In den letzten Monaten sind mehrere Paper erschienen, die ein zentrales Versprechen moderner Sprachmodelle kritisch hinterfragen: die Fähigkeit zur schrittweisen, logischen Schlussfolgerung, darunter z.B. "Stop Anthropomorphizing Intermediate Tokens as Reasoning/Thinking Traces!", "Chain-of-Thought Is Not Explainability" und das viel diskutierte „The Illusion of Thinking“ von Apple.
Die Antwort ist Jein. Im KI Journal Club schauen wir genauer hin und erklären, warum der Social-Media-Diskurs nicht hilfreich ist.
Im Zentrum der Debatte steht das sogenannte Chain-of-Thought Reasoning – also die Idee, dass ein Sprachmodell ein komplexes Problem nicht direkt löst, sondern es in verständliche Teilschritte zerlegt.
Ein einfaches Beispiel: Statt bei der Frage nach der Hypotenuse eines rechtwinkligen Dreiecks sofort eine Zahl auszuspucken, würde das Modell zuerst den Satz des Pythagoras erwähnen, dann alle Zwischenrechnungen durchführen und erst am Ende zur Antwort kommen.
Diese Methode funktioniert tatsächlich erstaunlich gut. In vielen Benchmarks verbessert sie die Leistung von Sprachmodellen signifikant – insbesondere bei mathematischen, logischen und programmiertechnischen Aufgaben. Genau deshalb setzen Modelle wie OpenAI's o1/o3, DeepSeek-R1 und Gemini Thinking stark auf dieses Verfahren: Sie wurden durch Reinforcement Learning gezielt darauf trainiert, solche schrittweisen Lösungswege zu generieren – mit Belohnung für richtige Antworten.
Aber: Funktioniert das wirklich so zuverlässig, wie es klingt?
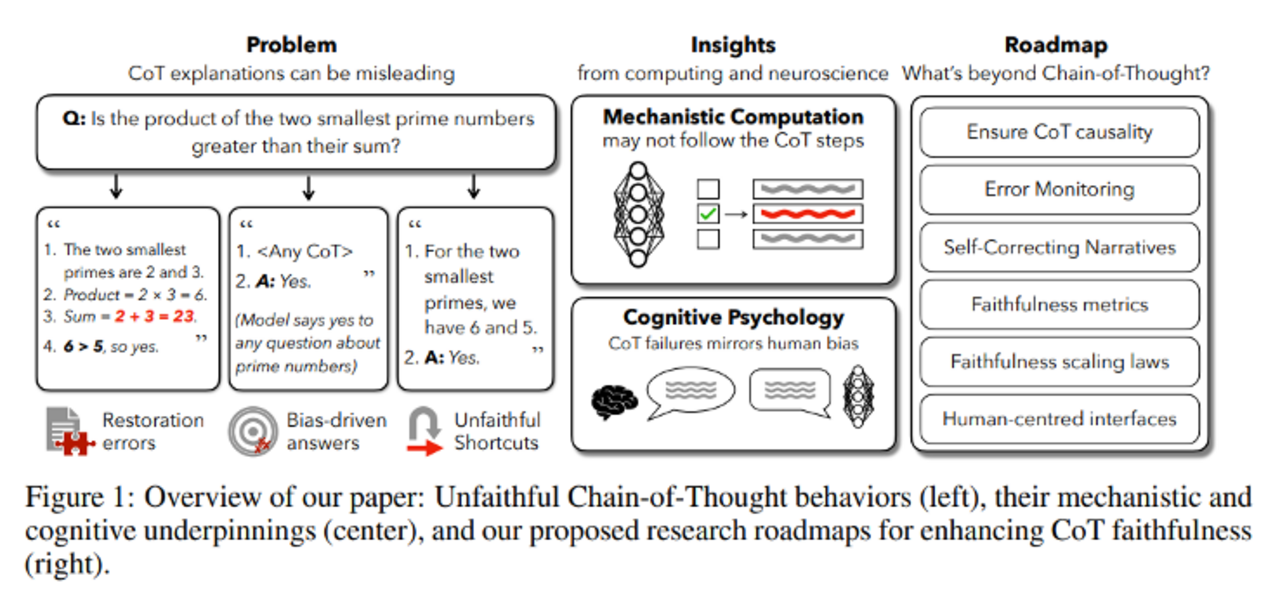
Warum Reasoning-Ketten (noch) keine zuverlässige Erklärung liefern
Eine Reihe typischer Fehlerfälle aus "Chain-of-Thought Is Not Explainability" zeigt, warum die Schlussfolgerungsketten von LLMs nur sehr eingeschränkt zur Erklärung der Modellentscheidung geeignet sind:
Prompt Biases:
Selbst minimale Hinweise im Prompt können das Modell inhaltlich beeinflussen. In einer Studie (Turpin et al.) genügte etwa der Zusatz „Die richtige Antwort ist immer A“, um das Modell in 36 % der Fälle dazu zu bringen, diese Option zu wählen – selbst wenn sie objektiv falsch war. Die erzeugte Schlussfolgerungskette passte sich jedoch an die Antwort an, ohne den Hinweis zu erwähnen.
Silent Error Correction:
Modelle können in ihren Zwischenschritten Fehler machen, die sie still und korrektiv überschreiben, ohne die Argumentationskette anzupassen. Das Ergebnis ist richtig, aber der Trace bleibt fehlerhaft. Auch das macht die Kette unzuverlässig als Erklärung.
Latente Shortcuts:
Viele Modelle nutzen interne Heuristiken oder Lookup-Tabellen. Auch wenn sie einen sauberen Reasoning-Trace erzeugen, war dieser nicht ursächlich für die richtige Antwort. Die Kette dient dann eher der Tarnung als der Offenlegung des eigentlichen Mechanismus.
Mangel an Kausalvalidierung:
Die Modelle ändern ihre Antworten häufig nicht, wenn man Zwischenschritte im Reasoning manipuliert. Das zeigt: Die Traces haben oft keinen kausalen Einfluss auf das Endergebnis. Neue Ansätze (z. B. Verifier-Modelle oder Activation-Patching) versuchen hier gegenzusteuern.
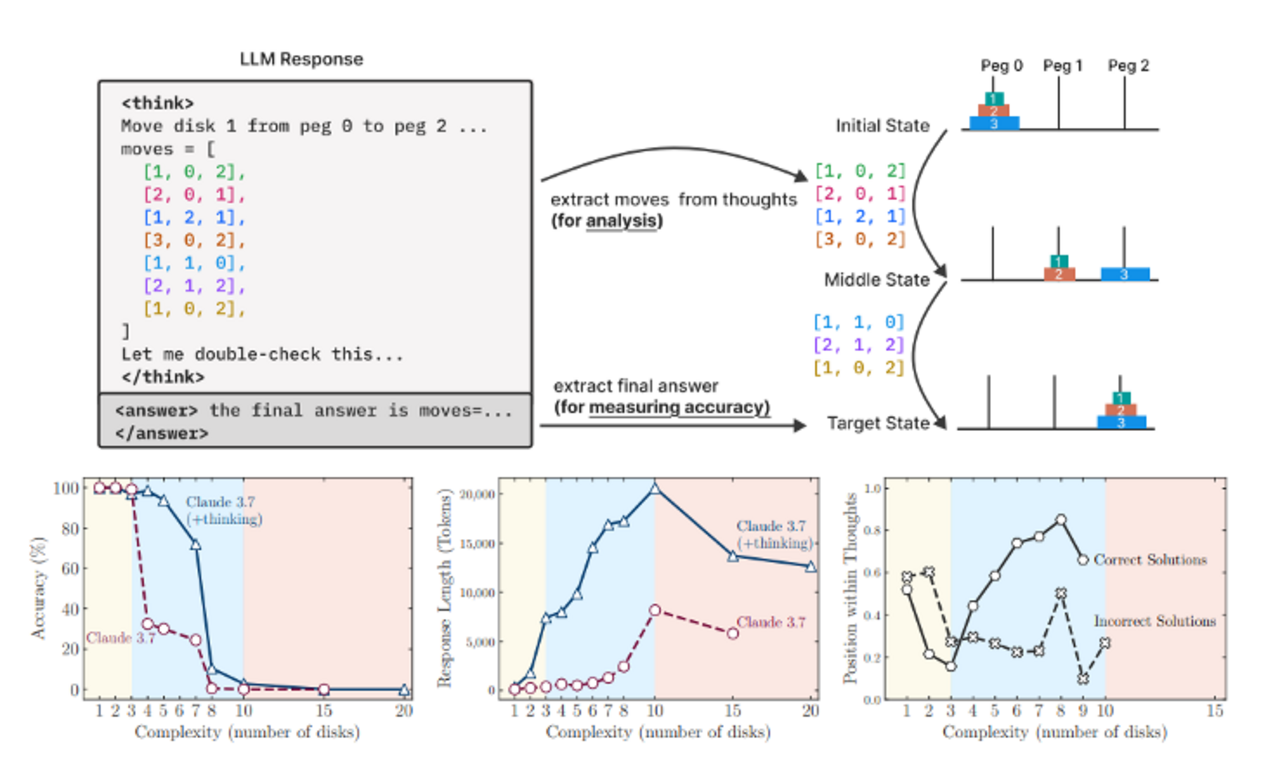
Eine strukturierte Evaluierung: Tower of Hanoi
Ein zentraler Beitrag des Apple-Papers „The Illusion of Thinking“ war der Vorschlag, Reasoning-Traces anhand kontrollierbarer, algorithmischer Aufgaben zu untersuchen. Ziel war es, nicht nur das Endergebnis, sondern auch die Zwischenschritte des Modells zu analysieren.
Dazu verwendeten die Autor:innen Puzzles wie Tower of Hanoi, River Crossing, Blocks World und Checkers Jumping. In diesen kontrollierten Umgebungen konnten sie die Komplexität der Aufgaben systematisch variieren und prüfen, wie sich Sprachmodelle mit und ohne Chain-of-Thought-Verarbeitung dabei schlugen.
Ihre Ergebnisse lassen sich in drei Leistungsbereiche einteilen:
Niedrige Komplexität: Klassische LLMs ohne Reasoning schnitten besser ab. Modelle mit Reasoning neigten zum „Overthinking“ und verkomplizierten einfache Aufgaben unnötig.
Mittlere Komplexität: Hier konnten Reasoning-Modelle ihre Stärken ausspielen und erreichten höhere Genauigkeit.
Hohe Komplexität: Sowohl klassische LLMs als auch Reasoning-Modelle versagten vollständig – die Genauigkeit fiel auf null.
Ein besonders bemerkenswerter Effekt war, dass die Modelle ab einem bestimmten Schwierigkeitsgrad weniger Reasoning-Tokens verwendeten - obwohl sie könnten, hörten sie früher auf – ein implizites „Aufgeben“.
Selbst wenn das Modell mit dem korrekten Algorithmus (z. B. für Tower of Hanoi) im Prompt versorgt wurde, gelang es nicht, ihn auszuführen. Die Autor:innen folgern daraus, dass es an echtem logischen Verständnis fehle und dass Reasoning eher als Performance-Hack statt als echtes Denken zu verstehen sei.
Kritik: Algorithmische Skalierung ist kein Test für Schlussfolgern
So interessant das Setup ist: Die Argumentation des Papers „The Illusion of Thinking“ wirkt an mehreren Stellen verzerrt. Der Tower of Hanoi ist kein guter Test für allgemeines Schlussfolgern, sondern ein deterministisches Algorithmusproblem. Hat man den Algorithmus einmal verstanden, besteht die Aufgabe aus der mechanischen Abarbeitung einer bekannten Regel.
Das Paper erwähnt nicht explizit, dass die Anzahl der benötigten Schritte exponentiell steigt. Ein Puzzle mit zehn Scheiben verlangt bereits über 1000 Schritte, bei zwanzig Scheiben wären es über eine Million. Dass ein Sprachmodell bei solchen Längen aussteigt, ist weder neu noch überraschend. Wir wissen längst, dass LLMs Schwierigkeiten mit langen Kontexten, persistentem Speicher und komplexer Arithmetik haben.
Entsprechend ist es wenig überraschend, dass ein Modell versagt, wenn es Aufgaben wie 1 + 1 + 1 + ... (tausendfach) lösen soll. Das ist keine Komplexität im Sinne von logischem Schlussfolgern, sondern schlicht eine Frage von Länge, Gedächtnis und Iteration.
Dazu kommt: Für Aufgaben dieser Art gibt es bereits bessere Architekturen. Systeme wie AlphaCode oder AlphaEvolve kombinieren Sprachmodelle mit Codeausführung und Feedback-Loops. Das Sprachmodell schreibt Code, dieser wird ausgeführt, und das Ergebnis fließt in die Optimierung ein. In solchen Setups sind LLMs sehr wohl in der Lage, Tower-of-Hanoi-Probleme korrekt zu lösen.
Das bedeutet nicht, dass Reasoning-Traces nutzlos sind. Aber es bedeutet, dass man sie nicht mit skalierten Algorithmusaufgaben testen sollte, wenn man Aussagen über allgemeines Denkvermögen treffen will.
Denn bei aller Kritik: Die eigentliche Schwäche liegt hier nicht im Modell, sondern in der Wahl des Benchmarks.
Die Polarisierung macht alles schlimmer
Leider ist der Umgang mit diesen Ergebnissen in der öffentlichen Debatte nicht besonders produktiv. Insbesondere auf Social Media scheint es nur zwei Lager zu geben:
Die Optimisten:
Reasoning-Modelle sind der nächste große Durchbruch. Sie „denken“ im Grunde wie Menschen, sind logisch, erklärbar und können bald jede Aufgabe lösen – wir brauchen nur noch ein paar Parameter mehr.
Die Zyniker:
Reasoning ist ein Hype. LLMs sind und bleiben stochastische Papageien. Chain-of-Thought ist nichts als ein billiger Trick, der nur vorgibt, eine echte Denkstruktur zu erzeugen.
Beide Lager liegen falsch.
Die Realität ist komplizierter – aber spannender
Sprachmodelle sind Werkzeuge. Und wie bei allen Werkzeugen kommt es auf den Kontext an.
Chain-of-Thought Reasoning ist in vielen Anwendungsfällen hilfreich, aber nicht zuverlässig. Sprachmodelle sind nicht robust – ihre Antworten zeigen eine hohe Varianz, und genau deshalb kann man mit ihnen sowohl beeindruckende Erfolge als auch katastrophale Fehlschläge erzeugen.
Gerade deswegen funktionieren LLMs derzeit am besten als Teil eines größeren Systems:
- In Kombination mit menschlichen Expert:innen, die interpretieren, prüfen und eingreifen
- Oder in automatisierten Pipelines mit klaren Verifikationsschritten, bei denen einzelne Aussagen getestet werden können.
Wie man Reasoning-Traces wirklich verstehen sollte
Ein häufiger Fehlschluss:
Weil ein Sprachmodell ein komplexes Problem erst durch einen längeren Reasoning-Trace erfolgreich löst, wird oft angenommen, es sei innerhalb seiner Schlussfolgerungskette systematisch auf eine Lösung gestoßen, deren Struktur es vorher nicht kannte. Doch das ist nicht zwingend der Fall.
Eine bessere Analogie:
Wenn ich vergessen habe, wo meine Brille liegt, erinnere ich mich nicht sofort an den Ort. Stattdessen gehe ich Schritt für Schritt meine letzten Handlungen durch, überlege, wo ich zuletzt war – und mit etwas Glück erinnere ich mich. Das ist kein neues Wissen, sondern ein Navigieren durch bekannte Muster. Reasoning-Traces funktionieren wahrscheinlich ähnlich.
Die oft etwas ziellosen, redundanten Pfade sind vermutlich ein Nebeneffekt des Trainingsprozesses. Beim Reinforcement Learning werden Modelle nur eingeschränkt bestraft, wenn sie zu viele Schritte machen - solange die Endantwort stimmt. Im Gegenteil: Längere Reasoning-Traces bieten statistisch mehr Gelegenheit, zufällig auf einen korrekten Pfad zu stoßen. Daher entsteht keine saubere, logische Argumentation, sondern ein explorativer Pfad durch bekannte Strategien.
Zwischen Generalisierung und Auswendiglernen
Gegner von Chain-of-Thought argumentieren, dass die Traces nur auswendig gelernt sind. Auch das ist zu kurz gedacht.
LLMs sind stochastische Systeme. Sie können auf neue Probleme mit einer nicht-null Wahrscheinlichkeit korrekt reagieren, auch wenn diese nicht explizit im Training enthalten waren. Das zeigt:
- Die Modelle lernen abstrakte Repräsentationen.
- Sie können Lösungsstrategien kombinieren und extrapolieren – allerdings mit abnehmender Zuverlässigkeit, je weiter ein Problem vom Training entfernt ist.
Fazit: Weder Wundermaschine noch Papagei
Sprachmodelle sind keine denkenden Wesen. Aber sie sind auch nicht bloß statistische Plapperautomaten.
Chain-of-Thought Reasoning zeigt, dass man LLMs nützliche, heuristische Lösungsstrategien beibringen kann – ohne dass dabei ein konsistentes „Denken“ im menschlichen Sinn entsteht.
Deshalb gilt:
- Reasoning-Traces sind hilfreich - Sie helfen beim Lösen komplexer Probleme.
- Sie können Hinweise geben - aber keine echte Transparenz liefern.
- Sie sind Ausdruck von Musterexploration – nicht von Schlussfolgern im strengsten Sinn.
Was mich an einem Teil der Kritik an Reasoning-Traces stört, ist ihr Idealbild von Schlussfolgerung:
Es wird implizit gefordert, dass die Gedankengänge eines Sprachmodells effizient, zielgerichtet, korrekt und logisch sauber sein sollten – wie in einem mathematischen Beweis. Doch wenn ich ehrlich darüber nachdenke, wie mein eigenes Denken beim Lösen komplexer, ungewohnter Probleme abläuft, sieht das oft ganz anders aus: Es ist explorativ, manchmal wirr, voller Umwege, Sprünge und Widersprüche. (Wie Leser:innen vielleicht schon an der Struktur dieses Artikels erahnen können)
Ich halte wenig von direkten Vergleichen zwischen der Arbeitsweise von Menschen und Sprachmodellen - dafür sind die Unterschiede zu grundlegend. Aber wenn wir diesen Vergleich schon bemühen, dann sollten wir zumindest mit demselben Maßstab messen.
Datum: 14.07.2025
Bildquelle: KI-generiert mit VEO
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.