
Mit Machine Learning Methoden lässt sich das Ranking von Suchergebnissen beeinflussen, was unter dem Begriff Learning to Rank bekannt ist. Im Folgenden stellen Cornelia Werk und Steffen Kemmerer das Learning to Rank Verfahren in Apache Solr vor, welches bei der interne Suche eines deutschen Versicherers zum Einsatz kommt.
Was ist Learning to Rank?
Learning to Rank (LTR) bezeichnet eine Technik, bei der ein Model mit Machine Learning das Ranking von Ergebnissen bestimmt. Dabei erlernt das Modell verschiedene Elemente in der Reihenfolge ihrer Relevanz für eine bestimmte Anfrage einzustufen. Es ist daher ideal für die Optimierung einer Suchfunktion prädestiniert.
Learning to Rank für Apache Solr
Die Qualität einer Suche wird im Wesentlichen durch drei Stellschrauben erhöht: Neben der eigentlichen Menge der Suchergebnisse (Passen die Ergebnisse überhaupt zur Suchanfrage?) und einer sinnvollen Nutzerführung (Werden die User sinnvoll zu den richtigen Suchergebnissen geleitet?) wird das Ranking der Suchergebnisse gesteuert. Welches Dokument oder welcher Artikel besonders relevant ist, wird altbekannt mit Information Retrieval beantwortet und ist nicht immer ganz trivial. Schließlich gibt es viele Faktoren, die beeinflussen, welches Ergebnis für den Nutzer besonders relevant ist. Dennoch wird schon lange versucht, ein Optimum zu finden. Ein besonders bekannter und erfolgreicher Ranking-Algorithmus ist Okapi BM25. Er wird beispielsweise standardmäßig von Elasticsearch verwendet. Mit zunehmendem Erfolg von Machine Learning setzen sich aber auch andere Methoden durch, um Rankings zu optimieren.
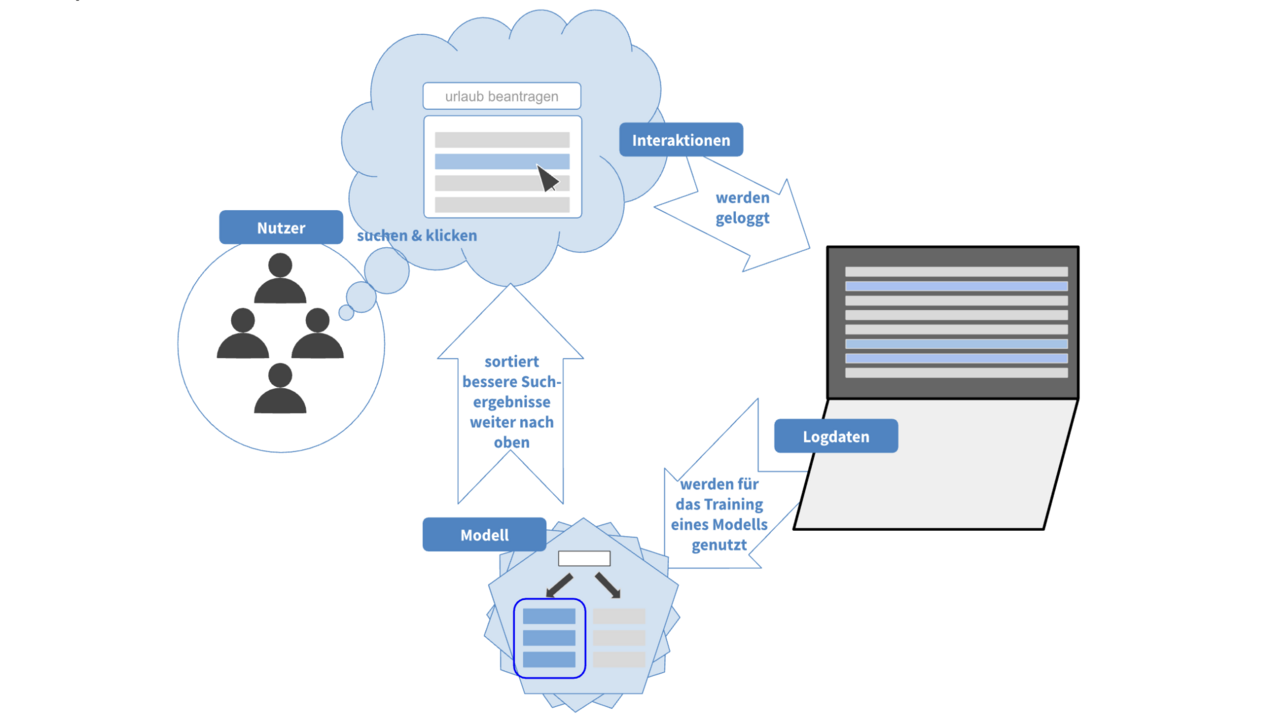
Unsere Herangehensweise für ein Projekt bei einem Versicherungskunden ist es, das Ranking von Suchergebnissen einer internen Suche, die auf Apache Solr basiert, zu verbessern, indem wir mit Methoden des maschinellen Lernens ein geeignetes Modell trainieren. Dieses lernt anhand der Nutzerinteraktionen, welche Suchergebnisse für welche Suchanfragen besonders relevant sind.
Die Trainingsdaten
Für das Training eines geeigneten Modells galt es zunächst, eine Grundlage aus Nutzungsdaten zu schaffen. Denn nur mit passenden Trainingsdaten kann das Modell beim Training auch die richtigen Schlüsse ziehen.
Daten aus dem Tracking
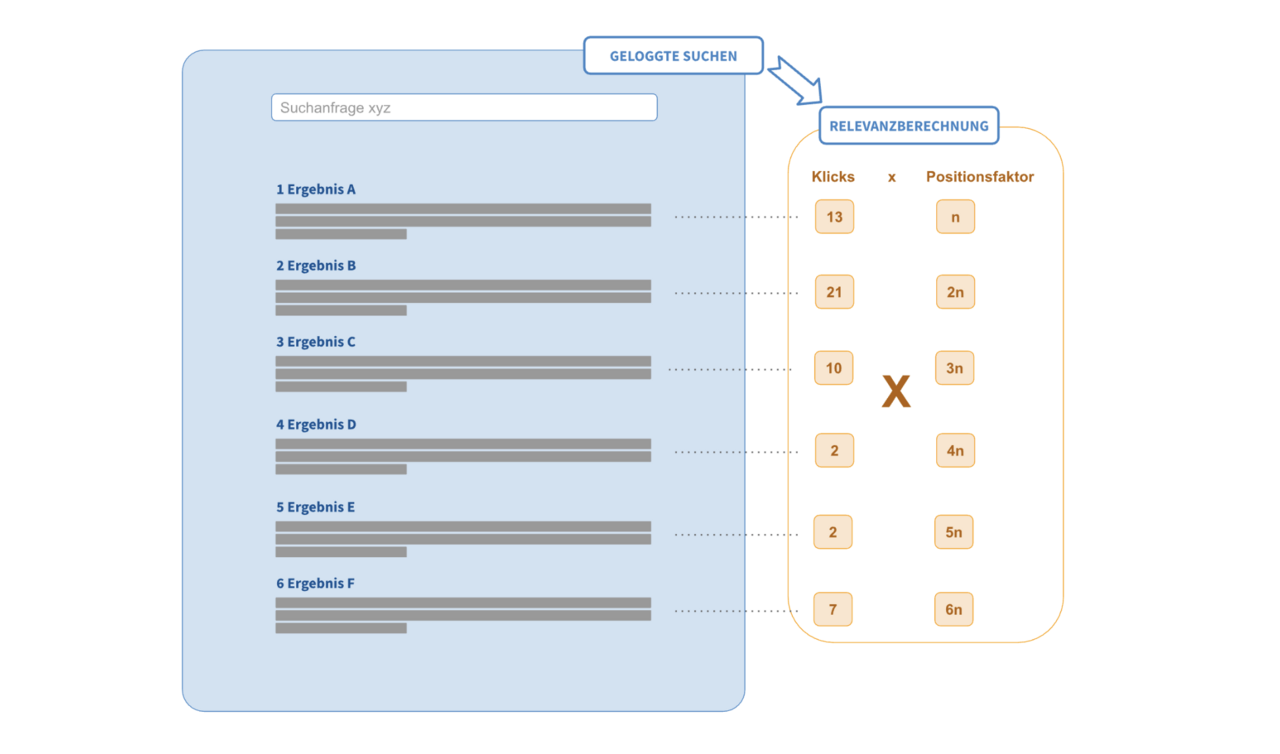
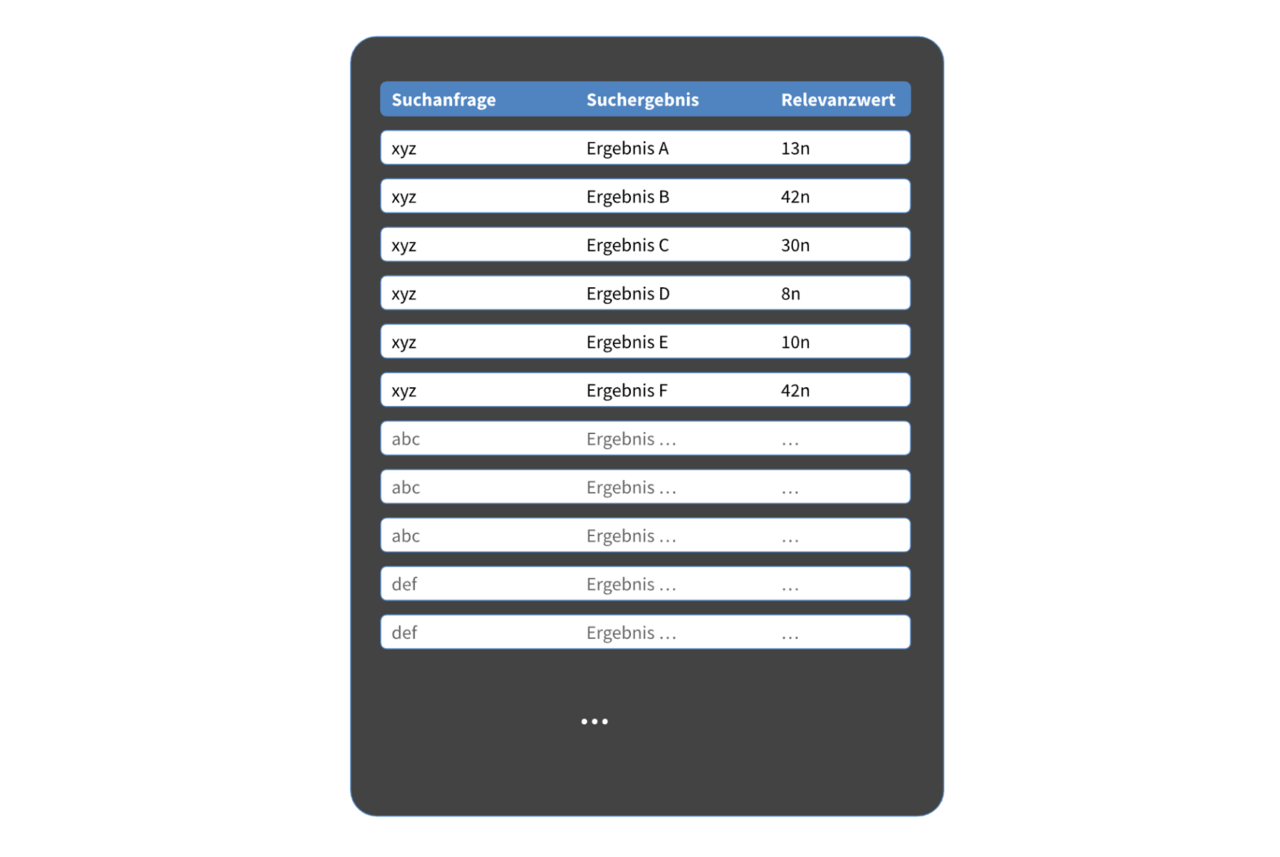
Da bereits über einen längeren Zeitraum die Interaktionen, welche Nutzer auf der internen Wissensmanagementplattform getätigt haben, mit dem Analysetool Matomo geloggt wurden, boten sich diese Nutzungsdaten als Grundlage an. Aus diesen Daten musste nun eine Aussage darüber gewonnen werden, welche Dokumente für welche Suchanfragen besonders relevant sind. Die Kombinationen aus Suchanfrage mit Suchergebnis und einem jeweils dazugehörigen Relevanzwert bilden letztlich die Trainingsgrundlage.
Dieser Relevanz-Wert sollte angeben, wie gut das betreffende Suchergebnis zur Suchanfrage passt. Als Relevanzwert konnten wir in den geloggten Daten die Anzahl der Klicks auf ein spezifisches Dokument nach einer Suche heranziehen. Die Annahme dahinter war einfach: Je öfter ein Dokument geklickt wurde, desto besser scheint es zur Suchanfrage zu passen. Diese Daten wurden aus den geloggten Interaktionen von 3 Monaten extrahiert.
Allerdings sind Nutzer tendenziell bei der Suche etwas voreingenommen: Je weiter oben ein Dokument im Ranking der Suchergebnisse erscheint, desto wahrscheinlicher ist auch, dass es (unabhängig von seiner Relevanz) geklickt wird. Daher lassen wir in die Berechnung des Relevanzwerts auch einfließen, an welcher Position sich das geklickte Dokument in der Suchergebnisliste ursprünglich befand. Dokumente, welche weiter hinten in der Suchergebnisliste standen und trotzdem geklickt wurden, sind relevanter als solche, die genauso oft geklickt wurden, aber weiter vorn standen.
Zusätzlich zu den geklickten Dokumenten wurden für jede Suchanfrage außerdem Dokumente hinzugefügt, welche zwar in der Suche nach dem betreffenden Suchbegriff angezeigt werden, allerdings nicht geklickt wurden. Diese dienten als Negativbeispiele für das Training.
Beim Training selbst hat sich gezeigt, dass es schon bei der Generierung dieser Trainingsdaten auf Feinheiten ankommt, die letztlich die gesamte Performance des Modells sichtbar beeinflussen.
Erweiterte Daten (Features)
Unsere Datengrundlage beim Training eines geeigneten Modells besteht also aus Suchanfragen, Suchergebnissen und dazugehörigen Relevanzwerten. Allerdings geht es beim Training darum, dem Algorithmus Informationen an die Hand zu geben, die ihm helfen, über die Relevanz eines Suchergebnisses für eine Suchanfrage zu entscheiden. Oder anders: Gibt man einem Menschen nur den Titel eines Dokuments, entscheidet er sich eventuell eher für eine andere Suchergebnisreihenfolge, als wenn er auch über zusätzliche Informationen wie z.B. ein Datum als Aktualitätsangabe, verfügt. Mehr Informationen über die Dokumente können also dazu führen, dass auch der Algorithmus besser über die Relevanz einzelner Dokumente entscheidet. Gleichzeitig können zu viele irrelevante Informationen dazu führen, dass Muster in den Daten falsch erkannt werden oder diejenigen Dokumenteneigenschaften, die besonders wichtig sind, durch den Algorithmus nicht als wichtig genug eingestuft werden. Es gilt also nicht einfach möglichst viele Eigenschaften der Suchergebnisse in die Trainingsdaten miteinzubeziehen, sondern auch sog. Noise (rauschen) zu verhindern.
Neben Eigenschaften zu den einzelnen Dokumenten können auch Informationen über die Suchanfrage selbst in den Trainingsdaten das Training erleichtern.
Wir haben daher weitere Informationen in unser Training, sogenannte Features, einfließen lassen.
- Scores
Solr selbst nutzt eigene Ranking-Algorithmen, um Suchergebnisse nach ihrer Relevanz zur Suchanfrage zu sortieren. Für jedes Dokument, das in irgendeiner Form ein Match zur Suchanfrage darstellt, wird dabei ein Score berechnet. Das Dokument mit dem höchsten Score steht dann an erster Stelle in der Suchergebnisliste, sofern keine weiteren Maßnahmen vorgenommen werden. Dieser ursprüngliche Score fließt in die Trainingsdaten ein.
Darüber hinaus berücksichtigen wir, an welchen Stellen ein Dokument mit der Suchanfrage matcht. Sowohl für Matches im Titel als auch im Text des Dokuments werden einzelne Scores berechnet, die als solche ebenfalls als Features integriert werden.
- Phrase Match
Bei mehreren Wörtern in der Suchanfrage macht es einen Unterschied, ob nur die einzelnen Wörter im Dokument vorkommen, oder ob die Wörter hintereinander in der eingegebenen Reihenfolge im Text stehen. Daher haben wir auch den Score der Phrasensuche als Feature verwendet.
- Query in Keywords
Darüber hinaus werden im Dokumentenmanagementsystem unseres Kunden zu den Dokumenten selbst treffende Schlagwörter vergeben. Sollte es bei einer Suchanfrage ein Match in diesen Schlagwörtern geben, kann auch das eine ausschlaggebende Information für das zu trainierende Modell sein. Daher ist auch das eines unserer verwendeten Features.
- Dokumententyp
Das Wissensmanagementsystem unseres Kunden enthält eine Reihe verschiedener Dokumententypen. Ein weiteres Feature beim Training ist daher die Information, welchem dieser Dokumententypen das betreffende Suchergebnis angehört. Beispiele für mögliche Dokumententypen sind: Artikel, aktuelle Nachrichten, Downloads, etc.
- Themenhierarchie
Inhalte im Wissensmanagementsystem unseres Kunden enthalten außerdem Informationen darüber, welchen Themen diese Inhalte zugeordnet werden. Diese sind hierarchisch strukturiert und stellen ebenfalls eines der verwendeten Features dar.
- Aktualität
Ein weiteres Feature ist die Aktualität des Inhalts. Dafür fließen sowohl das Datum der Erstellung des Inhalts als auch seine letzte Aktualisierung in die Daten mit ein.
Zusammengefasst wurden also für das Training des LTR-Modells die Nutzungsdaten aus Matomo über einen Zeitraum von drei Monaten verwendet. Diese beinhalteten die Suchbegriffe und die anschließend geklickten URLs im Suchergebnis. Durch Aggregieren der URLs nach Suchanfragen erhält man pro Suchanfrage eine Liste der aufgerufenen Seiten mit Klick-Häufigkeit.
Anschließend werden diese Suchbegriffe um die Feature-Vektoren ergänzt, die man aus Solr durch eine LTR-Query mit dem Suchbegriff und der Ausgaben des Feldes [features] erhält und in dem Format gespeichert, das auch von SVM-Rank und dem LETOR-Datensatz verwendet wird.
Training des LTR-Modells
Es gibt mehrere Ansätze für das Lernen von LTR-Modellen, die je nach den spezifischen Anforderungen eines Problems, den verfügbaren Daten und anderen Faktoren eingesetzt werden können. Hier sind einige der gängigsten Ansätze:
- Pointwise
Beim Pointwise-Ansatz wird das Lernproblem in ein Regression- oder Klassifikationsproblem umgewandelt, indem jeder Trainingsdatensatz (normalerweise ein Dokument oder eine Instanz) einzeln betrachtet wird. Das Modell lernt dann, die Relevanz eines einzelnen Dokuments vorherzusagen. Dieser Ansatz ist einfach und direkt, jedoch berücksichtigt er nicht die Interaktionen zwischen den Dokumenten einer Suchanfrage. - Pairwise
Im Pairwise-Ansatz werden Trainingsdatensätze als Paare von Dokumenten betrachtet, wobei das Ziel darin besteht, das bessere von zwei Dokumenten für eine bestimmte Suchanfrage zu identifizieren. Das Modell lernt, welche Reihenfolge von Dokumenten bevorzugt wird, indem es die Reihenfolge von Paaren von Dokumenten optimiert. Dieser Ansatz berücksichtigt die relative Relevanz von Dokumenten, ist jedoch anfällig für Unausgewogenheiten in den Daten. - Listwise
Beim Listwise-Ansatz wird die gesamte Liste von Dokumenten für eine bestimmte Suchanfrage betrachtet. Das Modell lernt direkt, die optimale Reihenfolge der gesamten Liste von Dokumenten zu erzeugen, basierend auf Metriken wie DCG (Discounted Cumulative Gain) oder NDCG (Normalized Discounted Cumulative Gain). Dieser Ansatz berücksichtigt die Interaktionen zwischen den Dokumenten einer Suchanfrage und kann direkt auf die gewünschten Metriken optimiert werden.
Das LambdaMART-Verfahren, das wir verwenden, verfolgt den Pairwise-Ansatz.
LambdaMART ist ein maschinelles Lernverfahren, das speziell für das Ranking von Suchergebnissen entwickelt wurde. Es handelt sich um eine Erweiterung des MART (Multiple Additive Regression Trees) Algorithmus, der auf das Ranking von Suchergebnissen zugeschnitten ist. LambdaMART nutzt eine Kombination von Entscheidungsbäumen und Gradientenabstiegsverfahren, um ein Modell zu trainieren, das die Relevanz von Suchergebnissen für eine bestimmte Suchanfrage vorhersagt.
Es gibt verschiedene Bibliotheken, die LambdaMART implementieren, z.B. Ranklib und XGBoost. RankLib ist eine Java-Bibliothek, die verschiedene Ranking-Algorithmen, einschließlich LambdaMART, implementiert. Es bietet eine Reihe von Werkzeugen für das Trainieren von Ranking-Modellen und die Evaluierung ihrer Leistung. XGBoost ist eine weit verbreitete Bibliothek für Gradient Boosting, die auch das LambdaMART-Modell unterstützt. Sie bietet eine flexible API und ist in Python und anderen Programmiersprachen verfügbar.
Wir haben für das Training XGBoost verwendet.
Integration des LTR-Modells in Solr
Apache Solr enthält schon ein LTR-Plugin, mit dem eine Relvanzverschiebung der Suchergebnisse mit Hilfe eines LTR-Modells möglich ist. Um unser trainiertes Modell (Reranking) in die Suche zu integrieren, sind folgende Schritte auszuführen:
LTR-Plugin aktivieren
Zur Verwendung von Learning to Rank in Solr muss zuerst das LTR-Plugin beim Start aktiviert werden:
bin/solr start -e mycore -Dsolr.ltr.enabled=true
Feature Store konfigurieren
Die oben beschriebenen Features müssen in einem Feature Store definiert werden. Die Feature-Store-Datei hat dabei folgendes JSON-Format:
[
{
"name": "updateDate",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {
"q": "{!func}recip( ms(NOW,lastUpdatedAt), 3.16e-11, 1, 1)"
},
"store": "myFeatureStore"
},
{
"name": "isDownload",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {
"fq": [
"{!terms f=documentType}Download"
]
},
"store": "myFeatureStore"
},
{
"name": "isFaq",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {
"fq": [
"{!terms f=documentType}Faq"
]
},
"store": "myFeatureStore"
},
{
"name": "queryInKeywords",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {
"q": "{!edismax df=keywords}${query}"
},
"store": "myFeatureStore"
}
]
Feature Store in den Solr Core laden
Die erzeugte Feature Store Datei muss anschließend in den Solr geladen werden:
curl -XPUT 'http://localhost:8983/solr/mycore/schema/feature-store' --data-binary "@/path/myFeatures.json" -H 'Content-type:application/json'
Modell in den Solr Core laden
Analog wird auch das trainierte Modell in den Solr geladen:
curl -XPUT 'http://localhost:8983/solr/mycore/schema/model-store' --data-binary "@/path/myModel.json" -H 'Content-type:application/json'
LTR-Modell bei der Suche verwenden
Nun kann man das LTR-Modell in der Suche verwenden und eine Rerank-Query ausführen. Dabei werden die ersten 100 Treffer der normalen Suche genommen und auf Basis des gelernten Modells umsortiert:
http://localhost:8983/solr/mycore/query?q=test&rq={!ltr model=myModel reRankDocs=100}&fl=id,score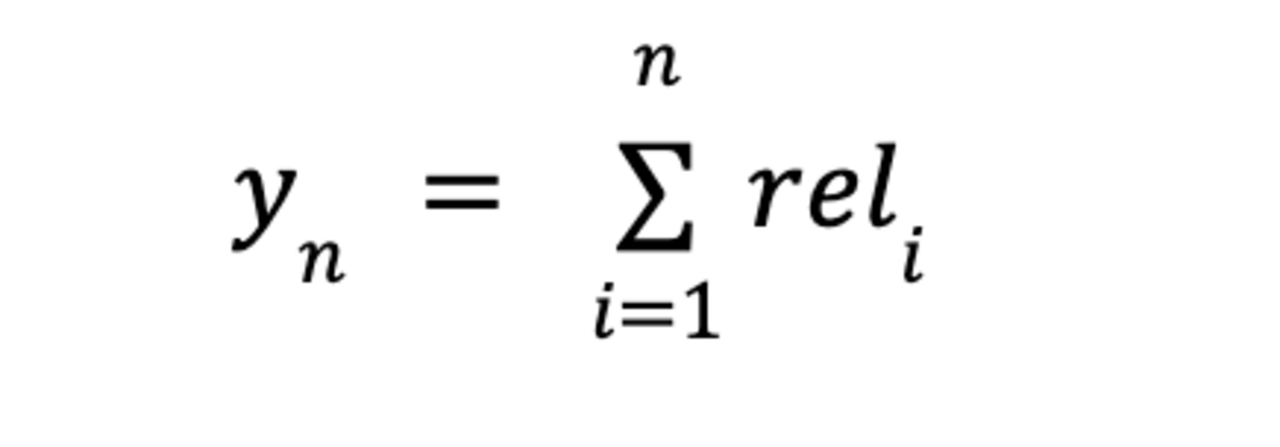
Erfolgsmessung
Bei jeder Optimierung stellt sich natürlich die Frage: Ist das Ergebnis, das ich jetzt bekomme, wirklich besser, als das davor? Um diese Fragen nicht nur anhand von Stichproben, also rein subjektiv, zu beantworten, gibt es verschiedene Möglichkeiten, systematisch zu evaluieren.
Evaluation von LTR-Modellen
Die Metriken, die man üblicherweise zur Evaluation von LTR-Modellen verwendet sind Mean Reciprocal Rank (MRR), Mean Average Precision (MAP) und Normalized Discounted Cumulative Gain (NDCG):
Mean Reciprocal Rank
Wie der Name sagt, handelt es sich hier um einen gemittelten Wert. Dieser wird über verschiedene Queries hinweg gebildet. Für jede Query selbst wird der “Reciprocal Rank” gebildet, bei dem 1 geteilt wird durch die Position des ersten passenden Suchergebnisses. Befindet sich das erste passende Suchergebnis zu einer Suchanfrage also direkt an Position 1 der Suchergebnisliste, ist der Reciprocal Rank 1. Steht es an Position 2, wäre der Reciprocal Rank ½. Diese Berechnung wird beim MRR für eine Reihe von Suchanfragen durchgeführt und dann ein Mittelwert gebildet.
Problematisch ist hier, dass nur das erste passende Suchergebnis in die Evaluationsmetrik einfließt. Befindet sich also wirklich das erste passende Suchergebnis an Position 1, ist der Reciprocal Rank immer 1, unabhängig davon, ob das nächste passende Suchergebnis an Position 2, 20 oder 200 steht.
Mean Average Precision
Bei der sogenannten Mean Average Precision dagegen werden auch weitere Suchergebnisse in die Evaluation einbezogen. Ausgangspunkt hier ist die sogenannte Precision: ein Maß darüber, wie viele der Suchergebnisse tatsächlich zur Suchanfrage passen. Konkret wird zur Berechnung der Precision die Anzahl der gefundenen passenden Suchergebnisse geteilt durch die Anzahl aller Suchergebnisse.
Um die Average Precision zu erhalten, wird vorgegangen wie oben beschrieben: es wird zunächst eine Summe aus Quotienten gebildet, bei denen im Zähler steht, das wievielte passende Suchergebnis betrachtet wird, und im Nenner die Anzahl der Gesamtsuchergebnisse bis dahin.
Um die sogenannte Mean Average Precision zu erhalten, wird wiederum eine ganze Reihe von Queries betrachtet, für jede dieser Queries die Average Precision berechnet und anschließend das Mittel berechnet.
Normalized Discounted Cumulative Gain
Für NDCG gehen wir als Grundlage zunächst vom sogenannten Cumulative Gain (CG) aus: dieser gibt die Summe aller Relevanzscores der Suchergebnisse an:

Da wir in unserem Beispiel nur zwischen relevant (1) und irrelevant (0) unterscheiden, würde sich für dieses Beispiel also ein Wert von 2 ergeben. Vorstellbar wäre aber auch ein abgestuftes Relevanz-Scoring, bei dem Ergebnisse beispielsweise nach “sehr relevant” (3), “relevant” (2), “eher nicht relevant” (1) und “irrelevant” (0) o. ä. eingeteilt werden.
Die Position, an der die Suchergebnisse stehen, wird an dieser Stelle nicht mit einbezogen, es wäre in unserem Beispiel also egal, ob die beiden korrekten Suchergebnisse an Position 1 und 2, Position 3 und 4 oder wie oben beschrieben an Position 1 und 4 stehen.
An dieser Stelle kommt der Discounted Cumulative Gain (DCG) ins Spiel. Hier erscheint die Position, an der das Suchergebnis steht, wieder als Teil des Nenners eines Quotienten. Im Gegensatz zur Average Precision wird hier aber außerdem logarithmiert:
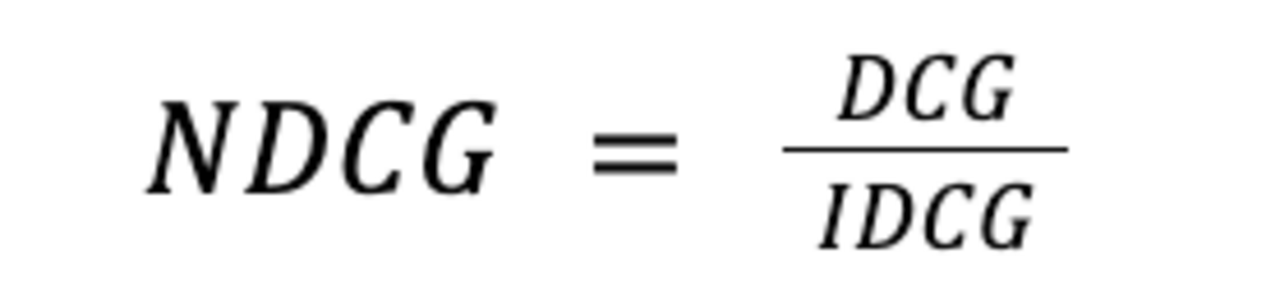
In der Praxis wird der Zähler oft durch 2reli-1 ersetzt, sofern es Abstufungen hinsichtlich der Relevanz unterschiedlicher Ergebnisse (z.B. wie oben beschrieben) gibt. Für eine reine Unterscheidung zwischen relevant (1) und irrelevant (0) kommen beide Varianten auf das Gleiche heraus.
Um nun auf den Normalized Discounted Cumulative Gain (NDCG) zu kommen, wird zusätzlich der Idealwert des DCG berechnet (Ideal Discounted Cumulative Gain - IDCG), also der Wert, den DCG erreichen würde, wenn alle Suchergebnisse optimal nach ihrer Relevanz gerankt wären. Auch hier können also Abstufungen zwischen dem Relevanzgrad einzelner Suchergebnisse miteinbezogen werden.
Anschließend wird damit normalisiert:
Hier wird also berechnet, inwiefern sich der DCG dem IDCG bereits angenähert hat. Ist NDCG = 1, so wurde der Idealwert bereits erreicht. Und je niedriger der NDCG ist, bzw. je näher an 0 er sich befindet, desto schlechter ist das Ranking noch.
Evaluation im Livebetrieb - Interleaving
Die tatsächliche Beurteilung der Qualität von LTR-Modellen ist aber nicht so einfach. Die Evaluation wird zunächst auf einer Testmenge durchgeführt, die aus den ursprünglichen Trainingsdaten stammt, aber nicht zum Training verwendet wurde. Trotz guter Ergebnisse auf den Testdaten kann es dabei aber zu negativen Überraschungen im Produktivbetrieb kommen. Das liegt daran, dass die aktuell in der Suche erzeugten Daten in irgendeiner Form anders sein können, als die älteren Trainingsdaten, z.B. durch eine Verhaltensänderung der Nutzer oder saisonale Effekte, die in den Trainingsdaten nicht abgebildet sind.
Daher ist es sinnvoll, das Modell, zusätzlich zur Evaluation auf den Testdaten, auch im Produktivbetrieb zu evaluieren. Dafür bietet sich das Interleaving-Verfahren an.
Was ist Interleaving?
Interleaving ist eine Evaluierungstechnik im Bereich des Information Retrieval, die verwendet wird, um die Leistungsfähigkeit von Suchmaschinenranking-Algorithmen oder -Modellen zu bewerten. Insbesondere bei der Bewertung von Learning-to-Rank-Modellen kann Interleaving nützlich sein, um festzustellen, welches Modell die besten Suchergebnisse liefert.
Bei Interleaving werden die Suchergebnisse von zwei oder mehr Ranking-Modellen miteinander kombiniert, um eine gemeinsame Liste von Suchergebnissen zu erstellen. Diese kombinierten Suchergebnisse werden dann Benutzern präsentiert und deren Reaktionen gemessen, um die Qualität der Suchergebnisse zu bewerten.
Der Prozess des Interleavings erfolgt typischerweise wie folgt:
- Generierung von Suchergebnissen: Zunächst werden die Suchergebnisse von zwei oder mehr verschiedenen Ranking-Modellen für eine bestimmte Suchanfrage generiert. Jedes Modell produziert eine Liste von Dokumenten, die nach ihrer Relevanz geordnet sind.
- Interleaving: Die Suchergebnisse der verschiedenen Modelle werden abwechselnd miteinander kombiniert, um eine gemeinsame Liste von Suchergebnissen zu erstellen. Dies bedeutet, dass die Dokumente abwechselnd aus den verschiedenen Listen genommen und in die kombinierte Liste eingefügt werden.
- Präsentation an Benutzer: Die kombinierte Liste von Suchergebnissen wird den Benutzern präsentiert. Durch die Messung von Click-Through-Rates (CTR), kann man feststellen, welche Suchergebnisse von Benutzern am häufigsten angeklickt wurden.
Auswertung der Ergebnisse: Die Reaktionen der Benutzer auf die kombinierten Suchergebnisse werden analysiert, um festzustellen, welches Ranking-Modell die besten Suchergebnisse liefert.
Interleaving ermöglicht es, die Leistungsfähigkeit verschiedener Ranking-Modelle direkt miteinander zu vergleichen, indem sie unter ähnlichen Bedingungen präsentiert und von Benutzern bewertet werden.
Das Solr LTR-Plugin beinhaltet bereits eine Interleaving-Funktionalität, die wir für die Evaluation im Produktivbetrieb genutzt haben.
Fazit
In Apache Solr lassen sich mit dem LTR Modul eigene maschinell erlernte Ranking-Modelle konfigurieren und ausführen. Die Interleaving-Funktionalität bietet zudem die Möglichkeit, die Leistung verschiedener Ranking Modelle miteinander zu vergleichen.
In unserem Beispiel konnte so das Ranking anhand des Klickverhaltens der Nutzer für eine interne Suche eines Versicherers angepasst werden. Durch die Auswertung der angeklickten Treffer auf der Suchergebnisseite ließ sich die Qualität des Rankings einfach bewerten und sukzessiv optimieren.
Learning to Rank bietet uns so eine Möglichkeit, Suchergebnisse für eine spezielle Domäne einfach, flexibel und messbar zu verbessern.
__
Bildquelle: Freepik AI generiert
Kontaktieren Sie uns
Einstiegsangebot für Unternehmen
Entdecken Sie die Möglichkeiten der künstlichen Intelligenz für Ihr Unternehmen. Kontaktieren Sie uns für eine kostenlose Beratung und entdecken Sie die Vorteile von Sprachmodellen, Machine Learning und Suchtechnologien.
Autoren

Cornelia Werk
Als Lead Consultant Search berät Cornelia mit ihrem Team Kunden bei Projekten zu intelligenter Suche auf der Basis von TXTWerk und Solr/Elasticsearch. Sie ist studierte Linguistin und hat bereits als Data Analystin fundierte Erfahrungen in den Bereichen intelligente Datenanalyse, KI und Qualitätsmanagement sammeln können.
Steffen Kemmerer
Steffen Kemmerer ist Senior Software Developer und Product Manager von TXTWerk, dem NLP Framework von ontolux.