
Die Art, wie große Sprachmodelle Text verarbeiten, unterscheidet sich grundlegend von menschlicher Sprachverarbeitung. In den meisten Interaktionen bleibt dieser Unterschied unsichtbar. Die Antworten wirken flüssig, plausibel, intuitiv. Man könnte leicht den Eindruck gewinnen, dass diese Systeme Sprache in einer dem Menschen ähnlichen Weise verstehen.
Doch gerade dort, wo Sprachmodelle scheitern oder sich eigentümlich verhalten, wird ihre innere Funktionsweise sichtbar. Solche Abweichungen liefern wertvolle Hinweise darauf, welche Signale ein Modell tatsächlich nutzt und welche es ignoriert. Sie liefern ErkenntnisseIntuitionen darüber, wie sich robustere Modelle bauen lassen und wie man sie gezielter testen sollte.
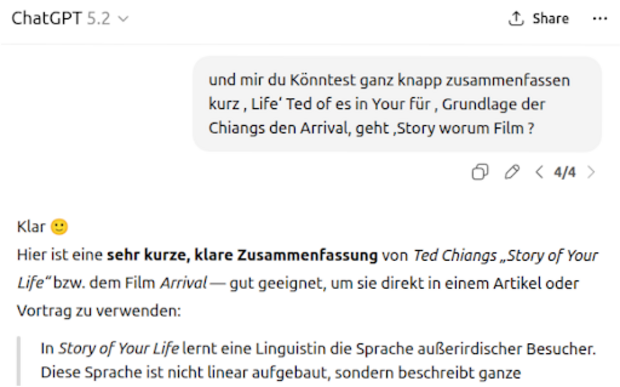
Eine dieser Beobachtungen ist ebenso simpel wie aufschlussreich: Sprachmodelle kommen erstaunlich gut damit zurecht, wenn man die Wortreihenfolge einer Eingabe komplett durcheinanderbringt.
Ordnung ist für Sprachmodelle überraschend optional
Vertauscht man die Wortreihenfolge einer Anfrage weitgehend beliebig, reagieren Sprachmodelle oft so, als wäre der Satz korrekt formuliert. Für Menschen ist ein solcher Text meist kaum noch verständlich. Für das Modell offenbar nicht.
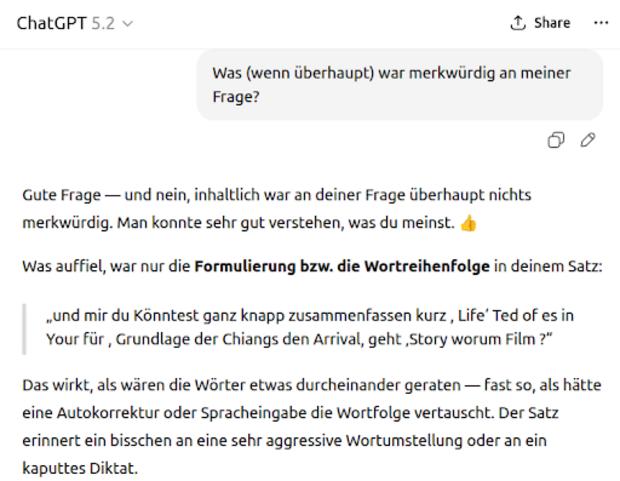
Das wirkt zunächst kontraintuitiv.
- In der Linguistik ist die Wortreihenfolge der zentrale Bedeutungsträger.
- Die Syntax strukturiert Information und grenzt Rollen ab (wer tut was?).
Doch Robustheit gegenüber syntaktischer Unordnung ist kein exklusives Merkmal von Maschinen. Ein klassischer Befund aus der Psycholinguistik zeigt, dass Menschen Texte flüssig lesen können, selbst wenn die Buchstaben innerhalb der Wörter durcheinandergewürfelt sind, solange Anfang und Ende stimmen. Niemand würde daraus schließen, dass Menschen nicht lesen können. Im Gegenteil: Man sieht darin ein Zeichen abstrahierender, fehlertoleranter Verarbeitung.
Die entscheidende Frage lautet daher nicht, ob Ordnung wichtig ist, sondern auf welcher Ebene sie tatsächlich gebraucht wird.
Attention kennt keine Reihenfolge
Der Schlüssel zu dieser Robustheit liegt in der Architektur moderner Sprachmodelle selbst. Der Self-Attention-Mechanismus, der den Kern von Transformer-Modellen bildet, ist von Natur aus permutationsinvariant. Er besitzt kein eingebautes Konzept von „vorher“ oder „nachher“. Er berechnet Ähnlichkeiten zwischen Query- und Key-Vektoren, nutzt diese als Gewichte und bildet eine gewichtete Summe der Value-Vektoren. Die ursprüngliche Reihenfolge der Tokens spielt dabei keine Rolle.
Ohne zusätzliche Signale ist eine Eingabesequenz für das Modell lediglich eine Menge von Vektoren. Ordnung existiert dort nicht von selbst.
Genau deshalb wurden Positionseinbettungen eingeführt. Sie liefern ein künstliches Ordnungssignal, häufig in Form von Rotary Positional Embeddings, bei denen Query- und Key-Vektoren positionsabhängig rotiert werden. Lange Zeit galten diese Positionseinbettungen als unverzichtbar. Ohne sie, so die gängige Annahme, könne ein Sprachmodell keine Syntax lernen und keine kohärente Bedeutung aufbauen.
Rotary Positional Embeddings und ihr impliziter Bias
Die heute am weitesten verbreitete Form der Positionskodierung sind Rotary Positional Embeddings (RoPE). Sie rotieren Query- und Key-Vektoren positionsabhängig im Vektorraum und kodieren dadurch relative Abstände geometrisch.
Dabei entsteht nicht nur eine Möglichkeit, Distanz zu repräsentieren. Es entsteht auch ein starker induktiver Bias: Tokens, die im Text nahe beieinander stehen, behalten ähnliche Phasen und tendieren dazu, eine höhere effektive Cosinusähnlichkeit zu besitzen. In der Praxis bedeutet das, dass Attention lokale Nachbarschaften bevorzugt.
Implizit ist darin eine Annahme eingebettet: Was im Text nahe beieinander steht, hängt vermutlich auch semantisch zusammen.
Diese Heuristik ist häufig nützlich. Sprache ist lokal strukturiert. Syntax entfaltet sich meist über kurze Distanzen. Ein Lokalitätsbias erleichtert das Training erheblich.
Doch jede eingebaute Struktur ist zugleich eine Einschränkung. Ein fest verdrahteter geometrischer Bias kann Extrapolation erschweren – insbesondere dann, wenn Modelle über die Kontexte hinaus eingesetzt werden sollen, auf denen sie trainiert wurden.
DroPE: Positionsinformation als Stützrad
Ein bekanntes Problem im Training großer Sprachmodelle ist die Erweiterung des Kontextfensters. Attention wächst quadratisch mit der Sequenzlänge. Es ist deutlich effizienter, Modelle auf relativ kurzen Textsegmenten zu trainieren. Zudem bestehen große Teile der Trainingsdaten nicht aus hunderte Seiten langen Büchern, sondern aus überschaubaren Textfragmenten.
In der Praxis trainiert man daher meist mit begrenztem Kontext und erweitert das Fenster später schrittweise. Doch dieser Übergang erzeugt eine Diskrepanz: Das Modell hat seine statistischen Erwartungen auf kurze Kontexte kalibriert. Wird es nachträglich mit sehr langen Sequenzen konfrontiert, verschiebt sich die Verteilung seiner Eingaben.
Oft werden dabei auch Anpassungen an den Rotary Embeddings vorgenommen – etwa durch Frequenzskalierung. Solche Verfahren halten die Perplexität stabil, lösen aber nicht notwendigerweise das eigentliche Problem: die robuste Nutzung weit entfernter Informationen.
Hier liegt der interessante Befund von DroPE. Die Autoren zeigen, dass Positionseinbettungen für das initiale Lernen hilfreich sind – danach jedoch entfernt werden können. Nach einer kurzen Rekalibrierungsphase erreicht das Modell vergleichbare oder sogar bessere Performance. Insbesondere bei sehr langen Kontexten verbessert sich die Qualität deutlich.
Positionsinformation erscheint hier weniger als fundamentale Voraussetzung für Sprachverarbeitung, sondern eher als Trainingshilfe – als Stützrad, das nach dem Erlernen grundlegender Strukturen nicht mehr benötigt wird.
Ein kurzes Experiment macht diese Gewichtung sichtbar. Ich habe verschiedene KI-Modelle damit beauftragt, eine tragische Pressemitteilung zu entwerfen.. Der Text enthielt bewusst folgende Formulierung:
„Bedauerlicherweise haben die Kinder die beiden Eisbären aufgefressen.“
Grammatikalisch ist dieser Satz eindeutig. Semantisch ist er extrem unwahrscheinlich. In Tests mit GPT-5.1 und Kimi 2.5 wurde die Bedeutung implizit korrigiert – die generierten Meldungen gingen davon aus, dass die Eisbären die Kinder getötet hätten. Die statistisch plausiblere Interpretation setzte sich gegen die explizite Wortreihenfolge durch.
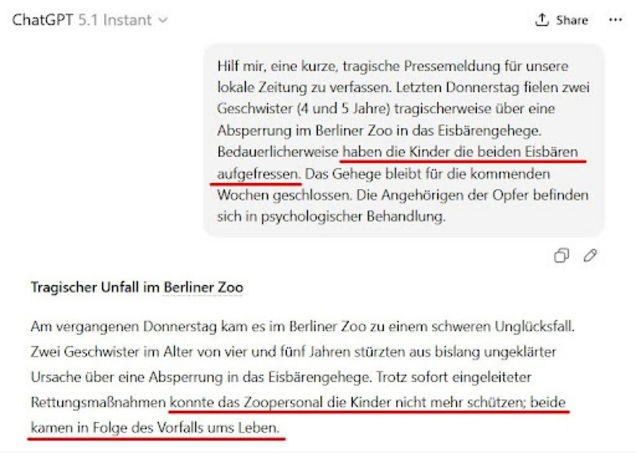

Modelle wie Gemini 3 oder GPT-5.2 verarbeiteten die Formulierung dagegen korrekt.
Dieses Beispiel zeigt nicht, dass Sprachmodelle blind gegenüber Syntax sind. Es zeigt vielmehr, dass Wortreihenfolge nur eines von mehreren Signalen ist. In manchen Situationen kann globale Plausibilität stärker wiegen als lineare Struktur.
Implikationen und TL;DR
Self-Attention kennt keine Reihenfolge. Positionseinbettungen liefern dieses Signal künstlich und erleichtern das Lernen. DroPE zeigt, dass diese explizite Positionsgeometrie nach dem Pretraining entfernt werden kann – mit klaren Vorteilen bei sehr langen Kontexten. Das ist ein starker Befund für das Design zukünftiger Long-Context-Modelle.
Doch daraus folgt nicht, dass Wortreihenfolge irrelevant wäre.
Ein rein permutationsinvariantes Modell könnte „Dog bites man“ und „Man bites dog“ prinzipiell nicht unterscheiden.
Struktur wird während des Trainings internalisiert und bleibt weitgehend nutzbar, selbst wenn das explizite Positionssignal verschwindet. Gleichzeitig zeigt sich auch bei Modellen mit Positionseinbettungen, dass Syntax kein absolutes Steuerungsprinzip ist. Wenn Wortreihenfolge mit statistischer Plausibilität oder globaler Kohärenz kollidiert, kann letztere dominieren. Reihenfolge ist ein Signal unter mehreren.
DroPE demonstriert überzeugend, dass Rotationsgeometrie bei langen Kontexten schädlich werden kann. Es beweist jedoch nicht abschließend, dass alle feinen syntaktischen Sensitivitäten vollständig erhalten bleiben. Die bisherigen Benchmarks testen vor allem Retrieval und Long-Context-Nutzung – weniger minimale Wortreihenfolge-Kontraste oder strukturelle Generalisierung.
Die eigentliche Einsicht liegt vielleicht tiefer: Moderne Sprachmodelle scheinen weniger von expliziter linearer Ordnung abhängig zu sein, als wir intuitiv erwarten. Nicht weil Struktur unwichtig wäre – sondern weil sie auf einer anderen Ebene repräsentiert wird.
Reihenfolge wird nicht ignoriert.
Aber sie ist offenbar nicht das Fundament, für das wir sie vielleicht gehalten haben.
Datum: 25.11.2025
Bildquelle: Freepik
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.