
Wie gut funktionieren Sprachmodelle für die deutsche Sprache, wenn die meisten Modelle mit englischen Texten trainiert und bewertet werden? Dazu haben wir wesentliche Modelle getestet und vergleichen sie insbesondere anhand des Perplexitätsgrades, dem Grad der “Überraschtheit” des Modells.
Große Sprachmodelle (Large Language Models, LLMs) haben sich als führende Modelle in der Verarbeitung natürlicher Sprache etabliert und vereinen viele Fähigkeiten, die bislang spezialisierten Modellen vorbehalten waren. Da aktuelle LLMs hauptsächlich mit englischen Textdaten trainiert wurden, ist ihre Fähigkeit zur Verarbeitung von nicht-englischem Text allerdings noch eingeschränkt. Diesem Problem lässt sich theoretisch leicht Abhilfe verschaffen, da auf großen Datensätzen vortrainierte LLMs auf alle Arten von speziellen Domänen und Aufgaben angepasst werden können (mittels “Finetuning” oder “Continuous Pretraining”), einschließlich der Anpassung auf eine ganze Sprache, in diesem Fall Deutsch. Doch wie können wir die Verbesserung eines solchen angepassten Modells messen, wenn doch die meisten gängigen Evaluationsbenchmarks selbst auf Englisch sind?
Dankenswerterweise haben Forscher von LAION kürzlich mithilfe von GPT3.5 einige der wichtigsten LLM-Benchmarks ins Deutsche übersetzt. Sie berichten über die Leistung ihrer eigenen an das Deutsche angepassten Modelle sowie der entsprechenden Basismodelle auf diesen Benchmarks.
Evaluierung: Benchmarks für Sprachmodelle im Deutschen
Im ersten Teil dieses Beitrags testen wir die Leistung verschiedener Modelle, um ein klares Bild der aktuellen Landschaft für Sprachmodelle im Deutschen zu zeichnen.
Die übersetzten und von uns getesteten Benchmarks umfassen:
- ARC Challenge: Bewertet die Genauigkeit der Modelle bei der Beantwortung von Multiple-Choice-Fragen auf Grundschulniveau im Bereich der Naturwissenschaften. Die Fragen sind so gewählt, dass sie besonders schwer für KI-Modelle zu beantworten sind.
- Hellaswag: Bewertet die Fähigkeit des Modells, Sätze kohärent und kontextuell angemessen zu vervollständigen, wodurch der “gesunde Menschenverstand” (common sense) des Modells geprüft wird
- Multilingual Multi-domain Literature Understanding (MMLU): Misst das Wissen des Modells über eine breite Palette von Wissensgebieten.
Stichproben zeigen eine solide Qualität der Übersetzungen; jedoch treten gelegentlich Fehler und unnatürliche Formulierungen auf (Beispiele aus dem übersetzten Hellaswag-Benchmark):
Abwasser aus Haushalten ist nicht alles gleich. Grauwasser bezieht sich auf häusliches Abwasser aus Waschbecken und Badewannen.
Die menschliche Haut fällt in vier Typen: “normal”, ölig, trocken und Kombination.
Wie man scharfen heißen Schokolade macht [title] Legen Sie die Schokolade in eine Tasse und geben Sie einen Spritzer Milch oder Milchersatz hinzu, sodass die Schokolade fast bedeckt ist
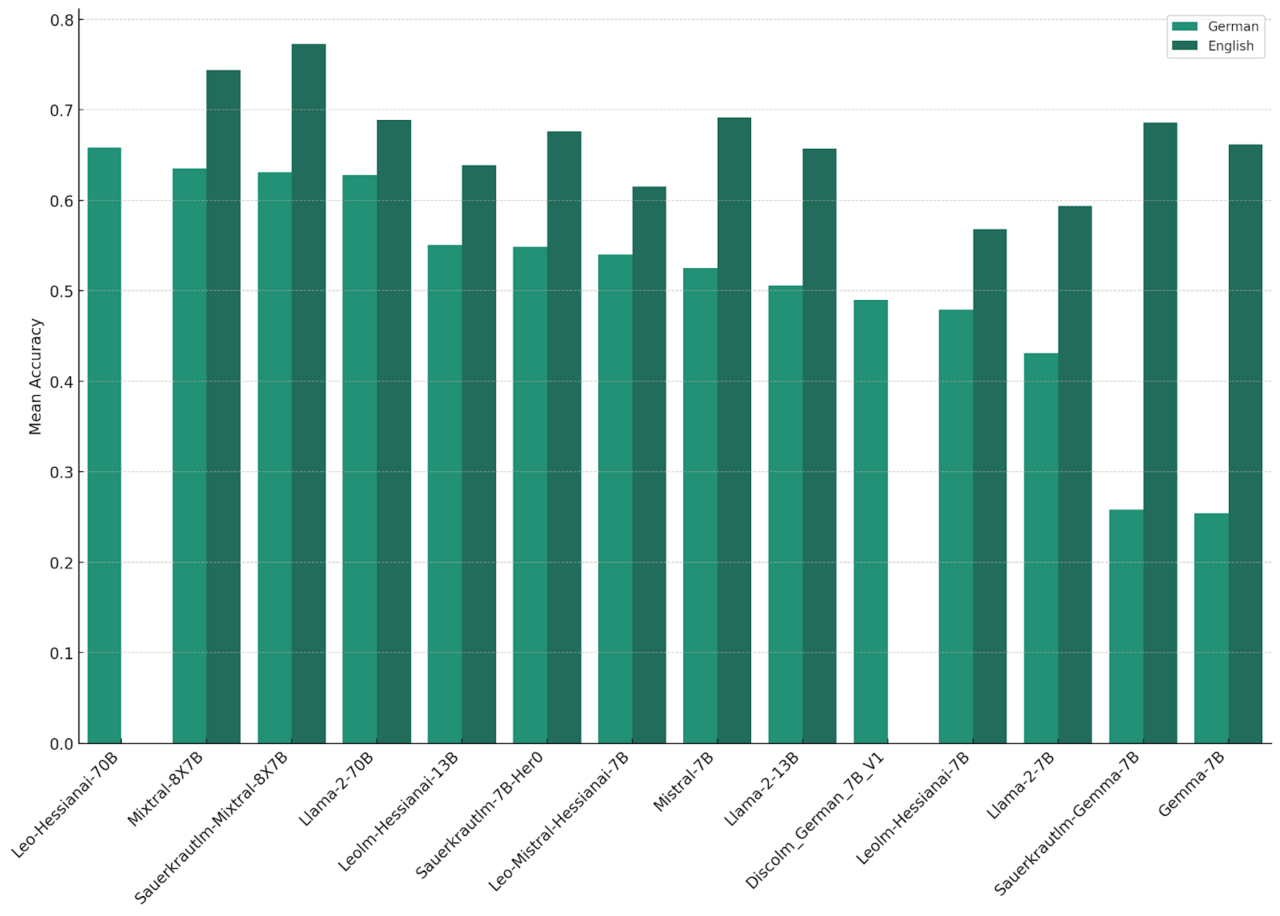
Das folgende Diagramm zeigt die Resultate der auf Deutsch adaptierten Modelle von “LAION (“Leo”)” und “Sauerkraut” und der entsprechenden Basismodelle auf den deutschen und englischen Benchmarks.
Die großen Modelle führen erwartungsgemäß die Liste an. Das feinabgestimmte “Leo-Hessianai-70B-Modell” zeigt eine geringfügig bessere Leistung bei den deutschen Benchmarks als das nicht fein abgestimmte “Mixtral” und das “Llama-2-70B-Modell”. Zwei weitere wichtige Beobachtungen sind zu treffen:
Leistungsunterschiede zwischen Sprachen: Alle Modelle zeigen einen signifikanten Leistungsabfall bei den ins Deutsche übersetzten Benchmarks. Dies lässt sich teilweise durch die unvollkommene Übersetzung erklären, deutet aber auch darauf hin, dass die Übertragung von erworbenem Wissen und Fähigkeiten von einer Sprache in eine andere nur teilweise funktioniert.
Auswirkung der Adaptierung: Das Basis-Modell von “Mixtral” zeigt eine bessere Leistung als sein adaptiertes Pendant. Das könnte an der spezifischen Architektur dieser Modelle liegen: “Mixtral” ist ein Modell vom Typ Mixture of Expert (MoE). Diese sind im Allgemeinen schwerer zu adaptierten, da der Optimierungsprozess komplexer ist und mehr manuelles Tuning von Hyperparametern erfordert. Die anderen angepassten Modelle hingegen zeigen auf den übersetzten Benchmarks eine bessere Leistung als ihr Basis-Modell, wobei die Verbesserung jedoch recht gering ist.
Die übersetzten Benchmarks testen hauptsächlich das akkumulierte Wissen und die Fähigkeit zur Schlussfolgerung. Weitere wichtige, aber nicht erfasste Dimensionen umfassen sprachliche Korrektheit, Flüssigkeit, Qualität des Stils in Wortwahl und Formulierung etc., wie gut also das Modell die Sprache formal beherrscht. Diese Eigenschaften sind vage definiert und schwer automatisiert zu testen. Im zweiten Teil versuchen wir uns trotzdem einer Bewertung anzunähern, indem wir die Perplexität, den Grad der “Überraschtheit” des Modells, auf aktuellen deutschen Nachrichtenartikeln berechnen.
Perplexität
Die Perplexität eines LLM über einen Text ist ein Maß dafür, wie “perplex” oder “überrascht” das LLM vom Inhalt des Textes ist. Perplexität ist der Kehrwert des geometrischen Mittels der Wahrscheinlichkeiten, die das LLM den Token des Textes zuweist, wenn es versucht, das nächste Wort im Dokument vorherzusagen. Die Minimierung der Perplexität entspricht damit der Minimierung der negativen Log-Likelihood, welche das Ziel während dem Pretraining und Finetuning ist. Ein LLM, das kontinuierlich vortrainiert und/oder auf deutschen Text gefinetuned wurde, sollte folglich eine niedrigere durchschnittliche Perplexität für noch unbekannte deutsche Texte aufweisen, da es lernt, die syntaktische Struktur und semantischen Muster, die spezifisch für die deutsche Sprache sind, besser vorherzusehen.
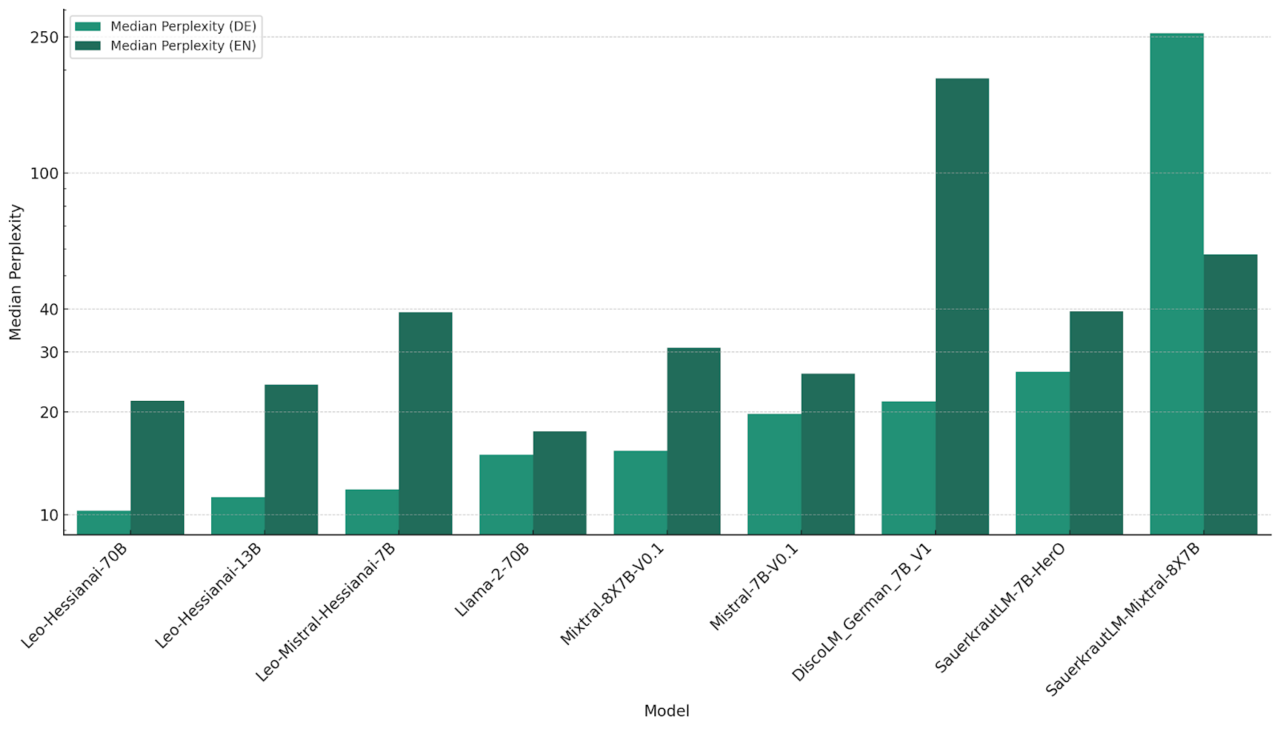
Wir berechnen die Perplexität anhand von 300 aktuellen deutschen und englischen Nachrichtenartikeln, die in einzelne Sätze unterteilt sind (insgesamt 9919 und 9787). Wir nehmen aktuelle Artikel, um sicherzustellen, dass sie während des Trainings noch nicht gesehen werden konnten, und berechnen die Perplexität auf Satzebene, um den Test auf die Sprachkenntnisse im Deutschen zu konzentrieren, anstatt auf angehäuftes Weltwissen, was größere Modelle begünstigen würde. Perplexität ist eine sensible Metrik in dem Sinne, dass sie leicht divergieren kann, wenn ein Satz unter einem Modell eine Wahrscheinlichkeit nahe 0 hat. Daher berechnen wir den Median der Perplexitäten über alle Sätze anstatt des Mittelwerts.
Perplexität hängt offensichtlich stark von der spezifischen Textverteilung ab und nicht nur von der Sprache an sich. Bei den englischen Nachrichtenartikeln zeigen alle Modelle eine höhere Perplexität als bei den deutschen, die englischen Texte scheinen also inhaltlich als unwahrscheinlicher bewertet zu werden. Die Leo-Modelle weisen jedoch, wie erwartet, eine deutlich niedrigere Perplexität bei deutschen Texten auf als die entsprechenden Basismodelle, was auf eine erfolgreiche Adaptierung hindeutet.
Überraschenderweise zeigt das kleine “Leo-Mistral-Modell” vergleichsweise niedrige Perplexität, fast so niedrig wie das große “Leo-Modell” mit zehnmal so vielen Parametern. Die Beherrschung der Sprache an sich scheint also nicht notwendigerweise an eine große Anzahl von Parametern gebunden zu sein. Die Basismodelle “LLama-2-70B”, “Mixtral” und “Mistral” folgen mit durchschnittlichen Perplexitätswerten, ebenso wie die angepassten “Disco-” und “Sauerkraut-Her0-Modelle”.
“Sauerkraut Mixtral” und noch mehr das Basis- und angepasste “Gemma-Modelle” zeigen eine explodierende Perplexität, die um ein oder mehrere Größenordnungen über dem Rest der Modelle liegt. Das weist darauf hin, dass die vom Modell erlernte Wahrscheinlichkeitsverteilung für deutsche Texte sehr “scharf” in dem Sinne ist, dass wenige Token mit sehr hohen und die anderen Token mit sehr niedrigen Wahrscheinlichkeiten bewertet werden. Im “Sauerkraut-Modell” tritt dieses Phänomen aufgrund des Anpassungsprozesses auf, wie der Vergleich zur niedrigeren Perplexität auf Englisch zeigt. Das “Gemma-Modell” scheint generell eine sehr hohe Perplexität zu haben, was durch die Adaptation auf deutsch etwas gelindert wird.
Fazit: Die Zukunft für Sprachmodelle im Deutschen
Insgesamt zeigen unsere Experimente, dass die Anpassung der Sprachmodelle im Deutschen noch sehr unreif ist. Finetuning für den konkreten Anwendungsfall bleibt unerlässlich. Weitere Details zum Vergleich finden Sie auch in unserer Analyse zu Open Source vs. proprietären Sprachmodellen.
Autor: David Reuschenberg, Machine Learning Engineer bei ontolux.
Kontaktieren Sie uns
Einstiegsangebot für Unternehmen
Entdecken Sie die Möglichkeiten der künstlichen Intelligenz für Ihr Unternehmen. Kontaktieren Sie uns für eine kostenlose Beratung und entdecken Sie die Vorteile von Sprachmodellen, Machine Learning und Suchtechnologien.
Autor
