Chatbots spielen für Unternehmen eine immer wichtigere Rolle und können zahlreiche Dialog-Prozesse vereinfachen. Wie Sie in wenigen Schritten selbstlernende Chatbots programmieren und diese kontinuierlich verbessern können, stellen wir in diesem Tutorial vor. Wir nutzen dafür RASA, Elasticsearch und unser NLP-Framework TXTWerk.
Als Dialog-Assistent oder “Chatbot” bezeichnet man Softwaresysteme, die in der Lage sind, eine natürlichsprachige Konversation mit Nutzer*innen zu führen. Dies kann über ein Chatfenster, E-Mail, Messaging-Anwendungen oder sprachgesteuerte Systeme wie Smart Speaker, Telefon-Services o.ä. passieren. Dialog-Assistenten sind eine der vielversprechendsten Technologien zur Mensch-Maschine-Interaktion besonders im Bereich Kundenservice und der Help-Desk Anwendungen. Das zeigt auch die Prognose von Grand View Research Inc., die ein Wachstum des weltweiten Chatbot-Markts bis 2025 um satte 24,3% auf eine Summe von 1,25 Milliarden US-Dollar voraussagen. Es ist nicht überraschend, dass Unternehmen an einer Technologie interessiert sind, die Kunden einen einheitlichen rund-um-die-Uhr-Service bietet und zudem einen Bruchteil der Kosten eines menschbasierten Kundenservices beansprucht.
Durch zahlreiche neue Chatbot-Frameworks und der enormen fortschreitenden Entwicklung im Bereich Machine Learning und NLP mutet die Kommunikation mit den Dialog-Assistenten immer natürlicher an. Die ausgefeiltesten Technologien benötigen allerdings eine Menge exemplarischer Mensch-Maschine-Konversationen, anhand derer sie lernen, möglichst menschenähnlich zu interagieren. Solche Daten stehen nur selten zur Verfügung und es ist zeit- und daher auch kostenintensiv, sie zu sammeln oder zu generieren. Deswegen erfüllen viele Bots nicht ihr volles Potential.
Um das Datenproblem bestehender Chatbot-Frameworks zu lösen, können NLP Frameworks, welche State-of-the-Art-Methoden zur automatisierten Textanalyse in sich vereint, einen wichtigen Beitrag leisten. In diesem Tutorial zeigen wir, wie man einen Chatbot entwickeln kann, der auf für ihn unbekannte Fragen antwortet, indem er passende Antworten in einer Datenbank sucht. Ein solcher Assistent kann mit einigen weiteren Anpassungen aus solchen Interaktionen aktiv lernen und sich mit der Zeit selbst verbessern.
Step 1: Aufbau des Chatbots mithilfe eines NLP-Framworks
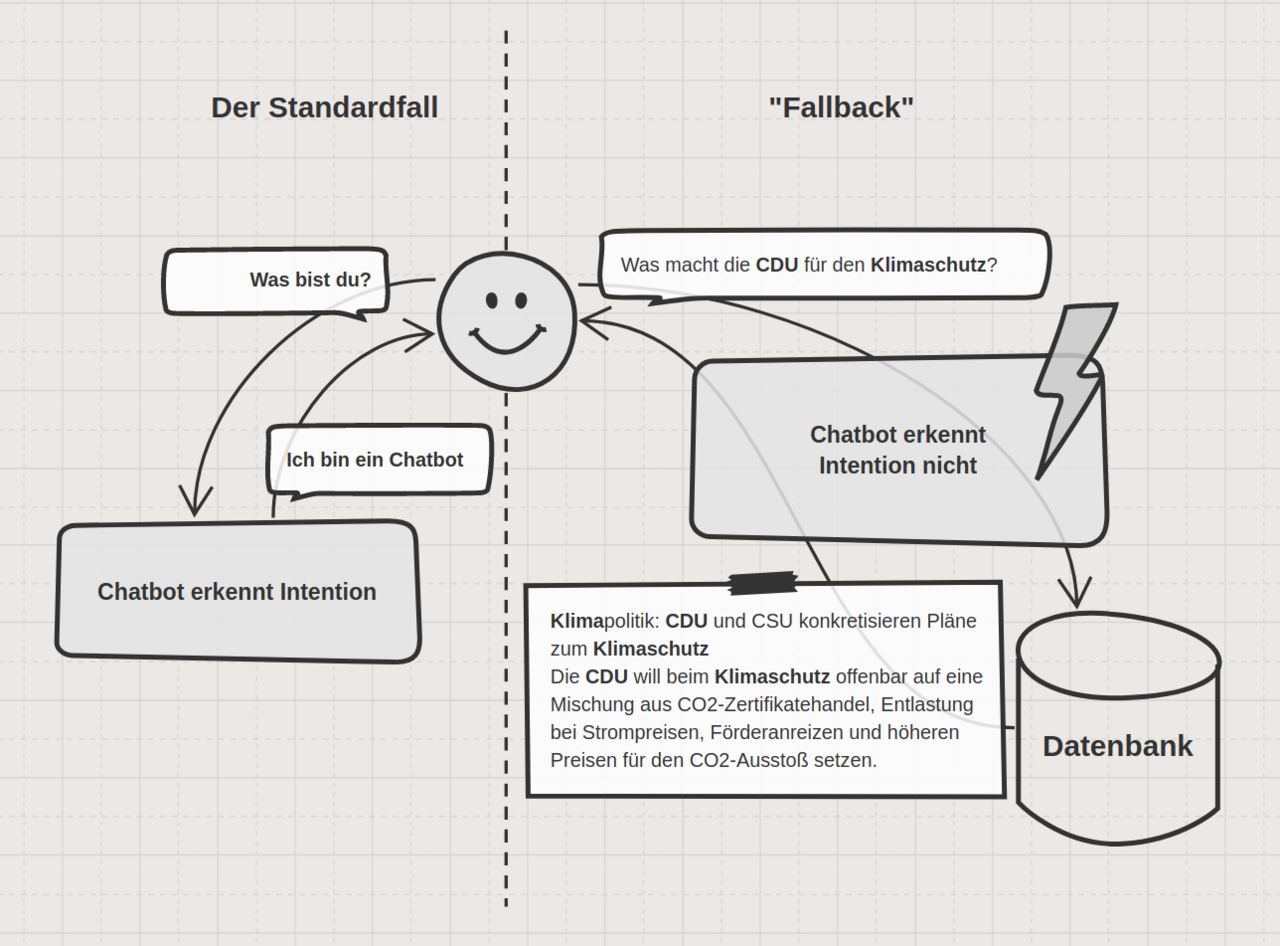
Der Kern eines jeden Chatbots ist die Fähigkeit, die Absicht (den Intent) der Nutzer*innen zu verstehen. Wenn die Anfrage des Benutzers nicht richtig verstanden wird, kann ein Chatbot die richtige Antwort auch nicht geben. Zum Verstehen werden Informationen und relevante Entitäten, die in der Anfrage des Benutzers enthalten sind, extrahiert und die passende Konversation gestartet.

Unser Chatbot wird auf eine (in diesem Fall sehr überschaubare) Reihe von denkbaren Konversationsabläufen trainiert. Machen Nutzer*innen eine Eingabe, mit der der Dialog-Assistent noch nichts anfangen kann, so sendet das System eine Anfrage an einen Suchindex.
Ein solcher Suchindex dient als durchsuchbare Datenstruktur, die jedes abfragbare Dokument und die dazugehörigen Meta-Informationen enthält. Um eine schnelle Datenabfrage für das Chatbot-Framework zu ermöglichen, können gängige Suchmaschinen wie Solr oder Elasticsearch verwendet werden. Einen nützlichen Suchindex aufzubauen ist allerdings nicht trivial. Wenn Nutzer*innen fragen: “Was gibt es Neues in Sachen Klimapolitik?” ist es wenig hilfreich, wenn der Dialog-Assistent sämtliche Ergebnisse zurückgibt, in denen die Worte “Neues”, “Sachen” oder gar “es” vorkommen. In diesem Fall hilft unser NLP-Framework TXTWerk.
Step 1: Die Architektur – Selbstlernende Chatbots programmieren
Mithilfe des Frameworks können die wichtigen Schlagworte, Personen, Orte, Organisationen etc. aus Texten extrahieren werden und verlinkt diese gegebenenfalls mit passenden Wikidata-Instanzen. Die Verlinkung ist für unseren Zweck nicht unbedingt notwendig, allerdings liefert sie direkt einige nützliche Synonyme (“Klimawandel” -> “globale Erwärmung”), wodurch relevante Artikel besser gefunden werden können.
Im folgenden Teil wollen wir mit Hilfe des Chatbot-Frameworks RASA, der Open-Source Suchmaschine Elasticsearch und dem NLP Framework TXTWerk zeigen, wie sich ein Chatbotsystem schnell und einfach erweitern lässt, um auch unbekannte Intents eines Nutzers beantworten zu können.
Step 2: Tools installieren
Code Download | Den Beispielcode für den Chatbot kann man auf github herunterladen. |
TXTWerk-API-Key | Um die TXTWerk API zu benutzen, braucht man einen API-Schlüssel. Für einen kostenlosen Account (bis zu 500 Anfragen/Tag) kann man sich Hier registrieren. |
NewsAPI-Key | Wir besorgen uns die Nachrichtenartikel über die API von newsapi.org. Einen API-Schlüssel bekommt man unter newsapi.org/account. |
RASA-Installation | Als Chatbot Framework verwenden wir RASA, welches sehr gute Ergebnisse in seiner Standardkonfiguration liefert und gleichzeitig sehr flexibel und anpassbar ist. Eine Installationsanleitung findet man hier. |
Elasticsearch-Installation | Als Suchindex verwenden wir Elasticsearch. Die Installationsanleitung gibt es hier. |
Step 3: Suchindex befüllen
Start von Elasticsearch:
## von der Kommandozeile: user:~$ cd path/to/elasticsearch/ user:~/path/to/elasticsearch$ ./bin/elasticsearch
In dem heruntergeladenen “newsbot” Verzeichnis befindet sich ein Python-Script mit dem Namen: news_tagging.py, welches aktuelle Top-Nachrichten abfragt, mit Schlagworten (“tags”) mithilfe von TXTWerk ausstattet und in den Elastic-Suchindex einträgt. Dafür müssen wir oben in dem Script unsere gerade erstellten API-Keys eintragen.
NEWS_API_KEY = "YOUR_NEWS_KEY" TXT_WERK_KEY = "YOUR_TXTWERK_KEY" def index_news(sources) es = Elasticsearch(['localhost']) url="https://newsapi.org/v2/top-headlines?sources={}&apiKey={}&pageSize=100" headlines = requests.get(url.format(sources,NEWS_API_KEY)).json()
In der “index_news”-Funktion wird zuallererst eine Anfrage an die news-API gesendet und Top-Nachrichten verschiedener deutscher Nachrichtenseiten abgerufen.
for article in headlines['articles']:
text = get_article_text(article)
metadata = txt_werk_request(text)
doc = {
'title': article['title'],
## ... article description, content, TXTWerk metadata
}
print(doc['title'], doc['tags'], sep='\n')
## url as _id to avoid duplicates
resp = es.index(es_index, doc_type='_doc', body=doc, id=doc['url'])Titel, Beschreibung und Inhalt der Artikel werden zu je einem Text zusammengefügt und an TXTWerk gesendet. Die daraus resultierenden Schlagworte werden mit den Texten zusammen in den Suchindex eingetragen. Unser Script wird einfach ausgeführt mit:
user:~/path/to/newsbot$ python news_tagging.py
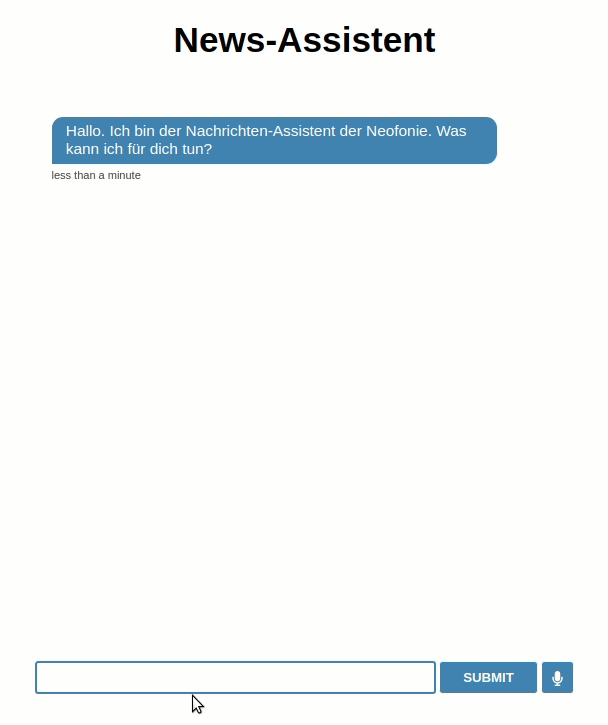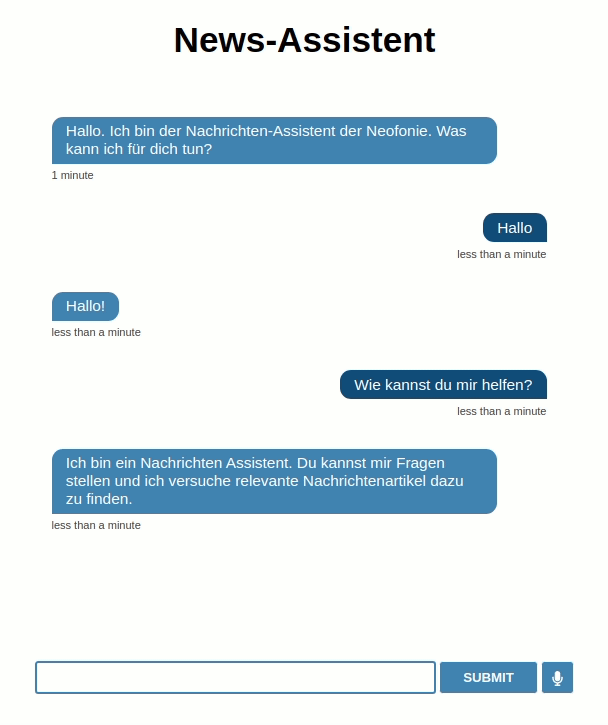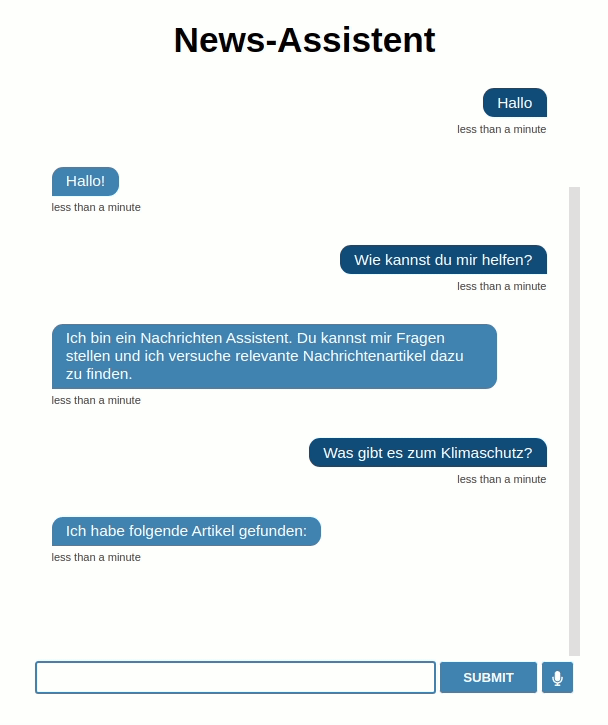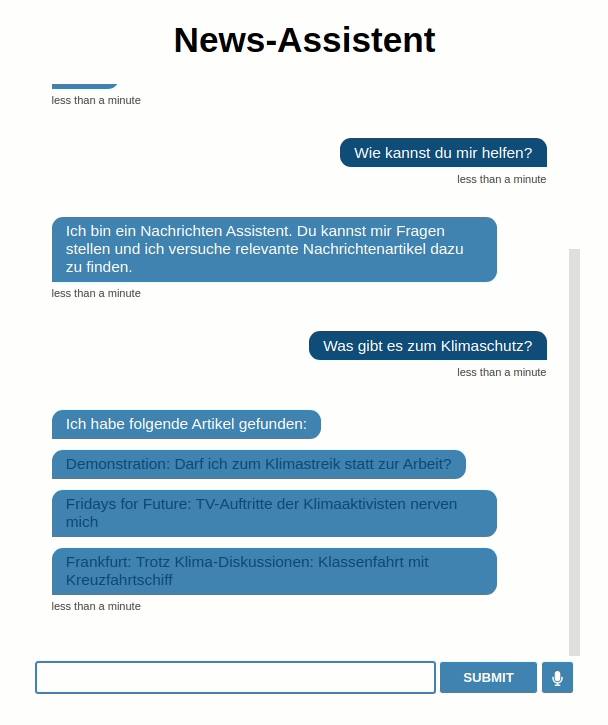
Wir haben Elasticsearch für dieses Projekt ausgewählt, weil man damit ohne viel Konfigurationsaufwand eine erstaunlich fähige Suche aufbauen kann. Wir sind schon jetzt bereit, Anfragen an den Index zu stellen und bekommen passende Nachrichtenartikel zurück (geordnet nach der relativen Häufigkeit an Übereinstimmungen mit unseren gefundenen Schlagwörtern). Beispielsweise kann man eine simple curl-Anfrage, bei der die Beispielfrage „Was gibt es zum Klimaschutz?“ gegen gefundene Schlagworte (“tags”) gematcht wird, wie folgt stellen:
user:~$ curl --request GET \
--url 127.0.0.1:9200/news_articles/_search \
--header 'content-type: application/json' \
--data '{"query": {"match": {"tags": "Was gibt es zum Klimaschutz?"}}}'Top-3 Ergebnisse: "Demonstration: Darf ich zum Klimastreik statt zur Arbeit?", "Fridays for Future: TV-Auftritte der Klimaaktivisten nerven mich", "Frankfurt: Trotz Klima-Diskussionen: Klassenfahrt mit Kreuzfahrtschiff"
Die Ergebnisse hängen von den Nachrichtenartikeln im Index und der Elastic-Konfiguration ab. In unserem Github-Projekt befindet sich eine Datei elastic_requests.http, in der einige hilfreiche Elastic-Befehle aufgelistet sind (alle Dokumente anzeigen, Index duplizieren, Dokumente löschen etc.). Darin ist auch eine beispielhafte Anpassung der Elastic-Konfiguration zu finden, die bewirkt, dass Mehrwort-Tags nur gematcht werden, falls die Anfrage auch mehrere der Schlagworte enthält. “Alternative für Deutschland” wird sonst mit “für” gematcht, was nicht sehr hilfreich ist. Die Konfiguration bietet eine Menge Spielraum für Verbesserungen (Synonyme, Stoppwörter und viele andere Analyseoptionen), doch das würde den Rahmen dieses Tutorials sprengen.
Step 4: Das Setup einrichten und selbstlernende Chatbots programmieren
Das Chatbot-Framework RASA lässt uns mit wenig Aufwand einen vollwertigen Dialog-Assistenten erstellen. In unserem Beispielprojekt befinden sich alle notwendigen Konfigurationsdateien, sodass der Assistent mit zwei simplen Befehlen trainiert und gestartet werden kann:
user:~/path/to/newsbot$ rasa trai user:~/path/to/newsbot$ rasa shell
Der Assistent kann so bereits auf alle (In unserem Fall bisher ganze 2!) vorab trainierten Fragen antworten. Wenn der Assistent die Anfrage nicht einordnen kann, wollen wir als “Fallback Action” mit einer eigens definierten “custom action” reagieren, die in unserem Fall nach passenden Antworten im Elastic-Index sucht. Dafür müssen wir in einer neuen Kommandozeile einen action-server starten:
user:~/path/to/newsbot$ rasa run actions
Dieser Befehl sucht automatisch nach einer Datei “actions.py” in der unsere Fallback-Action definiert ist. In dieser custom-action wird nach Nachrichtenartikeln gesucht, deren Schlagwörter mit der letzten Nachricht der Nutzer*innen übereinstimmen.
def get_elastic_matches(query_text, index="news_articles"):
es = Elasticsearch(['localhost'])
res = es.search(index=index,
body={"query": {"match": {"tags": query_text}}})
if not res or res['hits']['total']==0:
return None
return res['hits']['hits']
## in ActionDefaultFallback(Action) function run(...)
hits = get_elastic_matches(query_text=tracker.latest_message['text'])Falls passende Dokumente im Suchindex gefunden werden, werden die drei passendsten in der Form von Markdown-Verlinkungen ([Text](url)) angezeigt.
## in ActionDefaultFallback(Action) function run(...)
dispatcher.utter_message("Ich habe folgende Artikel gefunden:")
for hit in hits[:3]:
dispatcher.utter_message("[{}]({})".format(
hit['_source']['title'],hit['_source']['url']))Uns steht nun der vollwertige Dialog-Assistent zur Verfügung, der auf unbekannte Fragen selbstständig passende Antworten aus einer Wissensbasis zurückgibt. Wir können über die RASA-Shell das System testen:
Your input -> Hi! Grüß dich! Your input -> Was gibt es zum Klimaschutz? Ich habe folgende Artikel gefunden: Demonstration: Darf ich zum Klimastreik statt zur Arbeit? Fridays for Future: TV-Auftritte der Klimaaktivisten nerven mich Frankfurt: Trotz Klima-Diskussionen: Klassenfahrt mit Kreuzfahrtschiff
RASA bietet ein ausgezeichnetes Tutorial zum Einstieg und eine ausführliche Dokumentation. Im Folgenden werden nichtsdestotrotz die notwendigen Dateien kurz erklärt:
data/nlu.md
Trainingsdaten für RASAs Intent-Erkennung (Das Machine Learning Modul, welches versucht, die Absichten der Nutzer zu erkennen). In unserem Fall handelt es sich vorerst nur um 2 Intents mit folgendem Aufbau:
## intent:help <-Intentname-> - Wie kannst du mir helfen? - Was kann ich dich so alles fragen? <-Beispielanfragen-> - Hilfe - Hilf mir - Was kannst du denn überhaupt?
data/stories.md
Trainingsdaten für RASAs Dialog-Management (Das Modul, das in Abhängigkeit von der bisherigen Unterhaltung steuert, welche Aktion der Assistent als nächstes ausführt). In der Form einer beispielhaften Konversation zwischen Nutzer*in und Assistent.
## greet * greet - utter_greet ## help * help - utter_help
data/domain.yml
Eine Auflistung aller Intents (Nutzer-Anliegen), Actions (Bot-Reaktionen) und Templates für Antworten des Assistenten.
intents: <-Liste Intents-> - greet - help actions: <-Liste Reaktionen-> - utter_greet - utter_help - action_default_fallback <-Fallback action-> templates: utter_help: <-Texte Reaktionen-> - text: "Ich bin ein Nachrichten Assistent. Du kannst mir Fragen stellen und ich versuche relevante Nachrichtenartikel dazu zu finden." utter_greet: - text: "Hallo!" <-multiple Antwortmöglichkeiten-> - text: "Hi" <-(zufällig gewählt)-> - text: "Grüß dich!" - text: "Guten Tag!"
config.yml
Konfigurationen für RASAs Intent-Erkennung und Dialog-Management.
# Configuration for Rasa Core. policies: - name: KerasPolicy epochs: 100 max_history: 2 - name: FallbackPolic nlu_threshold: 0.95 # name der fallback action fallback_action_name: 'action_default_fallback' - name: MemoizationPolicy max_history: 2 # Configuration for Rasa NLU. language: "de" pipeline: "tensorflow_embedding"
Wir benutzen größtenteils Standardeinstellungen. Die “FallbackPolicy” definiert, dass eine “custom action” ausgeführt werden soll, wenn kein Intent mit ausreichender Sicherheit erkannt wurde. Wir haben für die Intent-Erkennung einen hohen Threshold gewählt (0.95), denn in unserem Szenario wollen wir, dass der Chatbot nur mit einer vorgefertigten Antwort reagiert, wenn er sich sehr sicher über das Anliegen der Nutzer*innen ist. Wird dieser Threshold nicht erreicht, sucht der Dialog-Assistent eine passende Antwort im Elastic-Index.

Step 5: Ausblick: Professionell selbstlernende Chatbots programmieren
Wir haben mit wenig Aufwand einen Assistenten gebaut, der auf Fragen antworten kann, die er nie zuvor gesehen hat, indem er nach passenden Antworten in einer Datenbank sucht. Wozu sollte man überhaupt ein kompliziertes Chatbot-Framework benutzen, wenn man Nutzeranfragen einfach in einem Suchindex nachschlagen kann? Moderne Chatbot-Frameworks wie RASA verwenden ausgefeilte Deep-Learning-Methoden zur Intent-Erkennung, um subtile Unterschiede in Nutzer-Eingaben zu differenzieren und gewonnenen Kontext aus der bisherigen Unterhaltung in die Dialogführung zu integrieren. Beispielsweise würden zwei Nutzer*innen auf ihre Anfragen “Wie war das Wetter in den letzten Tagen?” und “Wie hat sich das Wetter in den letzten Jahren entwickelt?” wohl unterschiedliche Antworten erwarten. Während die erste Frage auf einen aktuellen Wetterbericht abzielt, sucht die zweite eher nach Informationen zum Klimawandel. Doch die Fragen sehen sehr ähnlich aus und die meisten potentiellen Schlagworte sind die gleichen. Ausgefeilte Methoden der Intent-Erkennung sind besser aufgestellt, um solch unterschwellige Nuancen zu erkennen, benötigen dafür allerdings auch umfangreichere Trainingsdaten, in denen möglichst viele potentielle Nutzeranfragen den dazugehörigen Reaktionen des Assistenten zugeordnet sind.
Solche Trainingsdaten sind aufwändig zu beschaffen. Die Neofonie hat ein Assistenzsystem auf Basis des NLP Frameworks TXTWerk entwickelt, welches Chatbots befähigt aus Konversationen selbstständig zu lernen. Nehmen wir den Fall der zwei Nutzer*innen mit ihren Wetter/Klima-bezogenen Fragen: Auch wenn unser Bot die exakte Absicht nicht versteht, antwortet er mit einer Auswahl potentiell hilfreicher Einträge aus seiner Datenbank. Ist eine passende Antwort dabei, können die Nutzer*innen sie selbstständig auswählen. Der Bot lernt daraus, welche Antworten in welcher Art von Konversation hilfreich sind. Zudem kann Nutzer-Feedback erfragt werden. Führen ähnliche Fragen zuverlässig zu einer bestimmten Art von Antwort, können sie den Trainingsdaten hinzugefügt werden, wodurch der Chatbot lernt, direkt mit relevanten Ergebnissen zu antworten.
Der hier beschrieben Chatbot bietet einen kleinen Ausblick, wie einfach sich mit innovativen Werkzeugen wie RASA ein recht komplexes Chatbotsystem bauen lässt, doch das Potential dieser Technologie wird selten ausgeschöpft. Erst durch die Integration von Sprachanalyse und -verständnis (z.B. durch Frameworks wie TXTWerk) werden intuitivere, intelligentere Systeme möglich.
Datum: 27.01.2021
Kontaktieren Sie uns
Einstiegsangebot für Unternehmen
Zusammenfassend lässt sich sagen: Wer heute selbstlernende Chatbots programmieren möchte, findet mit Open-Source-Tools einen schnellen Einstieg.
Entdecken Sie die Möglichkeiten der künstlichen Intelligenz für Ihr Unternehmen. Kontaktieren Sie uns für eine kostenlose Beratung und entdecken Sie die Vorteile von Sprachmodellen, Machine Learning und Suchtechnologien.
Autorin

Cornelia Werk
Als Lead Consultant Search berät Cornelia mit ihrem Team Kunden bei Projekten zu intelligenter Suche auf der Basis von TXTWerk und Solr/Elasticsearch. Sie ist studierte Linguistin und hat bereits als Data Analystin fundierte Erfahrungen in den Bereichen intelligente Datenanalyse, KI und Qualitätsmanagement sammeln können.