig mit einer Wissensdatenbank (z.B.: Wikipedia) verlinkt. Findet sich bspw. in einem Text der Begriff “Krebs”, so kann man mithilfe der NERD festgestellt werden, ob es sich um das Sternzeichen, Tier oder Krankheit handelt.
_________
Was ist Sentiment und Opinion Mining?
Beim Sentiment und Opinion Mining werden Texte auf ihren enthaltenen Emotionen untersucht. So kann eine positive, neutrale oder negative Stimmung extrahiert werden.
Dafür eignen sich insbesondere Reviews, um auszulesen, wie Käufer das gekaufte Produkt fanden.
_________
Was versteht man unter Text-Klassifikation?
Bei der Text-Klassifikation geht es darum, einen Text innerhalb vorgegebener Themenbereiche inhaltlich zu verorten, z. B. anhand von Ressorts ähnlich wie bei Zeitungen. Handelt es sich bei dem Text eher um einen politischen, einen kulturellen oder geht es um Sport?
_________
Kontakt
Sprechen Sie uns an
