
Kahneman-Tversky-Optimization (KTO) ist eine neue Möglichkeit, die Qualität von Chatbot-Antworten zu optimieren. Was aber macht diesen Ansatz im Vergleich zu seinen Vorgängern RLHF und DPO so besonders? Wir stellen alle drei Ansätze vor.
Ein guter Chatbot leistet mehr, als nur den wahrscheinlichsten nächsten Token vorauszusagen. Large Language Models (LLMs) werden zwar zunächst genau darauf trainiert. Dieses Pretraining alleine macht ein LLM aber noch nicht zu einem hilfreichen Chatbot. Stelle ich diesem Chatbot nämlich eine Frage und es antwortet mit einer weiteren Frage, weil diese dem LLM wahrscheinlich erscheint, ist mir nicht geholfen. Auch bevorzuge ich vielleicht eine übersichtlich in Zwischenüberschriften strukturierte Antwort und möchte Diskriminierungen vermeiden. KTO ist eine der neuesten und spannendsten Entwicklungen, um das LLM auf einfache Art anzupassen und genau solche Optimierungen vorzunehmen. Was aber macht diesen Ansatz im Vergleich zu den Vorgängern RLHF und DPO so besonders?

Das alte Schwergewicht
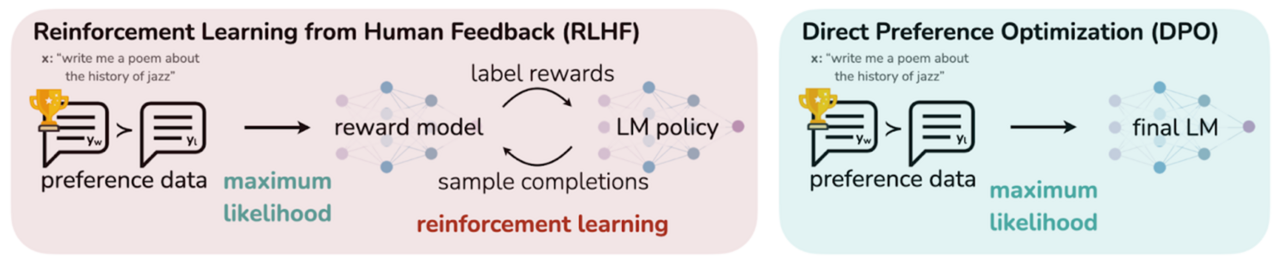
Reinforcement Learning by Human Feedback (RLHF)
Mit RLHF gelangt OpenAI ein Durchbruch. Der Erfolg von GPT-3 ist zu einem großen Teil auf RLHF zurückzuführen. In dem mittlerweile zwei Jahre alten Paper beschreiben Forschende von OpenAI, wie sie es dank Reinforcement Learning schaffen, hilfreichere, faktisch korrektere und weniger toxische Antworten mit dem vortrainierten LLM zu generieren.
Das Training von GPT-3 fand in drei Schritten statt.
- Der erste besteht aus einem unüberwachten Lernen von großen Textmengen.
- In einem zweiten Schritt lernte das Modell in einem überwachten Lernen, Instruktionen zu folgen. Dazu haben Menschen verschiedene Prompts ausgewählt und idealtypische Antworten geschrieben, auf denen das Modell trainiert wurde.
- Im dritten Schritt folgte das RLHF.
Bei RLHF generiert das Modell verschiedene Antworten zu Prompts. Menschen wählen aus, welche Antwort sie präferieren. Auf diesen Präferenzen trainierte OpenAI ein sogenanntes Belohnungsmodell (Reward Model). Dieses lernt vorherzusagen, ob eine Antwort gut ist oder nicht. Mit diesem Belohnungsmodell wurde wiederum das Ausgangsmodell trainiert, immer bessere Antworten zu generieren.
Die leichtgewichtige Alternative
Direct Preference Optimization (DPO)
DPO ist eine ressourcensparsame Alternative zu RLHF, welches einen der größten Nachteile von RLHF beseitigt: Für RLHF müssen drei Modelle im teuren VRAM gehalten werden: das Ausgangsmodell, das Belohnungsmodell und das zu optimierende Modell. DPO führt Gradientenabstieg direkt auf dem zu optimierenden Modell durch. Es kommt also ohne Belohnungsmodell und Reinforcement Learning aus.
Nicht nur spart DPO VRAM, es stellte sich auch heraus, dass es vergleichbare und teilweise sogar bessere Ergebnisse als RLHF erzielt. Reinforcement Learning leidet darunter, eine besonders instabile Form des Trainings zu sein. Das bedeutet, schon kleine Änderungen der Parameter können extreme Auswirkungen haben. Ein gutes Training braucht viel Erfahrung. Im Vergleich dazu ist DPO stabiler, wodurch sich die teilweise besseren Ergebnisse erklären.
Die noch leichtere Alternative
Kahneman-Tversky Optimization (KTO)
KTO ist die modernste der drei hier vorgestellten Optimierungstechniken. Diese Technik zeichnet sich durch zwei Unterschiede gegenüber DPO aus: Sie benötigt erstens keine Präferenzdaten, sondern nutzt die in vielen Anwendungsszenarien einfacher zu generierende Up- und Downvotes. Zweitens zeigen Experimente, dass KTO auch ohne vorheriges Instruction Tuning exzellente Ergebnisse erzielen kann, während DPO dringend auf Instruction Tuning angewiesen ist. Damit kann KTO noch einmal schlanker als DPO angewendet werden.
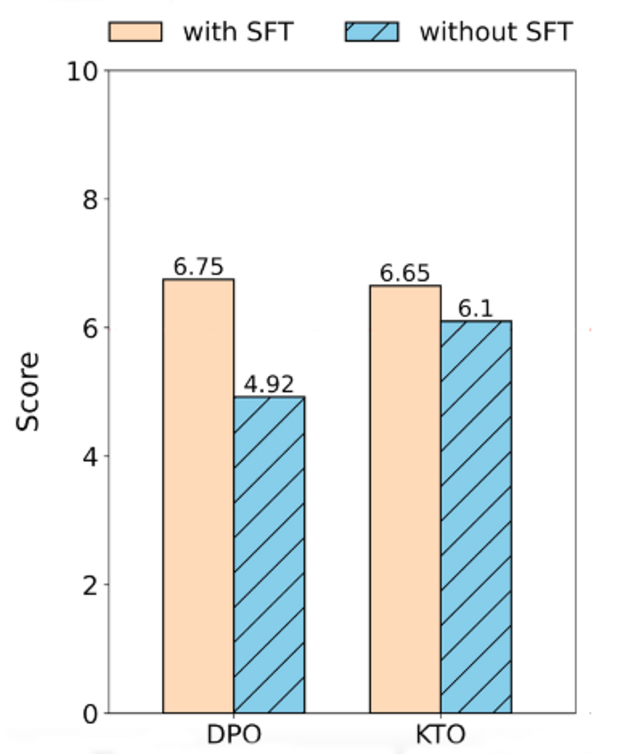
Die Grafikt rechts zeigt die Ergebnisse von Saeidi et. al. Sie verglichen DPO und KTO jeweils mit Instruction Tuning, also Supervised Fine Tuning (SFT), und ohne. Als Modell wählten sie Mistral-7B-v0.1. Die Evaluation fand auf dem MT-Benchmark statt. Während DPO mit 6,75 leicht bessere Ergebnisse als KTO mit 6,65 erzielt, schafft KTO auch ohne SFT ein gutes Ergebnis mit 6,1.
Wie unterscheidet sich der KTO-Datensatz von DPO?
Sowohl RLHF als auch DPO verwenden Präferenzdaten zur Optimierung. Präferenzdaten bestehen aus einem Prompt und zwei Antworten. Eine Antwort wurde von einem Menschen als “gut” bewertet, die andere als “schlecht”. Es braucht also immer einen Vergleich. KTO hingegen kommt auch mit einzelnen entweder “gut” oder “schlecht” bewerteten Antworten zurecht - braucht also keinen Vergleich.
In laufenden Anwendungen, die wir als Digitalagentur mit Feedback von Nutzer*innen verbessern möchten, wären diese Daten leichter zu generieren. Denkbar ist es in einem von uns aufgesetzten RAG-System, dass Nutzer*innen Antworten mit einem Daumen nach oben oder unten bewerten, um das System kontinuierlich zu verbessern. So zeigt auch ChatGPT Daumen zur Bewertung an, um seine Systeme zu verbessern. Zwei Antworten im Vergleich zu bewerten, bedeutet deutlich mehr Aufwand für Nutzer*innen.
Wie schafft es KTO, Up- und Downvotes in eine Loss-Funktion zu übersetzen?
Der Schlüssel für die guten Ergebnisse von KTO liegt in der cleveren Loss-Funktion. Beim Training von Modellen wird immer ein sogenannter Loss optimiert. Je geringer der Loss desto besser ist das Modell. Bei der Optimierung mit RLHF, DPO und KTO heißt ein geringer Loss, dass das Modell Antworten gibt, die gut menschlicher Präferenz entsprechen.
Den Entwickler*innen von KTO gelingt es, Up- und Downvotes auf einzelne Antworten so in einer Funktion zu modellieren, dass die Funktion möglichst nah genug menschliche Präferenz simuliert. Dazu greifen sie auf die Prospect Theory aus dem Jahr 1979 zurück, für die Kahneman und Tverskys später den Nobelpreis für Wirtschaftswissenschaften erhielten.
Die Prospect Theory besagt, dass die menschliche Wahrnehmung von möglichem Gewinn und Verlust in Entscheidungssituationen verzerrt ist. Anschaulich erklärbar ist dieses Phänomen mit diesem Beispiel: Angenommen bei einer Wette kann man 100 € gewinnen mit einer Wahrscheinlichkeit von 80 %. Alternativ kann man sich für garantierte 60 € entscheiden. Die meisten Menschen würden sich für die 60 € entscheiden, obwohl der Erwartungswert der Wette bei 80 € liegt. Menschen schauen also Verlust stärker, als sie hohe Gewinnchancen bevorzugen. Diesem Phänomen wird die Loss-Funktion von KTO gerecht, indem sie das Modell darauf optimiert, insbesondere keine schlecht bewerteten Antworten auszugeben.
Wann ist KTO und wann DPO angebracht?
Die große Resonanz zu KTO in der KI-Welt zeigt, es handelt sich um eine spannende Alternative zu DPO, wenn es darum geht, ein LLM an menschliche Präferenzen anzupassen. Durch die Aufnahme von KTO in die von Huggingface entwickelte TRL-Bibliothek, ist KTO ähnlich einfach zu implementieren wie DPO. Doch KTO scheint nicht immer die bessere Variante zu sein.
Vorteile KTO | Vorteile DPO |
Benötigt lediglich Upvotes (+) und Downvotes (-) | Benötigt Präferenzen (Output A gefällt mir besser als Output B) |
Erzielt auch ohne Instruction Tuning gute Ergebnisse in Benchmarks | Ist auf Instruction Tuning angewiesen |
Kann bei Daten mit viel Rauschen bessere Ergebnisse erzielen als DPO | Schlägt mit guten Präferenz-Daten KTO |
Werden Menschen bezahlt, Labels zu erstellen, ist KTO nicht im Vorteil. In diesem Fall macht es kaum einen Unterschied, ob sie Up- und Downvotes auf einzelne Antworten vergeben oder Präferenzen zwischen zwei Antworten verteilen. Erst in einem laufenden System, bei dem Endkund*innen Labels verteilen, bereiten Up- und Downvotes weniger Aufwand. Zusätzlich schlägt DPO in Benchmarks KTO (wenn auch nur leicht), solange gute Präferenz-Daten vorhanden sind. Dafür kommt DPO mit schlecht gelabelten Daten (Rauschen) besser zurecht und kann sogar das Instruction Tuning überflüssig machen.
KTO kann also in Anwendungsfällen, die wir mit ontolux bearbeiten, eine praktikablere Lösung darstellen, um zu guten Ergebnissen zu kommen. Die besten Ergebnisse erzielt aber DPO, benötigt aber auch einen entsprechend guten Datensatz. Es gilt also je nach Einzelfall die richtige Wahl zu treffen, damit das LLM nicht nur blind das nächste Wort vorhersagt, sondern tatsächlich hilfreich ist.
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Datum: 31.05.2024