
OpenAI hat in einem aktuellen Paper "Why Language Models Hallucinate" versucht, das Phänomen der Halluzinationen in großen Sprachmodellen zu formalisieren. Dafür greifen die Autor:innen zu einer starken mathematischen Vereinfachung. Das macht ihre Argumentation präziser, lässt aber auch einige Nuancen verloren gehen und an manchen Stellen stoßen sie sichtbar an Grenzen. Dennoch gibt das Paper der wissenschaftlichen Community hilfreiche Werkzeuge an die Hand, um strukturierter über Halluzinationen zu sprechen.
Die zentrale These lautet: Halluzinationen sind kein mysteriöses Nebenprodukt, sondern eine vorhersagbare Konsequenz der statistischen Optimierungsziele, die in Training und Evaluation verwendet werden. Das Paper identifiziert zwei Hauptursachen:
- Pre-Training: Schon beim Vortraining führen die statistischen Lernziele zwangsläufig zu Fehlern.
- Post-Training & Evaluation: Auch nach Finetuning bleiben Halluzinationen bestehen, weil gängige Benchmarks das Raten bei Unsicherheit belohnen und ehrliche Antworten wie „Ich weiß es nicht“ benachteiligen.

Was sind Halluzinationen?
Doch was genau meinen wir eigentlich, wenn wir von „Halluzinationen“ sprechen? Im engeren Sinn bezeichnet der Begriff Fälle, in denen Sprachmodelle falsche Antworten mit hoher Konfidenz erzeugen. Ein Beispiel aus dem Paper:
Drei populäre Modelle wurden nach dem Titel von Adam Kalais Dissertation gefragt. Alle drei Antworten klangen plausibel, aber keine enthielt den korrekten Titel oder das richtige Jahr (Kalai. 2001. “Probabilistic and on-line methods in machine learning”). Die Modelle hatten offenbar ein Gefühl für den groben Kontext - Zeitraum, Fachgebiet, Themenfeld - aber sie gaben eher falsche Fakten zurück, als ihre Unsicherheit zu signalisieren.
Es gibt eine Unterscheidung, die das Paper selbst nicht stark herausarbeitet, die aber wichtig ist: Wissensaufgaben versus Schlussfolgerungsaufgaben. Wissensaufgaben sind etwa Faktfragen wie „Wie hieß Kalais Dissertation?“ - Für eine Antwort muss das Modell diesen Fakt während des Trainings erlernt - also irgendwo in seinen Millionen bzw. Milliarden Parametern komprimiert abgespeichert - haben. Schlussfolgerungsaufgaben hingegen wären so etwas wie „Löse dieses Sudoku“: Hier muss das Modell Regeln anwenden und algorithmisch schließen. Natürlich verschwimmt diese Grenze: Gibt man dem Modell Dokumente aus Wikipedia und fragt nach Kalais Dissertation, wird aus der Wissensfrage plötzlich eine Datenextraktionsaufgabe. Und wenn ein Modell scheinbar algorithmisch ein Sudoku löst, könnte es auch schlicht sehr ähnliche Rätsel im Training gesehen haben. Trotzdem: Mit „Halluzination“ meinen wir in der Regel das erste - also Fehler in Fragen, bei denen wir erwarten, dass das Modell gespeichertes Wissen reproduziert. Bei einem Fehler im Lösungsweg eines Sudokus spricht man dagegen eher von einem misslungenen Reasoning-Schritt als von einer Halluzination.

Die statistischen Ursachen von Halluzinationen
Kernidee: Textgenerierung lässt sich auf ein binäres Klassifikationsproblem reduzieren: Is-It-Valid (IIV). Ein LM wird als IIV-Klassifikator betrachtet, indem man seine Antwortwahrscheinlichkeit mit einem Schwellenwert vergleicht.
Die Autoren zeigen, dass die Fehlerquote beim Generieren immer mindestens doppelt so hoch ist wie die Fehlerrate bei dieser vereinfachten Klassifikationsaufgabe - solange einige milde Bedingungen angenommen werden:
Generative Fehlerrate ≥ 2 × IIV-Fehlerrate
Das ist intuitiv verständlich, weil das Generieren von Text eine weitaus komplexere Aufgabe ist als eine bloße Klassifikation. Dadurch kann man die bekannten Ursachen von Klassifikationsfehlern direkt auch auf generative Modelle übertragen. Das bedeutet: Schon die inhärente Fehlerrate in der Klassifikation setzt eine harte Untergrenze für Halluzinationen. Ein statistisch trainiertes Modell wird zwangsläufig Fehler, also Halluzinationen, produzieren.
Das Paper nennt mehrere Faktoren, die während des Pre-Trainings die Fehlerwahrscheinlichkeit erhöhen können: Epistemische Unsicherheit tritt bei „willkürlichen Fakten“ wie Geburtstagen auf, wo kein Muster erkennbar ist, welches Modelle erlernen könnten. “Poor Models” verweist auf Repräsentationsgrenzen, wenn die Modellklasse für eine Aufgabe ungeeignet ist, wie Trigramme für Langstreckenabhängigkeiten oder Tokenmodelle beim Buchstabenzählen. “Distribution Shift” beschreibt die erhöhte Fehlerquote, wenn Prompts stark von den Trainingsdaten abweichen. Computational Hardness betrifft Aufgaben, die prinzipiell schwer lösbar sind, wie etwa Kryptografie ohne Schlüssel. Und schließlich gilt Garbage In, Garbage Out: Fehlerhafte Trainingsdaten führen direkt zu fehlerhaften Generierungen.
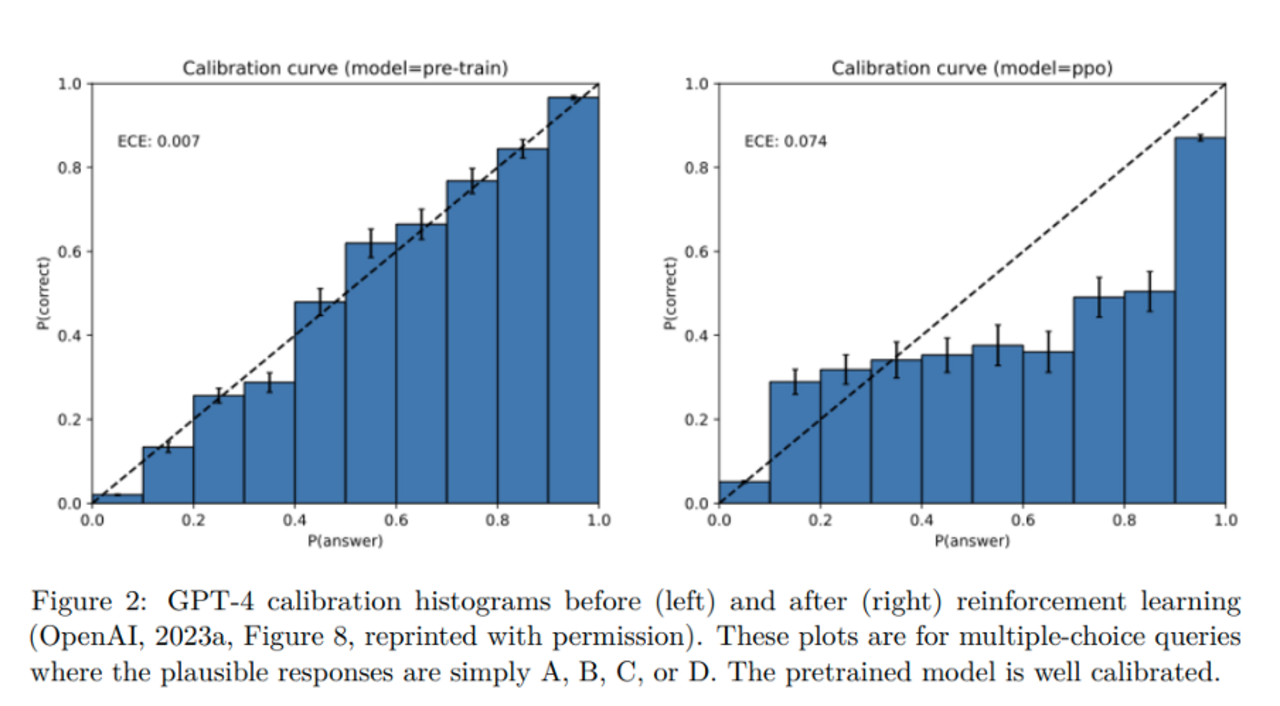
Warum Post-Training Halluzinationen verstärken kann
Auch nach RLHF oder ähnlichen Verfahren bleiben Halluzinationen bestehen – oft werden sie sogar verstärkt. Denn Benchmarks werten in der Regel binär: Eine richtige Antwort zählt, alles andere, falsche Antworten oder „Ich weiß es nicht“ werden genau gleich bestraft. Unter solchen Bedingungen ist Raten immer die optimale Strategie, Schweigen lohnt sich nicht. So lernen Modelle Überkonfidenz, und ihre Kalibrierung verschlechtert sich.
Die „Test-Taker“-Analogie: Studierende in einer Prüfung, bei der leere Antworten nichts zählen, raten zwangsläufig auch bei Unsicherheit. Genau so verhalten sich auch die Modelle.
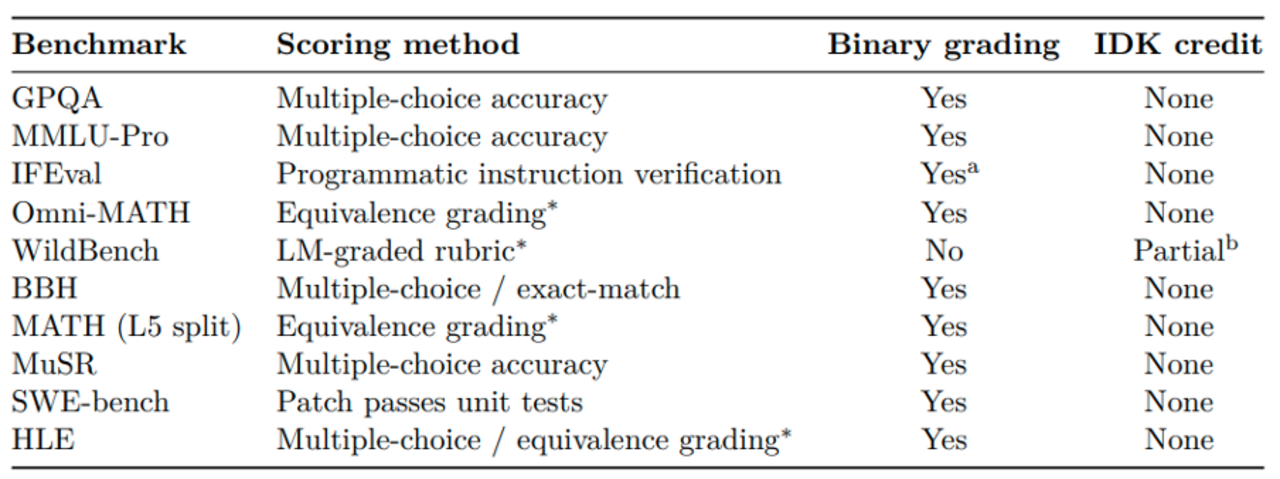
Eine Meta-Analyse (Tabelle 2 aus dem Paper) zeigt: Die überwiegende Mehrheit der populären Benchmarks - von MMLU-Pro über GPQA bis SWE-bench - verwendet genau solche binären Metriken. Überkonfidenz und damit schlechtere Kalibrierung werden systemisch incentiviert.
Kritikpunkte am Paper
Der Is-It-Valid (IIV) Classifier ist eine Vereinfachung
Zunächst muss man klarstellen: der IIV-Classifier ist eine theoretische Vereinfachung. Nicht allen, die über dieses Paper diskutiert haben, schien das so bewusst zu sein.
Die Wahrscheinlichkeit (Log-Probability) einer Sequenz korreliert zwar mit der Validität einer Ausgabe - aber es ist nicht dasselbe. Bei sehr einfachen Aufgaben wie Ja/Nein-Fragen ist die Vereinfachung nah dran: Es gibt im Grunde nur zwei mögliche Tokens. In komplexeren Situationen sieht es anders aus: Es gibt oft viele gleichwertige Arten, dieselbe Frage zu beantworten. Für viele mathematische Theoreme gibt es mehrere verschiedene Beweise, die alle valide sind.
Wenn man nur die Wahrscheinlichkeit einer konkreten Sequenz betrachtet, unterschlägt man, dass die restliche Wahrscheinlichkeitsmasse sich über andere valide Varianten verteilt. Das kann dazu führen, dass die Log-Probability einer einzelnen Ausgabe niedrig wirkt, obwohl diese korrekt ist und das Modell nahezu deterministisch äquivalente, valide Aussagen produziert.
Streng genommen müsste man eine ganze Verteilung an möglichen Outputs betrachten und prüfen, wie viele davon inhaltlich dasselbe aussagen - das wäre aber erheblich aufwendiger.
OpenAIs Lösungsvorschlag ist widersprüchlich
Der Lösungsvorschlag klingt zunächst plausibel: Sprachmodelle sollen nur antworten, wenn sie sich sicher sind. „Antworte nur, wenn du dir zu 90 % sicher bist. Eine falsche Antwort wird mit 9 Punkten bestraft, eine richtige gibt 1 Punkt, und ‚Ich weiß es nicht‘ gibt 0 Punkte.“ Diese Vorgehensweise sollte in gängigen Benchmarks etabliert werden. Damit soll das Modell lernen, Unsicherheit zu kommunizieren, anstatt blind zu raten.
Doch das wirkt widersprüchlich. Das Paper verbringt viele Seiten damit, mathematisch zu zeigen, wie schwer Kalibrierung ist und wie unvermeidlich Fehler durch statistische Muster in den Trainingsdaten entstehen.
Als Lösung soll das Modell lernen, Prompts mit einem Konfidenz-Schwellenwert in verlässliches, gut kalibriertes Antwortverhalten zu überführen. Das ist illusorisch. Es würde voraussetzen, dass das Modell eine stabile Repräsentation seiner intrinsischen Konfidenz entwickelt haben soll und diese auch in natürliche Sprache übersetzen kann. Aber genau das ist ja das Kernproblem: eine gute Kalibrierung der eigenen Konfidenz ist extrem schwer. Menschen selbst sind darin notorisch schlecht, und für Sprachmodelle ist es nicht einfacher. Wer die Funktionsweise von LLMs kennt, wird dieser Lösung keine großen Chancen zurechnen.
Denn mit derselben Methodik wie im Paper lässt sich zeigen: Auch das Klassifizieren der eigenen Konfidenz kann nie perfekt sein. Dieser Ansatz verschiebt nur das Dilemma von der Frage „ist die Antwort valide?“ zur Frage „ist die Antwort sicher genug?“.
Vielleicht fühlte sich OpenAI vor seinen Investoren verpflichtet, irgendeine praktische Antwort auf das Halluzinationsproblem zu liefern.
“Ich-weiß-nicht” untergräbt Reasoning
Ein weiterer Schwachpunkt ist die binäre Art des Ansatzes: Antwort oder „Ich weiß nicht“. Gerade bei stärkeren Modellen und schwierigeren Aufgaben steht Reasoningaber immer mehr im Vordergrund. Modelle generieren viele Tokens, explorieren Lösungswege und legen sich erst am Ende auf eine Antwort fest.
Die vorgeschlagene Methode unterbricht diesen Prozess. Denn die Entscheidung zwischen einer Antwort und einem „Ich-weiß-nicht“ muss früh getroffen werden, noch bevor überhaupt ein Lösungsweg entfaltet wurde. Damit läuft man Gefahr, dass Modelle vielversprechende, aber zunächst unsicher wirkende Reasoning-Ketten zu früh abbrechen. Das ist ein komplexes Meta-Problem, welches auch Menschen schwer fällt - oft zeigt sich erst beim Explorieren eines Lösungsweges, ob er sich lohnt. Viele moderne Ansätze erlauben deshalb gerade diese explorative Phase, auch in parallelen Reasoning-Strängen, bevor sich erst am Ende auf eine Antwort festgelegt wird. Ein Modell, das dagegen zu früh abbricht, verliert diese Fähigkeit.
Im besten Fall ist der Ansatz für Situationen geeignet, in denen ein Modell direkt mit einem unerfahrenen Nutzer interagiert, der eine Halluzination selbst nicht erkennen könnte und für eher simple Problemstellungen.
Next Token Prediction vs. World Model
Ein weniger greifbarer, aber interessanter Punkt: Das Paper betrachtet Sprachmodelle sehr strikt aus der Perspektive von Next Token Prediction (NTP) und den Fehlern, die aus dieser Formulierung zwangsläufig entstehen. Das ist intuitiv nachvollziehbar, wenn es um Fakten geht, die schlicht nicht im Trainingskorpus enthalten sind - da gibt es keine Datenbasis, also auch keine Chance auf eine richtige Antwort.
Komplizierter wird es bei dem, was man als „höherstufiges Wissen“ bezeichnen könnte - etwa mathematische Zusammenhänge oder logische Schlüsse, die sich nicht direkt im Trainingstext finden, sondern aus der Kombination vieler erlernter Fakten emergieren.
Hier entsteht ein Spannungsfeld: Mit der Argumentationslinie des Papers sind auch diese Fähigkeiten letztlich nur statistische Mustererkennung mit unvermeidbaren Fehlern. Gleichzeitig hat OpenAI selbst in der Vergangenheit die gegenteilige Sichtweise stark betont: dass Sprachmodelle durch dieses Training mehr leisten als Next Token Prediction, dass sie in gewisser Weise ein abstraktes Weltmodell der Realität internalisieren. Genau diese Vorstellung – dass LLMs ein Schritt in Richtung dynamischere Artificial General Intelligence sind – wird durch die streng statistische Sicht im Paper ein Stück weit untergraben.
Das Paper liefert theoretische, wenn auch vereinfachte Werkzeuge, um Halluzinationen besser zu verstehen. Es macht deutlich, dass sie statistisch erwartbare Fehler sind – kein unergründliches Mysterium. Eine wichtige Anregung ist die Kritik an den Schwächen gängiger Benchmarks. Doch ein wirklich tragfähiges Rezept, wie man mit Halluzinationen praktisch umgehen sollte, bleibt das Paper schuldig.
Datum: 22.09.2025
Bildquelle: KI-generiert mit ChatGPT
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.