Textverständnis & Wissenserschließung
Systeme zur Analyse, Strukturierung und Interpretation unstrukturierter Inhalte – mit Methoden der maschinellen Sprachverarbeitung.

Von unstrukturiertem Text zu maschinenlesbarem Wissen
Der Großteil verfügbarer Informationen liegt in Textform vor – frei formuliert, domänenspezifisch, unstrukturiert. Die Herausforderung besteht nicht im Speichern, sondern im Verstehen.
ontolux entwickelt Systeme zur automatisierten Textverarbeitung und Inhaltsanalyse: von der semantischen Annotation bis zur domänenspezifischen Strukturierung großer Textmengen.
Ob zur Klassifikation von Dokumenten, zur Extraktion relevanter Informationen oder als Vorverarbeitung für Retrieval- und RAG-Systeme – entscheidend ist, dass Textinhalte systematisch erschlossen und in operativ nutzbares Wissen übersetzt werden.

Vorgehen
Analyse entlang funktionaler Zielsetzung
Nicht jede Analyse erfordert ein LLM. Und nicht jedes LLM versteht Kontext.
ontolux entwickelt Textverarbeitungspipelines nicht entlang von Hype-Technologien, sondern entlang konkreter funktionaler Ziele. Ob PDF-Auswertung, Annotation, Zusammenfassung oder semantische Vorbereitung – entscheidend ist der Nutzen, nicht das Modell.
Dazu kommen je nach Zielsetzung verschiedene Verfahren zum Einsatz:
- Strukturierte Extraktion aus PDFs, Studien oder Urteilen
- Klassifikation und Annotation für Relevanzbewertung, Kategorisierung oder Trainingsdaten
- Automatisierte Zusammenfassungen und Querverweise – generisch oder zielgruppenspezifisch
- Semantische Vorverarbeitung für nachgelagerte Retrieval- oder RAG-Systeme
Zum Einsatz kommen klassische NLP-Verfahren, regelbasierte Extraktion, embeddinggestützte Klassifikatoren oder domänenspezifisch feinjustierte Sprachmodelle. Die entstehenden Ergebnisse können nahtlos in bestehende Datenmanagement-Strukturen eingebettet oder für weiterführende Datenprozesse aufbereitet werden.
Lösungen
Textverstehen in Anwendungskontexte

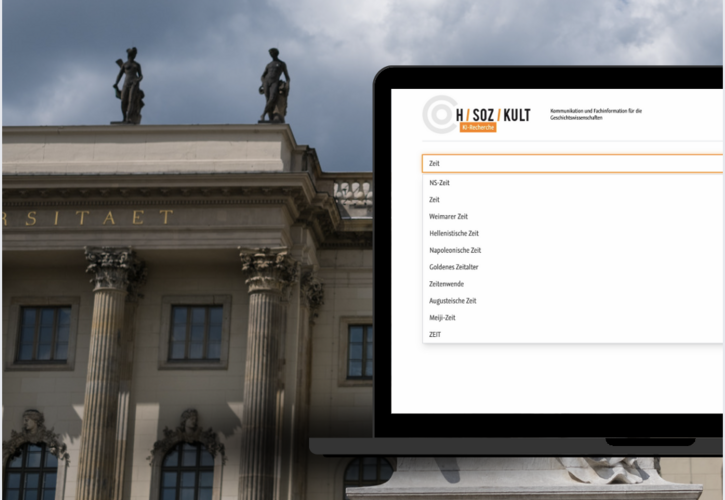
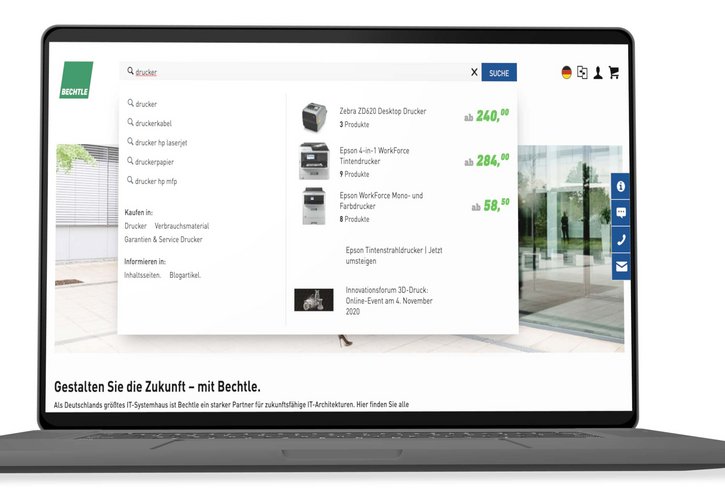
Informationsextraktion
Strukturierte Informationen aus unstrukturierten Quellen – etwa Entitäten, Beziehungen, Ereignisse oder Argumentationsmuster. Ideal für juristische, medizinische oder forschungsbezogene Inhalte.

Klassifikation & Annotation
Dokumente und Abschnitte werden automatisch nach Thema, Relevanz, Zweck oder Inhaltstyp zugeordnet – z. B. für Trainingsdaten, Wissensdatenbanken oder Content-Filter.

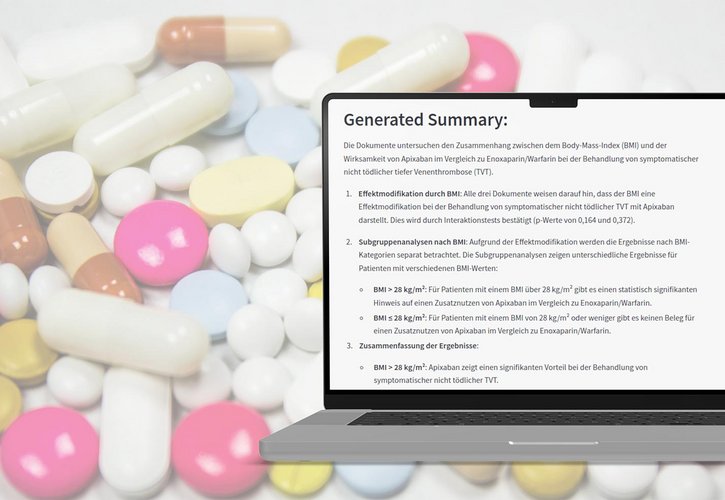
Zusammenfassungen & semantische Abstraktion
Aus langen Texten entstehen prägnante Abstracts, strukturierte Bulletpoints oder nach Zielgruppen aufbereitete Zusammenfassungen – optional mit Feedbackloop und Editierlogik.

Domänenspezifische Sprachmodelle
ontolux entwickelt LLMs mit fachspezifischem Sprachverständnis – etwa für Technik, Recht oder Forschung. Fine-Tuning und Distillation kommen dort zum Einsatz, wo Modelle präzise auf Aufgaben, Ressourcen oder Qualitätsziele abgestimmt werden müssen. In Kombination mit Wissensgraphen entstehen Systeme für intelligentes Informationsmanagement und erweiterte Recherche.
„Maschinelles Textverständnis darf nicht weniger nachvollziehbar sein als menschliche Interpretation – es sollte strukturierter sein.“
Mehrwerte
Interpretierbarkeit und Validierung
Gerade in forschungsnahen oder regulatorischen Kontexten ist nicht nur das Ergebnis entscheidend, sondern auch der Weg dorthin.
ontolux entwickelt Systeme mit nachvollziehbarer Verarbeitung, überprüfbaren Zwischenergebnissen und gezielter Modellsteuerung – mit Fokus auf Validierbarkeit und Auditierbarkeit. Damit entsteht maschinelles Textverständnis, das nicht nur strukturierter ist als menschliche Interpretation, sondern sich auch nahtlos in übergeordnete Datenmanagement- und Governance-Strukturen einfügt.
Dazu zählen u. a.:
- Testverfahren für Extraktionsqualität, LLM-Ausgaben und Klassifikationsrobustheit
- Kombinierbare Regeln & Modelle – rule-based und ML, kein Entweder-oder
- Transparente Input/Output-Pfade – mit Versionierung und Vergleichbarkeit
- Feedback- und Korrekturmechanismen für redaktionelle Nachbearbeitung, Annotation oder Qualitätssicherung
Cases
Beispielhafte Anwendungsszenarien
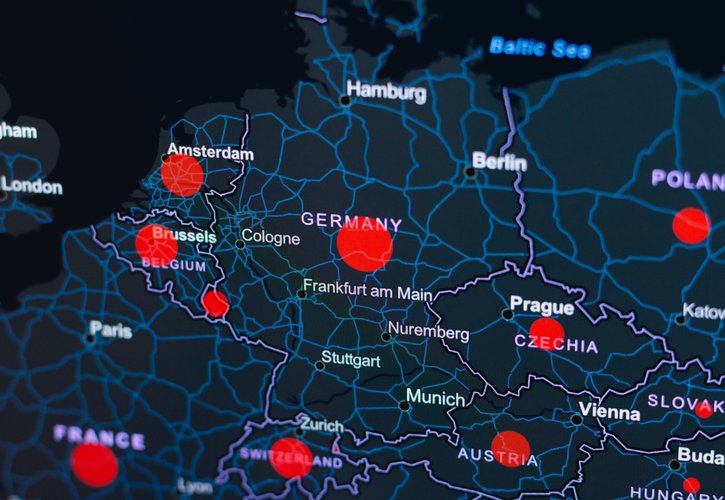
Analyse großer Textsammlungen (z. B. Fachliteratur, Social Media, Reports)

Automatisierte Annotation von Forschungsdaten mit semantischen Labels
Vorverarbeitung von Inhalten für Retrieval-, RAG- oder LLM-gestützte Systeme
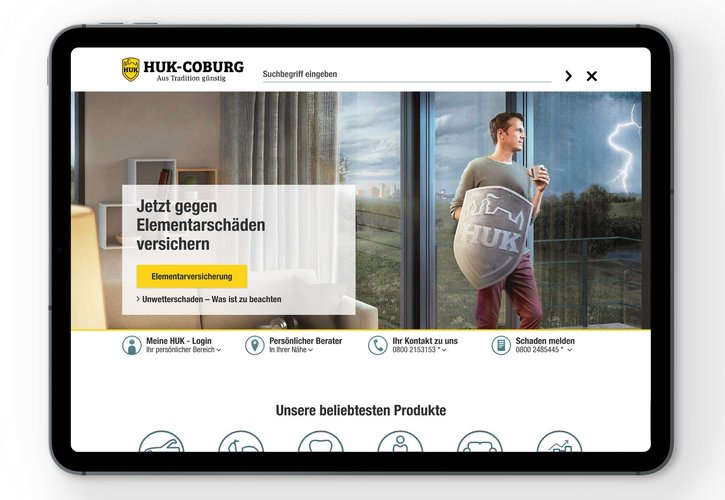
Klassifikation juristischer Dokumente nach Inhalt, Zuständigkeit oder Relevanz
Unsere Technologien
Erfolgsgeschichten









Sprechen Sie uns an
Textverständnis ist kein Modellproblem – es ist ein Systemproblem. ontolux entwickelt Lösungen, die unstrukturierte Inhalte in strukturierte Informationen übersetzen – reproduzierbar, überprüfbar und auf konkrete Anwendungsbedarfe zugeschnitten.

*Ihre Daten werden vertraulich behandelt und nicht an Dritte weitergegeben. Lesen Sie dazu mehr in unserer Datenschutzerklärung.