
Es wird viel über die Leistung von KI diskutiert, doch oft wird der enorme Energieverbrauch übersehen. Eine Lösung bietet die Modellkomprimierung. Qi Wu stellt im Folgenden verschiedene Methoden zur Ressourceneinsparung vor, um die ökologischen Kosten von Deep Learning Modellen zu senken.
Besonders im Bereich des Natural Language Processing (NLP) steigen die Anforderungen an die Hardware massiv.
Ressourcenverbrauch von KI-Modellen
In einer aktuellen Untersuchung Energy and Policy Considerations for Deep Learning in NLP von Forschern der University of Massachusetts, Amherst, wurde eine Lebenszyklus-Analyse für das Training mehrerer gängiger großer KI-Modelle erstellt. Darin wurden die finanziellen und ökologischen Kosten für das Training von aktuell erfolgreichen, neuronalen Netzwerkmodellen für NLP quantifiziert und approximiert. Wie das folgende Diagramm zeigt, kosten die Trainingsprozesse von einem Transformer-Modell mit 213 Millionen Parametern fünfmal so viel Energie wie die Lebensdauer eines durchschnittlichen US-Autos. Die konkreten Zahlen verdeutlichen das Ausmaß des Problems.
Abgesehen von den Trainingskosten sind auch die Betriebskosten von KI-Modellen nicht zu vernachlässigen. Nehmen wir beispielhaft das gängige GPT 3 von OpenAI als Beispiel. Das Modell benötigt mindestens 350GB VRAM, nur um das Modell zu laden und die Inferenz mit einer angemessenen Geschwindigkeit durchzuführen. Die Hardwarekosten für den Betrieb von GPT-3 würden also zwischen 100.000 und 150.000 US-Dollar liegen, ohne andere Kosten (Strom, Kühlung, Backup usw.) zu berücksichtigen. Eine Alternative ist die Nutzung eines skalierbaren Cloud-Dienstes, dessen jährliche Kosten bei mindestens 87.000 US-Dollar liegen. (Quelle)
Möglichkeiten der Modellkomprimierung und -beschleunigung
Die hohen Trainings- und Betriebskosten für KI-Modelle haben sowohl wirtschaftliche als auch ökologische Folgen. Deshalb wurden bereits eine Vielzahl an Techniken der Modell Komprimierung und -beschleunigung entwickelt, damit hochmoderne Deep Learning-Modelle in energie- und ressourcensparenden Geräten eingesetzt werde können, ohne dass die Modellleistung signifikant sinkt. In den letzten fünf Jahren wurden große Fortschritte erzielt.
Im Allgemeinen werden diese Techniken in die folgenden Kategorien unterteilt: (Cheng et al., 2020)
Parameter Pruning
Quantization
Low-rank Factorization
Transferred/Compact convolutional Filters
Knowledge Distillation
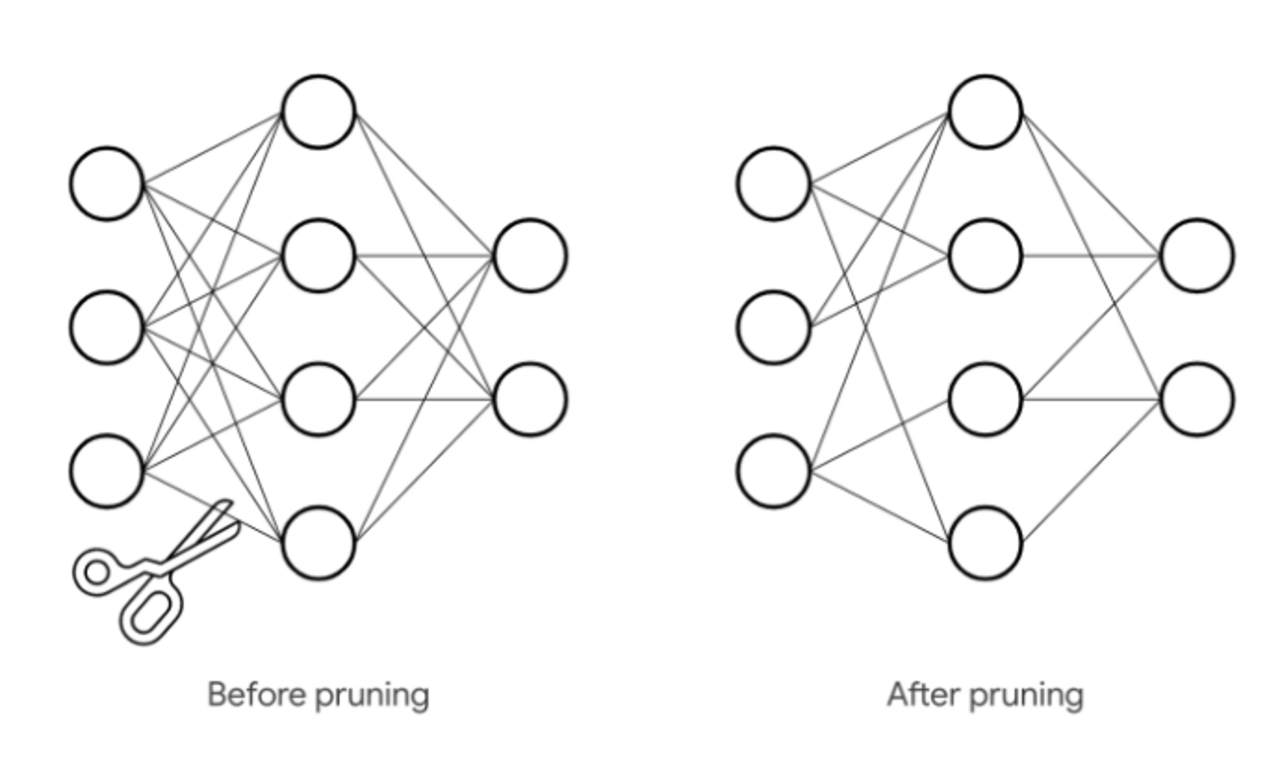
Pruning
Beim Pruning wird versucht, redundante Verbindungen in der Architektur zu entfernen. Dabei werden irrelevante Gewichte, die in der Regel als Gewichte mit kleinem Absolutwert definiert sind, herausgeschnitten. Nach dem Pruning erfolgt ein fine-tuning des Modells, um die Genauigkeit wiederherzustellen. Hierbei können voll verknüpfte Schichten und Convolutional Neural Networks (CNN) in der Regel bis zu 90 % reduziert werden, ohne an Genauigkeit zu verlieren.
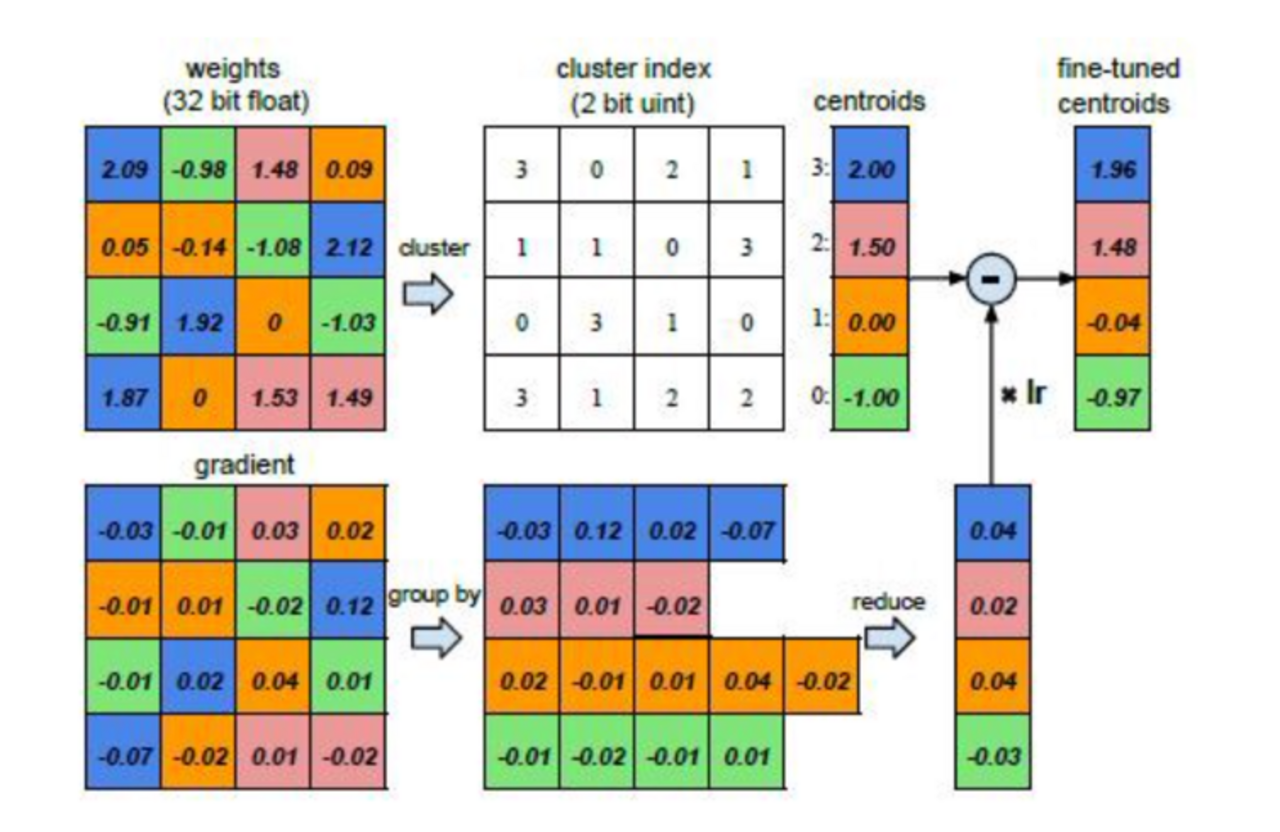
Quantization
Die Quantisierung wird im Sinne einer Optimierung des Speicherverbrauchs der Modellgewichte verwendet, wodurch die Rechenkomplexität verringert wird. Dabei werden, wie in der Abbildung zu sehen, gleichfarbige Gewichte in Clustern zusammengefasst und durch ihren Schwerpunkt dargestellt. Dadurch verringert sich die für die Darstellung dieser Gewichte erforderliche Datenmenge.
In dem unten aufgeführten Beispiel waren zunächst 32 Bits*16 = 512 Bits erforderlich, um sie darzustellen. Nach der Quantisierung werden nur noch 32 Bits *4 + 2 Bits*16 = 160 Bits benötigt, um sie darzustellen. Beim fine-tuning wird der Gradient für alle Gewichte, die zur gleichen Farbe gehören, summiert und dann vom Schwerpunkt abgezogen. Dadurch wird sichergestellt, dass die bei der Quantisierung vorgenommene Clusterbildung beim fine-tuning beibehalten wird.
Low rank factorization
Bei der Low rank factorization oder low-rank approximation werden lineare Algebra-Techniken verwendet, um die Embedding Matrix zu komprimieren. Das kann mithilfe der singular value decomposition (SVD) erreicht werden. Wie auf dem Bild gezeigt, kann eine Matrix M von Größe m⨯n und mit dem Rang r, aus den Matrizen Lkund Rkerzeugt werden. Wenn k = rgilt, kann die Matrix aus der Zerlegung genau rekonstruiert werden. Und wenn k < rgilt, bietet die Zerlegung ein low-rank approximation von M an. Eine Annäherung mit niedrigem Rang ist oft nützlich, wenn die Matrix M Informationen enthält, die ignoriert werden können. Das gilt z. B. bei redundanten Informationen oder irrelevanten Informationen, die für die Lösung eines bestimmten numerischen Problems nicht hilfreich oder möglicherweise sogar nachteilig sind.
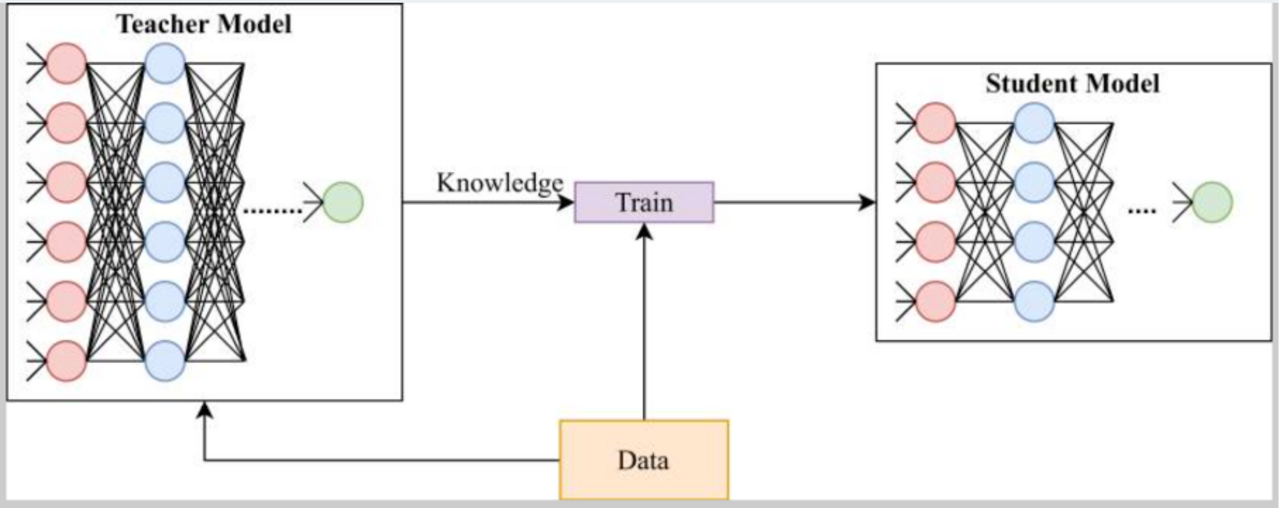
Knowledge Distillation
Während die ersten drei Ansätze versuchen, unwesentliche Parameter eines großen Modells zu identifizieren und zu entfernen, um so eine Modellkomprimierung und -beschleunigung zu erreichen, verfolgt die knowledge distillation die Idee, Wissen von einem größeren Modell auf ein kleineres zu übertragen.
Das kleinere Modell wird als Schülermodell und das große Modell als Lehrermodell bezeichnet. Wie in der unteren Grafik dargestellt, versucht das Schülermodell, das Wissen aus dem Lehrermodell zu destillieren, indem es das Verhalten des Lehrers nachahmt. Mit anderen Worten: Die Verlustfunktion des Schülermodells wird danach berechnet, wie gut der Schüler die Ausgabe des Lehrers nachahmt oder anders ausgedrückt, wie gut das Schülermodell tatsächlich das wahre Label der Trainingsdaten vorhersagt.
Das Standard-Trainingsziel besteht beim supervised learning in der Minimierung der Cross entropy zwischen der vorhergesagten Verteilung des Modells und der empirischen one-hot-Verteilung der Trainings Labels. Bei der knowledge distillation achtet das Schülermodell nicht nur auf die Verteilung der wahren Labels der Trainingsdaten, sondern auch auf die gelernte Ausgabeverteilung des Lehrermodells, oder anders ausgedrückt, auf die soft labels der Eingabedaten.
Das Lehrermodell wird benutzt, um die soft lables der Trainingsdaten zu erzeugen und das Schülermodell versucht dieses Wissen zu lernen.
Hinton et al. (2015) schlugen eine Vanille-Knowledge Destillation vor, bei der die Logits, also Output, welches ein ML-Klassifizierungsmodell generiert, der dann in der Regel an eine Normalisierungsfunktion weitergegeben wird, eines großen tiefen Modells als Wissen verwendet wird, was als response-based knowledge bezeichnet wird. Die Logits der Schüler werden so trainiert, dass sie mit denen des Lehrers durch Soft-Targets übereinstimmen.
Neben dem response based knowledge gibt es auch feature-based knowledge, bei dem die Ausgabe von Zwischenschichten, d. h. feature maps, als Wissen verwendet wird, um das Training des Schülermodells zu überwachen. Bei relation-based knowledge, werden die Beziehungen zwischen verschiedenen Schichten oder Datenproben weiter untersucht.
Bei den Destillationsverfahren gibt es die offline-, die online- und die self-distillation. Bei den meisten aktuellen Arbeiten handelt es sich um eine Offline-Destillation, bei der das Wissen von einem vortrainierten Lehrermodell auf ein Schülermodell übertragen wird. Bei der Online-Destillation hingegen werden sowohl das Lehrermodell als auch das Schülermodell gleichzeitig aktualisiert. Die Self-Distillation ist ein Spezialfall der Online-Destillation, bei der dieselben Netze für das Lehrermodell und das Schülermodell verwendet werden.
Es gibt viele weitere Techniken zur Verbesserung der Destillation-Leistung, wie z. B. die multi-teacher distillation, bei der das Wissen von mehreren Lehrern übertragen wird (Yuan et al. 2021); die graph-based distillation, die versucht, die Beziehungen zwischen den Daten mithilfe von Diagrammen zu untersuchen (Ma and Mei. 2019) oder die attention-based distillation, lifelong distillation usw.
Datum: 17.01.2022
Autor

Qi Wu
Qi Wu arbeitet als Machine Learning Engineer bei der Neofonie GmbH. Nach ihrem Masterstudium der Statistik hat sie sich mit maschinellem Lernen im Bereich der Verarbeitung natürlicher Sprache, wie z.B. der Informationsextraktion, beschäftigt.