
In den letzten Jahren haben uns künstliche neuronale Netze für NLP-Anwendungen und Computer Vision erstaunliche Leistungen beschert. Da diese Modelle oft Millionen von Parametern besitzen, stellen wir in diesem Blogbeitrag die bekanntesten neuronalen Netze für NLP hinsichtlich ihrer Leistung, Größe und Energieeffizienz vor.
Bekannte Modelle neuronaler Netze: BERT, RoBERTa und XLNet
Der Einsatz von neuronalen Netzen im Bereich des NLP hat sich seit 2000 kontinuierlich weiterentwickelt. 2017 veröffentlichte Google „Attention is all you need„ und revolutionierte die neuronale NLP-Gemeinschaft. Bis dato waren die erfolgreichsten Modellarchitekturen in diesem Bereich RNN- (Recurrent Neural Network) oder CNN- (Convulutional Neural Network). Um Sequenz-zu-Sequenz-Aufgaben zu lösen, schlug Google eine neuartige Architektur vor, die vollständig auf einem Attention Mechanism unter Verwendung eines sogenannten Transformers basiert. Der Attention Mechanismus in ANN ist so konzipiert, dass die wichtigen Teile der Eingabesequenz hervorgehoben und der Rest ausgeblendet werden. RNNs oder CNNs wurden vollständig abgelöst. Seitdem basieren die meisten erfolgreichsten NLP-Modelle auf einer Transformer-Architektur, von denen wir im Folgenden einige vorstellen wollen.
BERT (Bidirectional Encoder Representations from Transformers)
BERT wurde 2018 von Google veröffentlicht und wendet das bidirektionale Training von Transformern auf die Sprachmodellierung an. Es wird für zwei Aufgaben trainiert: Masked Language Modeling (MLM) und Next Sentence Prediction (NSP). Bei MLM wird eine zufällige Teilmenge der Token (15 %) im Eingabesatz maskiert, d. h. während des Trainings ausgeblendet. Die Objektive-Funktion von MLM besteht darin, die maskierten Token vorherzusagen.
Bei NSP-Aufgaben werden Beziehungen zwischen Sätzen gelernt, indem vorhergesagt wird, ob der nächste Satz eines Paares der richtige nächste ist. Als Ergebnis des Trainingsprozesses lernt BERT kontextuelle Word Embeddings für Wörter, d.h. typischerweise in Form eines reellwertigen Vektors, der die Bedeutung des Wortes kodiert, sodass die Wörter, die im Vektorraum näher beieinander liegen, voraussichtlich eine ähnliche Bedeutung haben.
Nach dem rechenintensiven Vortraining kann BERT mit weniger Ressourcen auf kleineren Datensätzen nachtrainiert (engl.: fine-tuned) werden, um seine Leistung bei bestimmten Aufgaben zu optimieren.
Leistung und Größe
BERT_large hat 340 Millionen Parameter, und BERT_base hat 110 Millionen
Trainingsdaten 16 GB: BookCorpus und englische Wikipedia-Textdaten
BERT-base wurde 4 Tage lang auf 4 Cloud-TPUs trainiert und BERT-large wurde 4 Tage lang auf 16 TPUs trainiert. Für alle in der Arbeit besprochenen Fine-Tuning Aufgaben benötigt eine GPU nur wenige Stunden.
RoBERTa (Robustly Optimized BERT Pretraining Approach)
RoBERTa wurde von Facebook 2019 veröffentlicht und zielt darauf ab, BERT auf die folgenden 4 Arten zu verbessern:
Entfernt Next Sentence Prediction (NSP) und trainiert nur auf Masked Language Modelling (MLM).
Einführung von dynamic masking, sodass sich das maskierte Token während der Trainingsepochen ändert.
Erhöhte Batch Size: (bezieht sich auf die Anzahl der Trainingsbeispiele, die in einer Iteration verwendet werden), Das Modell trainiert mit 125K Schritten mit einer Batch Size von 2K Sequenzen und 31K Schritten mit einer Batch Size von 8k Sequenzen. (im Vergleich zu BERT: trainiert für 1M Schritte mit einer batch size von 256 Sequenzen).
Erhöhte Menge an Trainingsdaten.
Leistung und Größe
RoBERTa_large hat 355 Millionen Parameter, RoBERTa_base hat 125 Millionen Parameter
Trainingsdaten 160 GB: 16 GB BERT Daten, CommonCrawl News (63 Millionen Artikle, 76 GB), Web Text Korpus (38 GB) und Common Crawl (31 GB).
Es dauerte 1 Tag, das Modell auf 1024 V100 Tesla GPUs zu trainieren
XLNet (Generalized Autoregressive Pretraining for Language)
XLNet wurde von Forschern der Carnegie Mellon University und Google Brain im Jahr 2019 veröffentlicht. Hier wurde BERT in einem neuen Ansatz verbessert. XLNet basiert ebenfalls auf einem Transformer Modell, weist jedoch einige wesentliche Unterschiede zu BERT auf. XLNet greift die Ideen der Auto-encoding (AE) und autoregressive (AR) Sprachmodelle auf und vermeidet dabei deren Einschränkungen.
AE und AR sind zwei unterschiedliche unsupervised Pre-Training Objektive.
Das AE-Sprachmodell zielt darauf ab, die ursprünglichen Daten aus der beschädigten Eingabe unter Verwendung des umgebenden Kontexts zu rekonstruieren. Ein Nachteil von AE-Sprachmodellen ist, dass sie [MASK] im pre-training verwenden, diese Art von künstlichen Symbolen aber in den realen Daten zum Zeitpunkt des fine-tuning nicht vorhanden sind, was zu einer Diskrepanz zwischen pre-training und fine-tuning führt, und auch die Abhängigkeit zwischen den maskierten Wörtern vernachlässigt.
AR-Sprachmodelle verwenden dagegen den Kontext, um das nächste Wort entweder vorwärts oder rückwärts vorherzusagen. Nachteil des AR-Sprachmodelles ist es, dass sie den Vorwärts- und Rückwärtskontext nicht gleichzeitig verwenden können.
BERT ist ein AE Sprachmodell und XLNet ein verallgemeinertes AR Sprachmodell. Die wichtigste Neuerung von XLNet war es, dass es ein neues Ziel namens Permutation Language Modeling (PLM) vorschlug. Dabei wird die Eingabesequenz permutiert, sodass das Modell lernt, Informationen von allen Positionen auf beiden Seiten zu sammeln.
Leistung und Größe
Trainingsdaten 158 GB: 13 GB BERT-Daten und Giga5 (16 GB Text), ClueWeb 2012-B (19 GB) und Common Crawl (110 GB), hohe Qualität (Verwendung von Heuristiken zum aggressiven Herausfiltern kurzer oder minderwertiger Artikel)
XLNet hat eine ähnliche Modellarchitektur wie BERT, daher ähnliche Modellgröße: die Parameteranzahl beträgt sowohl bei BERT als auch bei XLNet 110 Millionen bzw. 340 Millionen
Training auf 512 TPU v3 Chips für 500K Schritte mit Adam weight decay optimizer, linear learning rate und einer batch size von 8192, was etwa 5,5 Tage entspricht
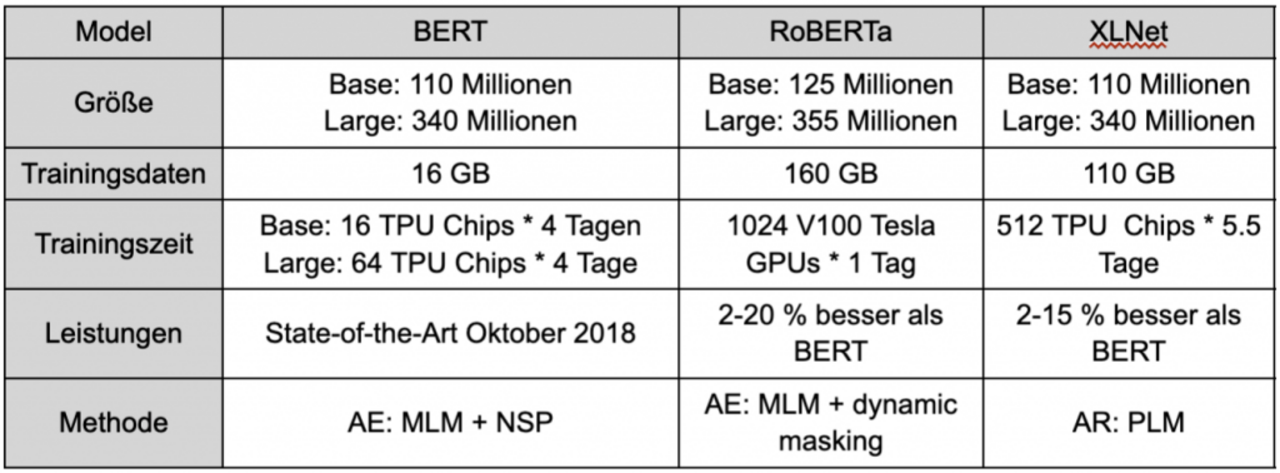
Modellgrößen und Rechenleistung im Überblick
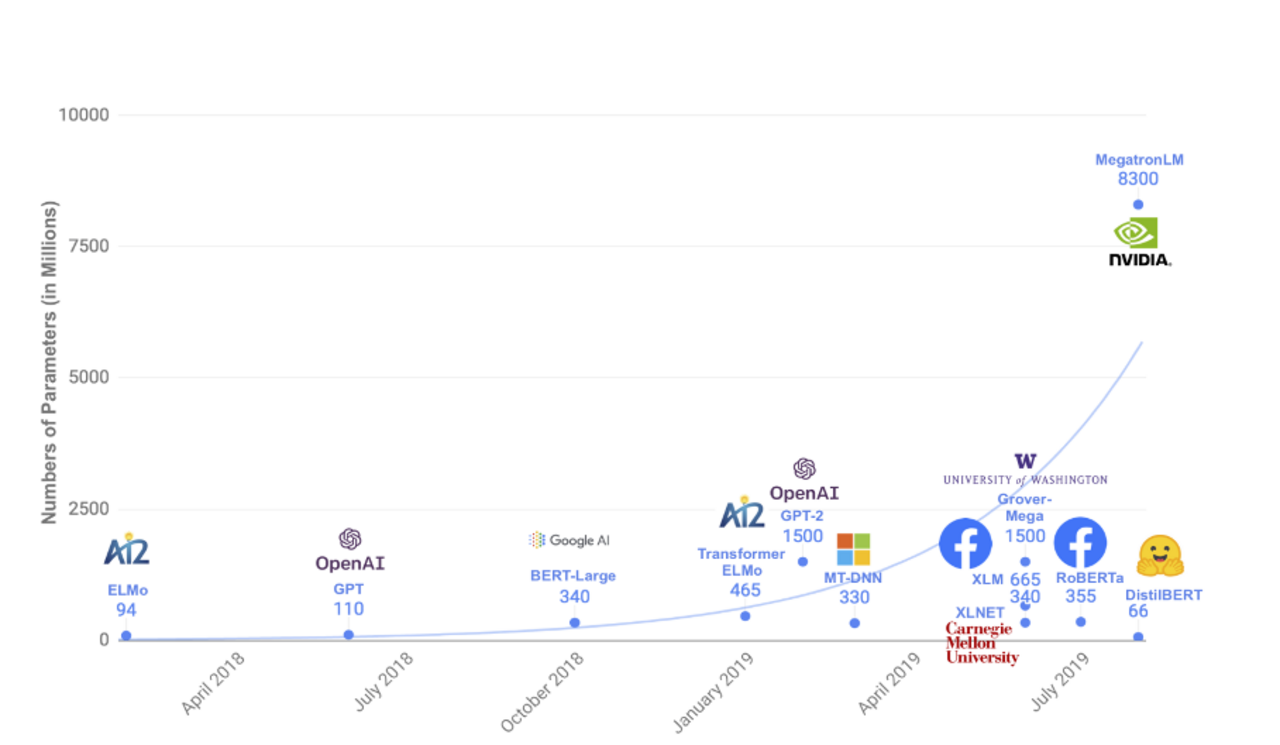
Neben BERT, RoBERTa und XLNet wurden in den letzten Jahren viele andere erfolgreiche Modelle entwickelt, mit wachsender Anzahl von Parametern. Das folgende Diagramm gibts uns einen guten Überblick darüber.
Energieeffizientere KI-Systeme trotz Mega-Größe
Die Verbesserung der Modelleistung wurde bisher hauptsächlich entweder durch eine Vergrößerung des Models, durch mehr Trainingsdaten oder durch die Erhöhung der Trainingsepochen, also der Anzahl der Epochen, wie oft der Lernalgorithmus den gesamten Trainingsdatensatz durcharbeitet, erreicht. Die Rechenkosten für KI-Modelle sind aber so hoch, dass selbst die größten Unternehmen Schwierigkeiten haben, KI-Modelle zu einem lebensfähigen Geschäftsmodell zu machen. Daher versuchen Forscher die Rechenkosten konstant zu halten und gleichzeitig die Modellgröße zu erhöhen.
Switch Transformer
Anfang 2021 stellte Google Brain Team den Switch Transformer, ein KI-Modell für NLP, als Open Source zur Verfügung. Das Modell lässt sich auf bis zu 1,6 Billionen Parameter skalieren. Der Switch Transformer verwendet ein Mixture-of-Experts (MoE)-Paradigma, um mehrere Transformer-Attention Blöcke zu kombinieren. Da nur eine Teilmenge des Modells zur Verarbeitung einer bestimmten Eingabe verwendet wird, kann die Anzahl der Modellparameter bei gleichbleibenden Rechenkosten erhöht werden.
Wu Dao 2.0
Im Juni 2021 wurde auf der Konferenz der Beijing Academy of Artificial Intelligence das Model Wu Dao 2.0 vorgestellt. Es wurde mit FastMoE trainiert, einem System ähnlich dem Mixture-of-Experts (MoE) von Google. Die Idee dahinter ist, verschiedene Modelle innerhalb eines größeren Modells für jede Modalität zu trainieren. Ein Gating-system ermöglicht dem größeren Modell, ein Modelle auszuwählen, welches für die einzelnen Aufgabentypen herangezogen werden sollen. Wu Dao 2.0 ist Chinas erstes super-scale KI-System mit 1,75 Billionen Parametern und ist damit das größte neuronale Netz der Welt. Es wurde anhand von 4,9 Billionen hochwertiger Text- und Bilddaten trainiert und ist in der Lage, zahlreiche Aufgaben wie NLP, die Texterstellung, die Bilderkennung, die Bilderzeugung, die Beschriftung von Bildern und die Erstellung nahezu fotorealistischer Kunstwerke usw. auszuführen.
Fazit
Welche der genannten gängigen NLP-Modelle sinnvoll in der Praxis eingesetzt werden können, muss von Fall zu Fall beurteilt werden. Die jüngsten Entwicklungen zeigen jedoch, dass es bereits vielversprechende Ansätze gibt, die Zahl der Parameter zu erhöhen, während die Anzahl der mathematischen Operationen und damit der einhergehende Energieverbrauch beibehalten wird.
Wir unterstützen Sie dabei, das passende Modell mithilfe unserer KI-Beratung für Ihre Anforderungen auszuwählen.
Bildquelle: Photo by Moritz Kindler on Unsplash
Datum: 07.12.2021
Autor

Qi Wu
Qi Wu arbeitet als Machine Learning Engineer bei der Neofonie GmbH. Nach ihrem Masterstudium der Statistik hat sie sich mit maschinellem Lernen im Bereich der Verarbeitung natürlicher Sprache, wie z.B. der Informationsextraktion, beschäftigt.