
Angebot
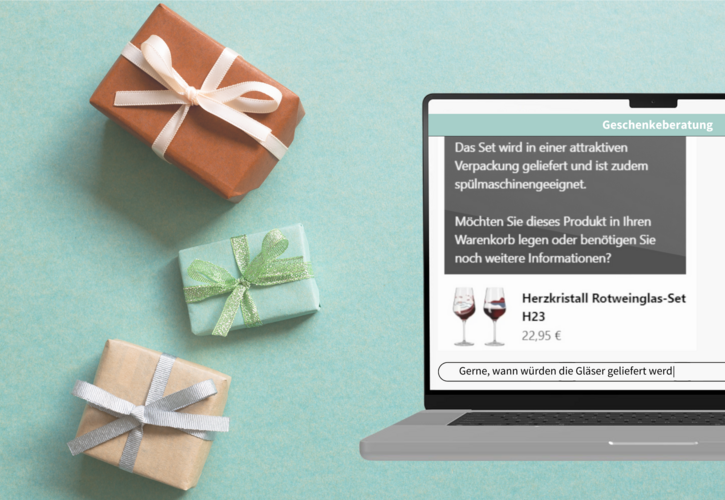
Chat mit eigenen Daten
Natursprachlichen Zugriff auf eigene Inhalte – nachvollziehbar, datensouverän und domänenspezifisch.
Wenn die klassische Suche nicht ausreicht
Viele Organisationen verfügen über umfangreiche Textbestände: Richtlinien, Gutachten, Berichte, Protokolle, technische Dokumentationen oder Fachartikel. Dieses Wissen ist wertvoll – aber oft schwer zugänglich. Klassische Suchfunktionen liefern unpräzise Ergebnisse, erfordern Vorwissen und erzeugen zusätzlichen Rechercheaufwand. Gleichzeitig ist der Einsatz externer Tools wie ChatGPT problematisch – sei es aus Datenschutzgründen oder wegen mangelnder Kontrolle über die Datenbasis.
ontolux entwickelt Systeme, mit denen sich natürlichsprachliche Fragen direkt gegen eigene Inhalte richten lassen. Dabei bleibt die Datenhoheit gewahrt, die Quellen sind nachvollziehbar, und der Zugriff ist so gestaltet, dass er für Fachanwender:innen wie auch für neue Produktideen nutzbar ist.

Herausforderung & Bedarf
Ob für interne Nutzung, externe Wissensportale oder datengetriebene Dienstleistungen: Wer auf eigene Inhalte zugreifen will, braucht mehr als eine Suche. Es geht um kontextuelle Relevanz, zuverlässige Quellen, sprachlich verständliche Antworten – und die Möglichkeit, das System kontrolliert in bestehende oder neue Prozesse zu integrieren. Dafür entwickeln wir Recherche- und Dialogsysteme, die gezielt auf vorhandene Textbestände zugreifen.

Unser Lösungsansatz
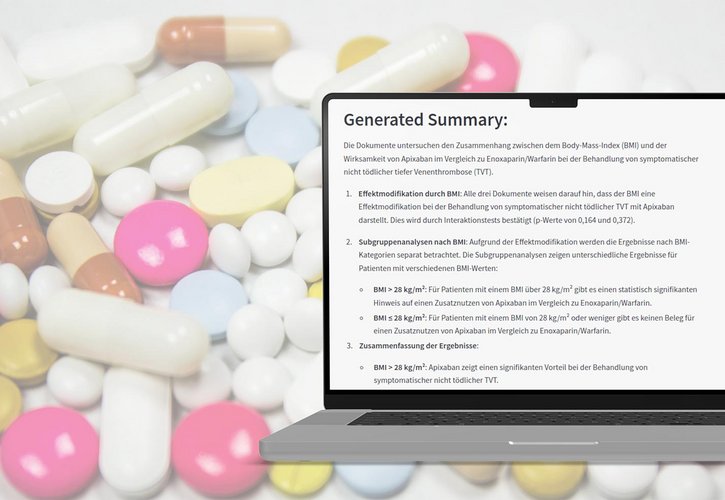
Wissenszugriff über Retrieval-Augmented Generation (RAG)
Grundlage ist eine RAG-Architektur, bei der relevante Textstellen aus einem definierten Korpus semantisch erschlossen und durch ein Sprachmodell zusammengeführt werden – inklusive Quellenverweis.
Dabei geht es nicht um automatisierte Konversation, sondern um eine kontrollierte Form der Frage-Antwort-Interaktion, bei der Nutzer:innen die Herkunft und Grundlage jeder Antwort nachvollziehen können.
Technischer Rahmen & Integration
Unsere Systeme bestehen aus modularen Komponenten:
- Vektorbasierte Indizierung der Inhalte (z. B. Qdrant, Weaviate)
- Retriever-Komponenten mit domänenspezifischem Tuning
- Sprachmodell (API-basiert oder lokal, je nach Anforderung)
- Schnittstellen zur Integration in bestehende Systeme, Portale oder Produkte
Die Systeme sind lauffähig in Cloud-, On-Premise- oder hybriden Infrastrukturen. Der Zugriff kann rollenbasiert, mandantenfähig oder nutzerzentriert gesteuert werden – je nach Geschäftsmodell.





Unsere Kunden

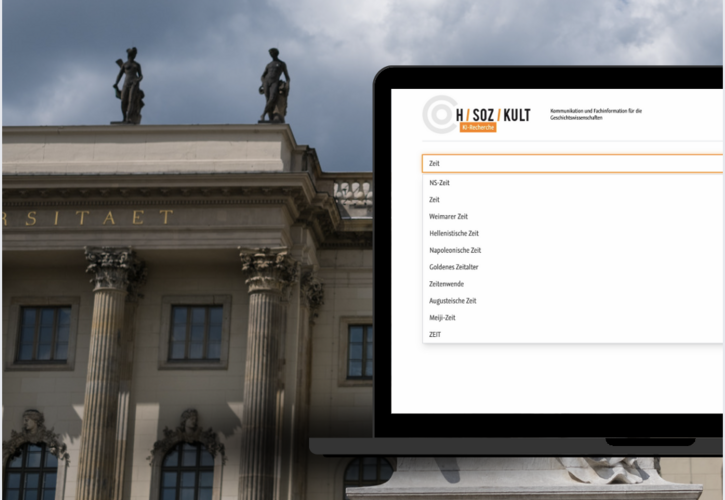



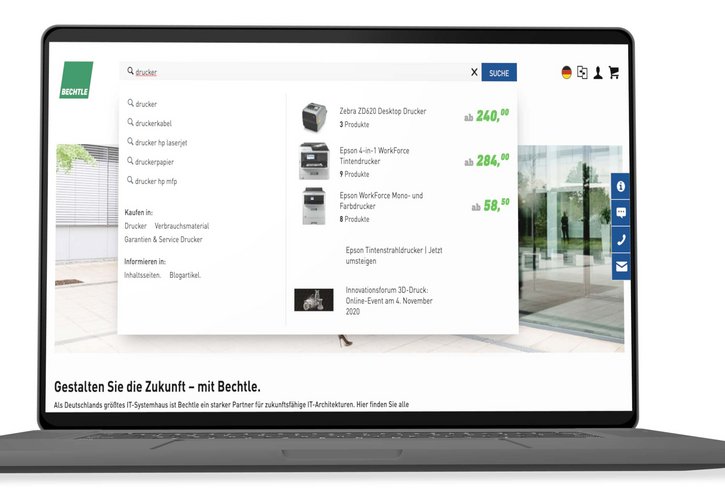





Kontakt
Sprechen Sie mit uns

*Ihre Daten werden vertraulich behandelt und nicht an Dritte weitergegeben. Lesen Sie dazu mehr in unserer Datenschutzerklärung.