
Bereits 2016 machte DeepMind damit Schlagzeilen, professionelle Go-Spieler durch einen Computer im Go geschlagen zu haben. AlphaGo, so der Name des erfolgreichen Programms, macht sich Deep Learning-Algorithmen zunutze. Schon zwei Jahre zuvor erregte Facebook Aufsehen, als es DeepFace veröffentlichte, ein Deep-Learning-basiertes System, das in der Lage war, mit hoher Wahrscheinlichkeit Gesichter zu identifizieren. Sowohl der Erfolg von DeepMind als auch die moralischen Diskussionen um DeepFace haben dazu geführt, dass Deep Learning heute in aller Munde ist, wenn es um Vor- und Nachteile aktueller, zukunftsorientierter Forschung geht. Denn seine Anwendungsgebiete reichen weit über diese beiden Beispiele hinaus.
In diesem Blogbeitrag geben wir einen Überblick über Deep Learning, seine grundsätzliche Funktionsweise, Anwendungen und Beispiele.
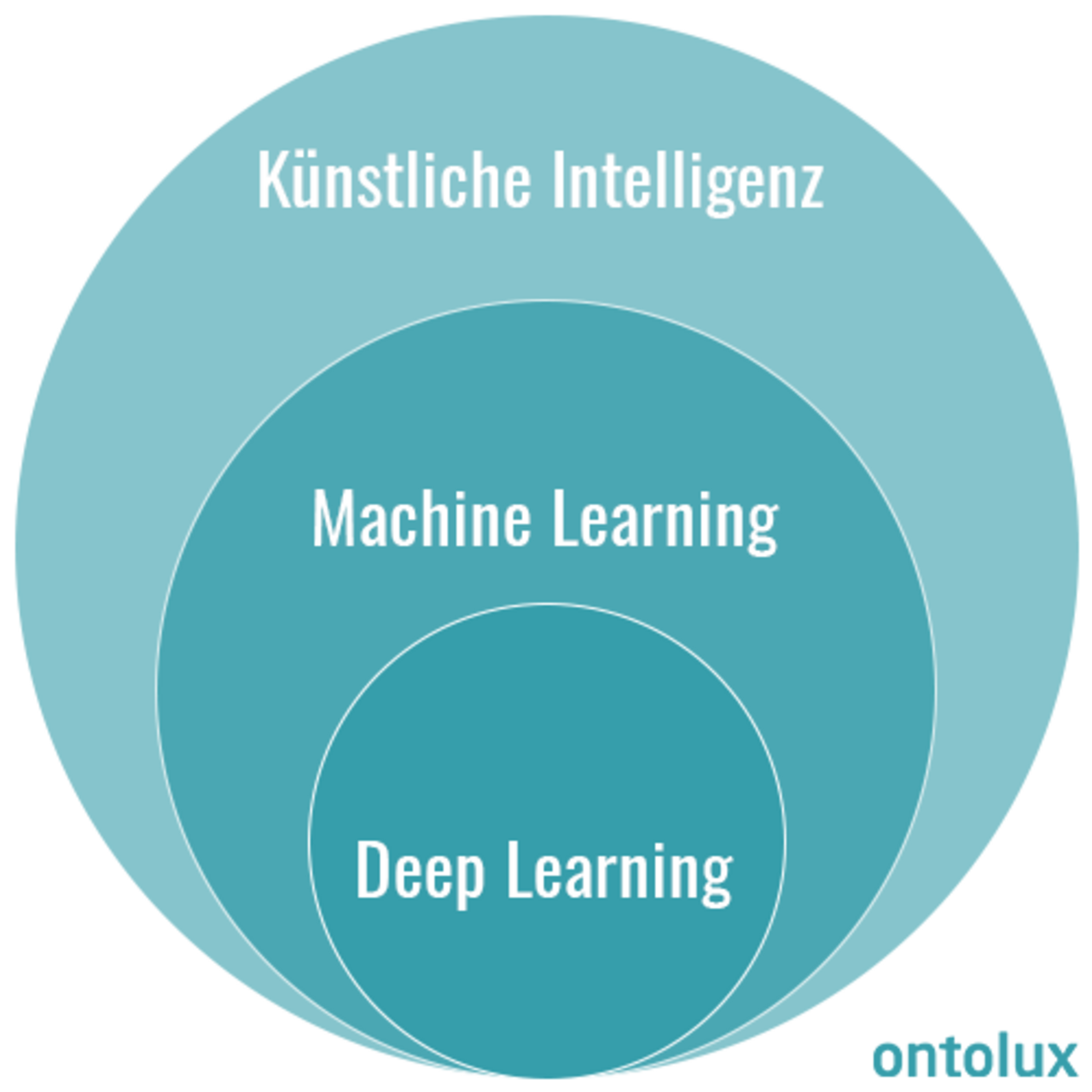
Was versteht man unter Deep Learning, Maschinellem Lernen und Künstlicher Intelligenz?
Deep Learning, Machine Learning und Künstliche Intelligenz sind nach wie vor Buzzwords, die in vielen Kontexten auftauchen, mitunter dabei aber auch durcheinander gebracht werden. Daher hier zunächst eine Einordnung dieser drei Begrifflichkeiten:
Unter Künstlicher Intelligenz (KI) wird grundsätzlich die Fähigkeit eines Systems verstanden, selbstständig Probleme zu erkennen und diese zu lösen. Einen Teilbereich von KI stellt das sogenannte Maschinelle Lernen (Machine Learning) dar, wobei das System lernt, Probleme zu lösen, ohne bspw. auf Regelsysteme von außen zurückzugreifen. Deep Learning wiederum beschreibt einige spezielle Methoden des Maschinellen Lernens, bei denen sogenannte Künstliche Neuronale Netze (Artificial Neural Networks, ANNs) mit einer großen Anzahl versteckter Schichten zur Anwendung kommen.
Was das im Einzelnen heißt, beschreiben wir im folgenden Abschnitt.
Abgrenzung Machine Learning von Deep Learning
Um die Idee hinter Deep Learning verstehen zu können, gehen wir einen Schritt zurück zum Maschinellen Lernen:
Beim Machine Learning prozessiert das System eine (traditionell meist hohe) Datenmenge und findet dabei selbstständig Muster in den Daten, die es für eine Entscheidungsfindung nutzen kann.
So kann beispielsweise eine große Menge an Bildern von Katzen und Hunden dazu genutzt werden, ein System zu trainieren, das Katzen und Hunde auf weiteren Bildern voneinander unterscheiden kann. Dafür werden dem System keine Regeln bereitgestellt, anhand derer die Erkennung stattfindet. Vielmehr lernt das Modell Regeln beziehungsweise statistische Merkmale während des Trainingsprozesses selbst, um die beste Entscheidung treffen zu können.
Unterschiedliche Ebenen des Maschinellen Lernens
Ganz klassisch ist das sogenannte überwachte Lernen (Supervised Learning). Dabei wird dem System ein Datenset für das Training zur Verfügung gestellt, in dem jedem Datenpunkt zugeordnet ist, welches Label für den betreffenden Datenpunkt gilt oder welcher Klasse er angehört.
Beispielsweise also ein Set aus Bildern, bei dem jedem Bild bereits zugeordnet wurde, ob es sich um einen Hund oder eine Katze handelt. Das System lernt dann anhand der Kombination aus Bild und Label.
Unüberwachtes Lernen (Unsupervised Learning)
Beim unüberwachten Lernen (Unsupervised Learning) stehen dem System dagegen nur die Daten ohne ihre Labels oder Klassenzugehörigkeit zur Verfügung. Das System erkennt dann eigenständig Muster in den Daten und findet Gemeinsamkeiten zwischen verschiedenen Datenpunkten.
Teilüberwachtes Lernen (Semi-supervised Learning)
Das teilüberwachte Lernen (Semi-supervised Learning) steht gewissermaßen zwischen diesen beiden Ansätzen. Hier werden dem System sowohl einige Datenpunkte mit als auch Datenpunkte ohne Label oder Klasse als Lerngrundlage bereitgestellt.
Bestärkendes Lernen (Reinforcement Learning)
Neben diesen drei Typen des Lernens kann außerdem auch sogenanntes bestärkendes Lernen (Reinforcement Learning) genutzt werden. Bei dieser Art des Lernens wird dem Modell nach jeder Entscheidung, die es trifft, mitgeteilt, inwiefern es sich dabei um eine gute oder schlechte Entscheidung handelt, und das Modell passt sich entsprechend an – salopp könnte man das also auch als Learning-by-Doing bezeichnen.
Statistische und nicht-statistische Ansätze des maschinellen Lernens
Mathematisch betrachtet basiert traditionelles maschinelles Lernen entweder auf statistischen oder nicht-statistischen Ansätzen. Bei statistischen Verfahren lernt das System, Verteilungen bzw. statistische Wahrscheinlichkeiten für z.B. Klassenzugehörigkeit im Datenset zu erkennen. Hierzu gehören sogenannte Support Vector Machines (SVMs) oder auch die lineare Klassifikation. Im Gegensatz dazu stehen nicht-statistische Ansätze. Das beste Beispiel hierfür sind Entscheidungsbäume (Decision Trees). Nutzt ein Modell einen Entscheidungsbaum, so werden die Daten hierarchisch strukturiert, wobei jede Verästelung (Knoten) eines Baums eine Entscheidung hinsichtlich eines Merkmals darstellt. Insbesondere wenn ein Set aus Datenpunkten verschiedenen Klassen zugeordnet werden soll, kommen Entscheidungsbäume zum Einsatz.
Solch eine Klassifikation von Daten stellt eine häufige Aufgabe für Modelle dar. Entweder sind die Klassen dabei von Beginn an vorgegeben, nämlich beim überwachten Lernen, oder aber das Modell erkennt selbst Klassen in Daten. Je nachdem, welche Datenpunkte ähnlich sind, werden die einzelnen Datenpunkte dann zu Klassen zusammengefasst. Das bezeichnet man als Clustering.
Daten können allerdings nicht nur aufgrund ihrer Ähnlichkeit gruppiert werden. Mit maschinellem Lernen kann ein Modell auch so trainiert werden, dass es anhand von Merkmalen einen spezifischen kontinuierlichen Wert vorhersagen kann (Regression). So können beispielsweise Daten über Märkte und Produktkäufe genutzt werden, damit ein Unternehmen gewinnbringende Produktpreise für die Zukunft festlegen kann.
Künstliche Neuronale Netze und Deep Learning
In Anlehnung an die Funktionsweise des menschlichen Gehirns und die Art, wie wir Menschen lernen, wurde im Zuge der ML-Forschung bereits Mitte des 20. Jahrhunderts die Idee sogenannter Künstlicher Neuronaler Netze (KNN) entwickelt. Mit der heute zur Verfügung stehenden Rechenpower hat sich insbesondere in den letzten 20 Jahren die Forschung an KNN vervielfacht.
Bei einem KNN handelt es sich ähnlich wie im menschlichen Gehirn um Knoten, die miteinander vernetzt sind. Die Vernetzung dieser künstlichen Neuronen in KNN erfolgt in mehreren Schichten (Layern).
Dabei werden grundsätzlich drei Arten dieser Schichten unterschieden: die Input-Schicht, die Output-Schicht und die dazwischen liegenden verborgenen Schichten (Hidden Layers). Sofern nicht nur eine oder wenige verborgene Schichten existieren, sondern eine Vielzahl von ihnen, spricht man von Deep Learning.
Künstliche Neuronale Netze - Input-Schicht
Ausgehend von der Input-Schicht werden Informationen von Knoten zu Knoten über Verbindungen zwischen den Knoten von einer Schicht immer weiter in die nächste Schicht übergeben. Dabei werden die Verbindungen zwischen den Neuronen durch Gewichte (Weights) und jeweils einen sogenannten Bias beeinflusst. Die gewichteten Verbindungen sagen aus, wie stark ein spezifisches Merkmal in den Input-Daten ausgeprägt ist. Übersteigt der gewichtete Output eines Knotens eine bestimmte Schwelle, nennt man den betreffenden Knoten “aktiviert”, und seine Informationen werden an Knoten der darauffolgenden Schicht weitergegeben.
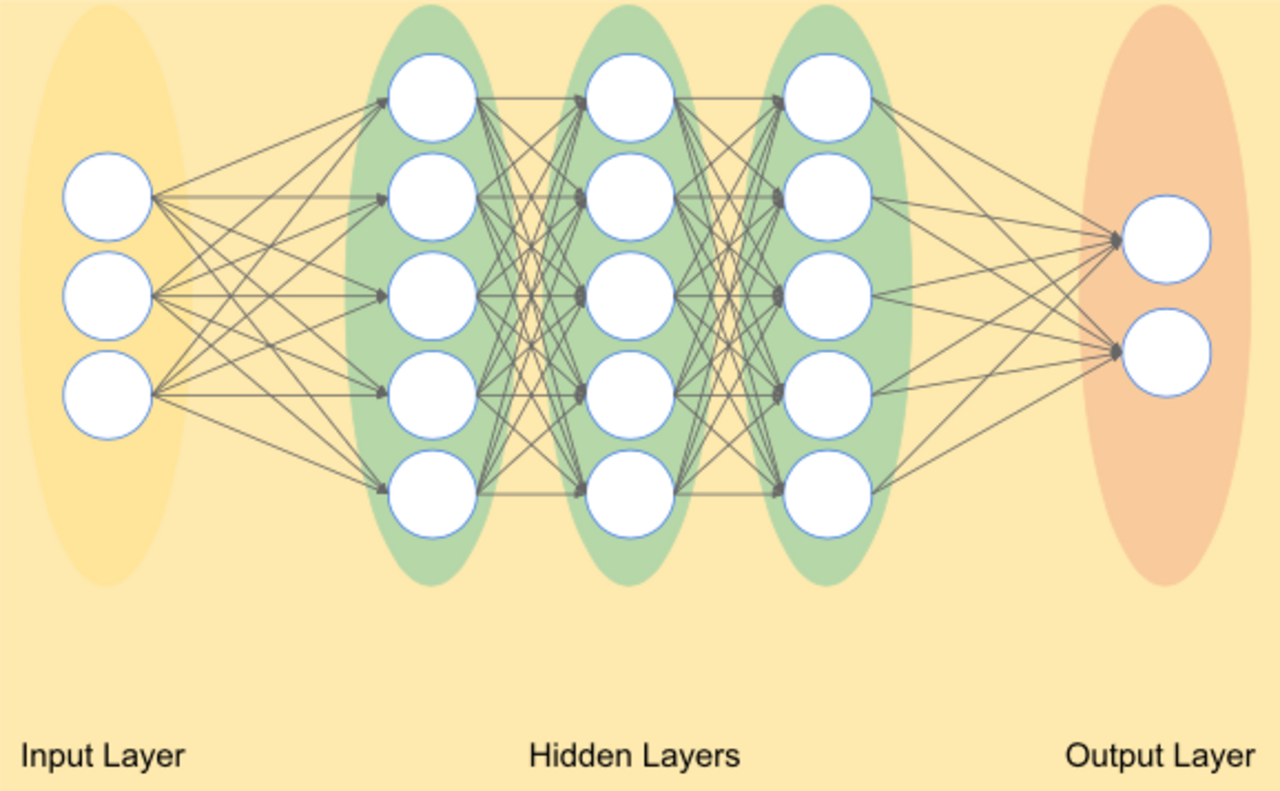
Künstliche Neuronale Netze - Output-Schicht
Letztlich werden die Informationen abschließend gewichtet an die Output-Schicht weitergereicht. Der Output wird dann durch das System mit der Wahrheit abgeglichen und die Höhe des Fehlers berechnet. Ist dies für alle Trainingsbeispiele geschehen, werden die Gewichte zwischen den Knoten erhöht oder verringert, je nachdem, welche Gewichte in welchem Ausmaß am Fehler beteiligt waren (sog. Backpropagation). Einen solchen Zyklus, bei dem mit unveränderten Gewichten für jedes Trainingsbeispiel ein Output generiert wird, anschließend eine Fehlerrechnung stattfindet und anschließend die Gewichte angepasst werden, nennt man Epoche. In der Regel wird ein Neuronales Netz über viele Epochen hinweg trainiert. Das ständige Hinterfragen des eigenen Outputs ermöglicht es dem KNN, große Mengen an Daten zum Lernen effektiv zu nutzen.
Sobald das Training abgeschlossen ist, spricht man von einem fertigen Modell.
Neben der Anzahl von verborgenen Schichten liegt ein entscheidender Unterschied zwischen Deep Learning und anderen Methoden des maschinellen Lernens darin, dass die Merkmale, deren Ausprägung das System herausfinden soll, bei Deep Learning-Algorithmen nicht manuell durch den Menschen, sondern automatisch durch das System extrahiert werden. Welche Merkmale und Muster das System gefunden hat, lässt sich im Nachhinein für den Menschen nicht ohne Weiteres zurückverfolgen.
Methoden des Deep Learnings - Neuronale Netze
Grundsätzlich lassen sich folgende drei Arten von Neuronalen Netzen unterscheiden:
Feed Forward Neural Networks
Convolutional Neural Networks
Recurrent Neural Networks
Feed Forward Neural Networks
Den einfachsten Aufbau eines Neuronalen Netzes besitzen Feed Forward Neural Networks. Hier fließen die Informationen wie oben beschrieben nur in eine Richtung, also vom Input über die Hidden Layers zum Output. Feed Forward Neural Networks waren aufgrund ihrer einfachen Struktur auch die ersten Neuronalen Netze.
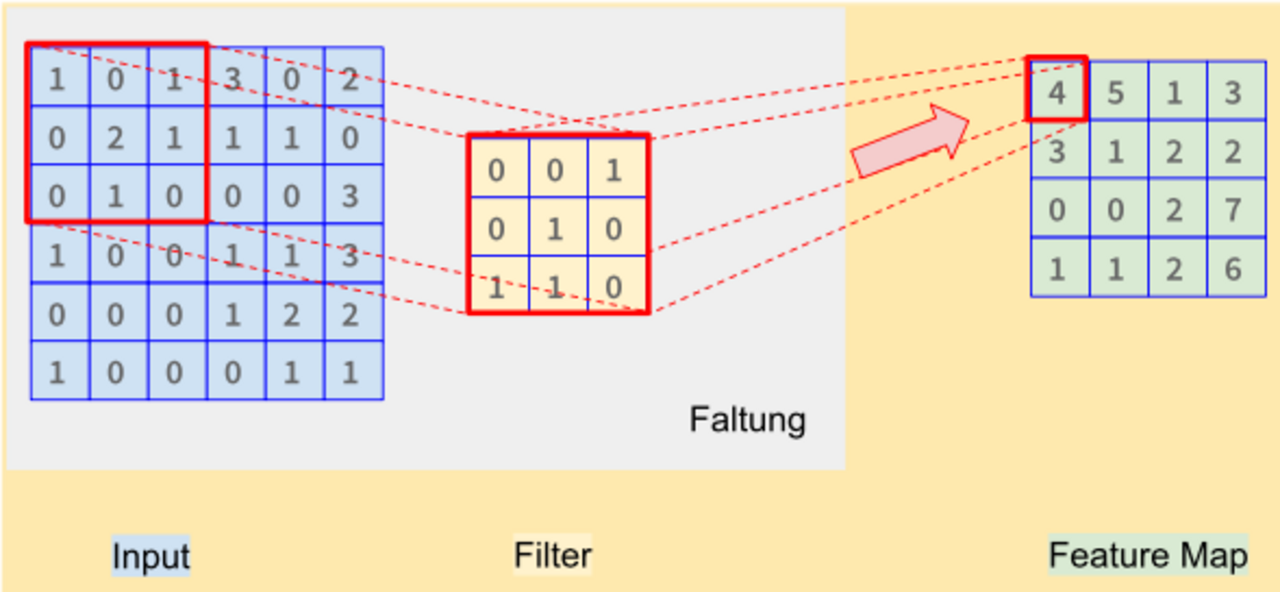
Convolutional Neural Networks
Convolutional Neural Networks, oder zu Deutsch “Faltende Neuronale Netze”, verarbeiten Informationen dagegen nicht rein vorwärtsgerichtet. Vielmehr sind sie dafür designt, gitterartige Strukturen zu verarbeiten. Verdeutlicht werden kann dies gut am Beispiel Bildverarbeitung: bei einem Input-Bild werden für verschiedene Bildausschnitte in jeder der Schichten Filter angewendet. Jede Schicht des Neuronalen Netzes enthält dabei unterschiedliche Filter, die aussagen, ob bestimmte Features in den entsprechenden Bildausschnitten erkannt wurden oder nicht. Man spricht hier von Faltung aufgrund der mathematischen Operation, die dabei ausgeführt wird. Aus dem Input und den Features werden Feature Maps gebildet und die Informationen als Matrix weiterverarbeitet. Die Pooling-Schicht, die jeder Faltung nachgeschaltet ist, führt letztlich dazu, den Informationsfluss auf das Wesentliche zu reduzieren: die Anzahl der Parameter wird dadurch sukzessiv verringert.
Gerade für Klassifikations-Tasks werden Convolutional Neural Networks häufig genutzt, da das Pooling die Anzahl der Features so weit reduzieren kann, dass am Ende der Operationen eine Schicht bleibt, die “Fully-Connected” ist. In solch einer Schicht sind alle Features der Schicht mit genau einem Knoten der Output-Schicht verbunden, also entspricht jeder Knoten genau einer Klasse des Klassifikations-Tasks und wir erhalten für jede Klasse eine Wahrscheinlichkeit, die angibt, wie wahrscheinlich das Input-Bild jeder Klasse angehört Insbesondere bei der Bildverarbeitung kommen Convolutional Neural Networks zum Einsatz.

Recurrent Neural Networks
Im Bereich Textanalyse und NLP werden häufig sogenannte Recurrent Neural Networks verwendet, da diese in der Lage sind, sequentielle Daten zu verarbeiten.
Im Gegensatz zu traditionellen Feed Forward Netzen verwenden RNNs Schleifen, die Informationen aus früheren Inputs für den gegenwärtigen Output nutzen. Bei einer Analyse von Sätzen werden so Wörter, die vorher vorkommen, als sogenannter Hidden State repräsentiert und fließen so in die Analyse der gegenwärtigen Satzstelle mit ein.
RNNs können aufgrund der zu verarbeitenden Informationsmengen schwer zu trainieren sein. Es wurden aber mehrere Techniken entwickelt, um diese Probleme anzugehen. LSTMs (Long Short-Term Memory Units) oder GRUs (Gated Recurrent Units) sind Varianten Rekurrenter Neuronaler Netzwerke, deren Training effizienter ist bei gleichbleibend guten Resultaten.
Trotz guter Performance werden RNNs heutzutage im Bereich NLP aber häufig durch Transformermodelle überholt. Diese unterscheiden sich von RNNs unter anderem darin, dass die Daten nicht sequentiell prozessiert werden, sondern als Ganzes. Dabei wird aber die Position eines Wortes in einem Satz trotzdem mit einbezogen, nämlich über die Gewichtungen.
Einsatzmöglichkeiten von Deep Learning
Um Deep Learning erfolgreich anzuwenden, braucht es Daten. Viele Daten. Im Regelfall gilt hier wirklich der Grundsatz: Je mehr, desto besser. So wie wir Menschen auch umso besser bei der Bewältigung einer Aufgabe werden, je öfter wir sie erledigen, lernen auch Neuronale Netze besser, wenn sie viele Lernerfahrungen sammeln können.
Die Verarbeitung solcher großen Datenmengen mit komplexen mathematischen Operationen führt allerdings dazu, dass Deep Learning häufig auch mit einer hohen Rechenintensität einhergeht, sodass GPUs fast schon Pflicht sind.
Darüber hinaus muss beachtet werden, dass bei Deep-Learning-Anwendungen genauso wie bei anderen Algorithmen des maschinellen Lernens immer die Gefahr von sogenanntem Overfitting besteht. Hierunter versteht man einen Trainingsprozess, bei dem das trainierte Modell zu stark auf die Daten angepasst wurde, mit denen trainiert wurde. Die scheinbar guten Resultate lassen sich auf anderen Daten dann nicht ebenso erzielen.
Anwendungen von Deep Learning
Deep Learning kommt vor allem dann zum Einsatz, wenn Datenmengen von Menschen nicht mehr effektiv bearbeitet werden können, etwa weil es zu teuer oder aufwändig ist, und klassische Programmierung nicht funktioniert, weil die Probleme zu komplex sind. Das betrifft beispielsweise Bilderkennung, Sprachverarbeitung oder autonomes Fahren. Im Bereich NLP werden mithilfe von Deep Learning große Sprachmodelle wie zum Beispiel GPT-3 trainiert. Zur Anwendung kommen diese dann für Tasks wie:
Speech Recognition: Erkennen, in welcher Sprache ein Text verfasst wurde
Machine Translation: Automatische Übersetzung von Texten
Text Classification: Zuordnung von Texten zu verschiedenen Klassen
Sentiment Analysis: Zuordnung, welche Stimmung einem Text innewohnt (z.B. positiv oder negativ)
NER: Named Entity Recognition, also die Erkennung von Entitäten in einem Text
Libraries für Deep Learning Libraries: Keras und PyTorch
Wer selbst mit Deep Learning herumspielen möchte, dem seien folgende Bibliotheken ans Herz gelegt:
Keras beziehungsweise TensorFlow
PyTorch
Keras ist eine Open-Source-Bibliothek, mit der Modelle mithilfe von Deep Learning trainiert werden können. Sie basiert auf Python und wird von Researchern oft verwendet, um neue Ideen schnell ausprobieren zu können. Heutzutage verwendet sie im Hintergrund TensorFlow.
Googles TensorFlow ist eine weitere weit verbreitete Bibliothek für Deep Learning-Anwendungen. Sie ist außerdem gut skalierbar, sodass große, komplexe Modelle basierend auf sehr großen Datensätzen trainiert werden können. Vergleichbare Performance bietet auch PyTorch, das aber ebenso wie TensorFlow weniger leicht intuitiv in der Bedienung als Keras ist.
Weitere Informationen
Weitere Aspekte rund um Maschinelles Lernen und Künstliche Neuronale Netze behandeln wir in unseren Artikeln “Neuronale Netze für NLP-Anwendungen und ihre Rechenleistung” und “Modellkomprimierung: Methoden zur Ressourceneinsparung von KI-Modellen”
|
Datum: 15.03.2023
Kontaktieren Sie uns
Einstiegsangebot für Unternehmen
Entdecken Sie die Möglichkeiten der künstlichen Intelligenz für Ihr Unternehmen. Kontaktieren Sie uns für eine kostenlose Beratung und entdecken Sie die Vorteile von Sprachmodellen, Machine Learning und Suchtechnologien.
Autorin

Cornelia Werk
Als Lead Consultant Search berät Cornelia mit ihrem Team Kunden bei Projekten zu intelligenter Suche auf der Basis von TXTWerk und Solr/Elasticsearch. Sie ist studierte Linguistin und hat bereits als Data Analystin fundierte Erfahrungen in den Bereichen intelligente Datenanalyse, KI und Qualitätsmanagement sammeln können.