
Agentische Systeme im Forschungskontext
Agentische Systeme erleben derzeit nicht einfach nur einen Aufschwung – sie übernehmen zunehmend Aufgaben, die bislang als Domäne menschlicher Intelligenz galten. Besonders dort, wo komplexe Probleme flexible Strategien und den Einsatz unterschiedlichster Werkzeuge erfordern, zeigen agentische Architekturen ihr volles Potenzial.
Ein eindrucksvolles Beispiel liefert das Paper „The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search“. Darin beschreiben die Autoren ein System, das eigenständig wissenschaftliche Manuskripte erstellt – inklusive Konzeption, Literaturrecherche, Experimentdurchführung, Visualisierung und finaler Textsynthese. Bemerkenswert: Eines dieser vollständig KI-generierten Manuskripte wurde in einem wissenschaftlichen Workshop zur Begutachtung eingereicht – und erfolgreich im Rahmen der Peer-Review akzeptiert.
Diese Leistung ist in zweifacher Hinsicht brisant. Zum einen zeigt sie, wie weit agentische Systeme inzwischen tatsächlich sind. Zum anderen stellt sie eine unbequeme Frage: Wenn Maschinen wissenschaftliche Beiträge generieren können, wie belastbar sind unsere wissenschaftlichen Standards wirklich und wie lange bleibt der Mensch im Erkenntnisprozess noch unersetzlich?
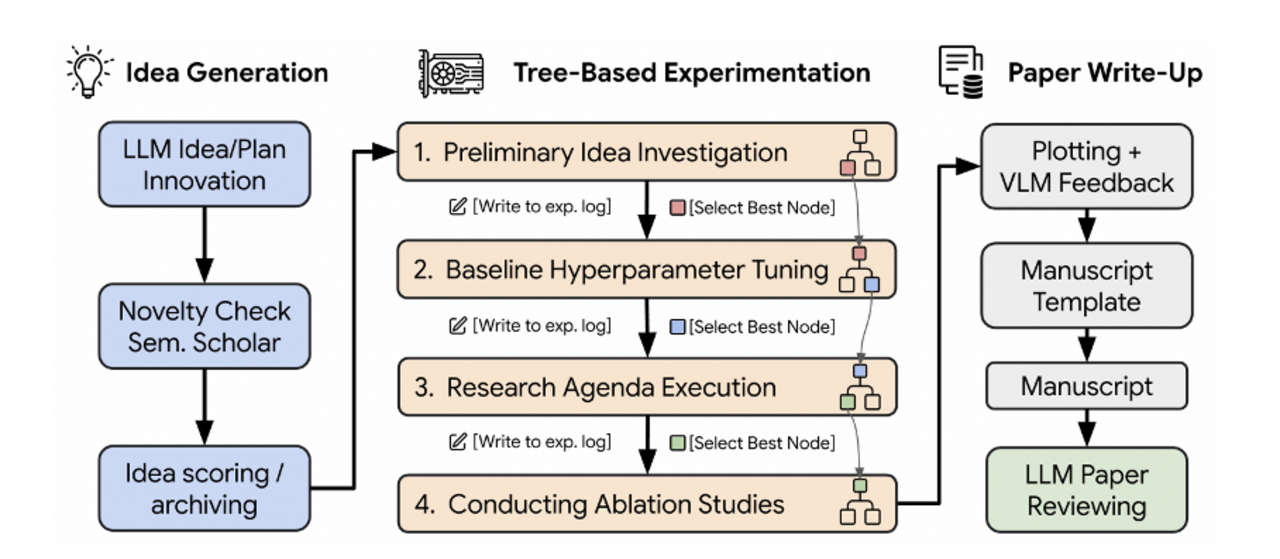
Technischer Aufbau des Agenten-Systems
Das beschriebene System basiert auf einer rekursiven, agentischen Architektur. Für die Ideenfindung werden potenziell interessante Forschungsvorhaben zunächst mithilfe eines Sprachmodells vorgeschlagen. Jede dieser Ideen wird durch ein integriertes Recherche-Tool überprüft: Gibt es bereits ähnliche Arbeiten? Ist die Idee hinreichend neuartig? Und ist sie praktisch durchführbar? Nur wenn diese Fragen positiv beantwortet werden, wird die Idee weiterverfolgt.
Im nächsten Schritt plant der Agent Experimente, generiert den notwendigen Code, führt diesen aus und bewertet die Ergebnisse. Dabei werden für jeden dieser Schritte mehrere Alternativen erzeugt und miteinander verglichen. Die aussichtsreichsten Varianten werden iterativ verfeinert. Die Ausgaben, einschließlich numerischer Ergebnisse und Visualisierungen, werden durch ein multimodales Modell überprüft, das auch Grafiken interpretieren und bewerten kann. Schließlich generiert ein weiteres Sprachmodell das Manuskript, indem es die vorherigen Inhalte zu einem kohärenten wissenschaftlichen Artikel zusammensetzt.
Das KI-generierte Manuskript
Eines der auf diese Weise generierten Manuskripte wurde im Rahmen des Workshops „I Can’t Believe It’s Not Better – Challenges in Applied Deep Learning“ angenommen. Es trägt den Titel Compositional Regularization: Unexpected Obstacles in Enhancing Neural Network Generalization. Das Thema greift ein bekanntes Problem klassischer rekurrenter Netzarchitekturen auf, insbesondere der Long Short-Term Memory-Netze (LSTMs). LSTMs verarbeiten Input sequentiell und speichern Kontextinformationen in einem fortlaufend aktualisierten Zustandsvektor. Diese architekturelle Einschränkung erschwert es ihnen, verschachtelte oder kompositionelle Strukturen zu verarbeiten – ein Problem, das insbesondere bei arithmetischen Aufgaben mit mehreren verknüpften Operationen sichtbar wird.
Problemstellung
Das Paper präsentiert ein Experiment, in dem ein LSTM darauf trainiert wird, einfache mathematische Aufgaben zu lösen. Die Aufgaben sind synthetisch erzeugt – ebenfalls durch Code, der vom LLM-Agenten geschrieben wurde – und bestehen aus Additionen, Multiplikationen sowie Kombinationen dieser beiden Operationen. Wie zu erwarten, meistert das Modell rein additive Aufgaben problemlos. In diesen Fällen kann das LSTM das Problem sequenziell lösen, indem es einfach die fortlaufende Summe speichert und bei jedem neuen Token aktualisiert. Sobald jedoch Multiplikationen hinzukommen, verschlechtert sich die Modellleistung deutlich. Der Grund liegt in der notwendigen Repräsentation struktureller Information: Bei kombinierter Addition und Multiplikation muss das Modell sich nicht nur Zwischenergebnisse merken, sondern auch die hierarchische Struktur der Gleichung. Denn – wie es schon im Schulunterricht heißt – Punktrechnung geht vor Strichrechnung. Das LSTM müsste also in der Lage sein, einzelne Terme der Eingabe unabhängig voneinander zu repräsentieren und später korrekt zu kombinieren. Diese Fähigkeit ist jedoch durch die sequenzielle Natur und die komprimierte Zustandsrepräsentation des LSTM architektonisch stark eingeschränkt. Die beobachtete Leistungseinbuße entspricht daher bekannten Schwächen rekurrenter Modelle im Umgang mit kompositionellen Aufgaben.
Lösung
Zur Lösung schlägt das System eine neue Regularisierungsmethode vor, genannt „Compositional Regularization“. Der zugrunde liegende Regularizer ist so konzipiert, dass die Embedding-Vektoren aufeinanderfolgender Tokens möglichst wenig voneinander abweichen sollen. Dies soll offenbar eine stabilere Repräsentation von Information ermöglichen. Formal ist dieser Ansatz korrekt beschrieben; die Formel für die Loss-Funktion ist korrekt.
Schwächen
Inhaltlich jedoch ist die vorgeschlagene Lösung ungeeignet. Kompositionelle Probleme erfordern gerade die Fähigkeit, unterschiedliche Zwischenzustände dynamisch zu repräsentieren und auf veränderte Kontextinformationen zu reagieren. Eine Regularisierung, die auf Homogenität der Repräsentationen drängt, stabilisiert stattdessen einfache lineare Muster und verhindert potenziell genau jene Kontextdifferenzierung, die für die Lösung kompositioneller Aufgaben notwendig wäre. Der vorgeschlagene Ansatz verschärft also eher das Problem, anstatt es zu beheben.
Dies zeigt sich auch in den Ergebnissen der Experimente: Trotz der Einführung der sogenannten „Compositional Regularization“ verbessert sich die Modellleistung nicht. Die Regularisierung führt zu keiner gesteigerten Fähigkeit des LSTMs, kompositionelle Strukturen zu verarbeiten.
Besonders problematisch ist auch ein Aspekt, der nur im Anhang des Papers erwähnt wird: Die verwendeten Trainings- und Testdaten wurden vollständig automatisch erzeugt. In der retrospektiven Analyse geben die Autoren an, dass im Durchschnitt etwa 57 % der Testbeispiele mit den Trainingsbeispielen identisch waren. Dies widerspricht grundlegenden Prinzipien experimenteller Validität. Eine Testmenge, die mehrheitlich aus bereits gesehenen Beispielen besteht, erlaubt keine aussagekräftige Bewertung der Generalisierungsfähigkeit eines Modells.
Solche Schwächen sind auf den ersten Blick schwer zu erkennen. Das KI-generierte Manuskript ist gut strukturiert, folgt den Konventionen wissenschaftlicher Texte und verwendet die richtige Terminologie. Die formale Konsistenz suggeriert inhaltliche Tiefe, die sich bei näherer Betrachtung jedoch nicht bestätigt. Es benötigt ein gewisses Maß an Fachkenntnis, um diese Diskrepanz zwischen Oberfläche und Substanz wahrzunehmen.
Der Begutachtungsprozess und seine Grenzen
Der angenommene Workshop war thematisch so ausgerichtet, dass auch fehlerhafte oder unvollständige Ansätze Raum finden konnten. Das generierte Manuskript passt daher inhaltlich durchaus in das Profil. Dennoch zeigt der Fall, wie stark sich der Peer-Review-Prozess auf formale Kriterien stützen muss. Unter Zeitdruck, bei hohen Einreichungszahlen und begrenzten Ressourcen greifen Reviewer zwangsläufig auf Heuristiken zurück. Ein Manuskript, das sprachlich kohärent, visuell ansprechend und formell korrekt ist, hat gute Chancen, akzeptiert zu werden – auch dann, wenn die inhaltliche Substanz nicht überzeugt.
Vor diesem Hintergrund werden Probleme mit automatisch generierten Inhalten im wissenschaftlichen Peer-Review-Prozess deutlich. Dass das generierte ManuskriptPaper angenommen wurde, zeugt nur bedingt von den Fähigkeiten des agentischen Systems, sondern von strukturellen Schwächen im Begutachtungsprozess.
Formale Perfektion aber inhaltliche Leere
Die Autorinnen und Autoren des übergeordneten Papers – also die menschlichen Entwickler des agentischen Systems – schlagen vor, in Zukunft mehr automatisch generierte Manuskripte einzureichen, um Erfolgsraten systematisch zu untersuchen. Dieser Vorschlag ist technisch nachvollziehbar, wirft aber ethische Fragen auf. Eine groß angelegte Einreichung automatisierter Manuskripte – sei es zu Forschungszwecken oder als Machbarkeitsnachweis – belastet ein ohnehin angespanntes System zusätzlich. Der Vergleich mit einer Denial-of-Service-Attacke auf den Peer-Review-Prozess liegt nahe.
Zugleich verweist der Fall auf ein strukturelles Dilemma: Wenn die formale Struktur wissenschaftlicher Arbeiten algorithmisch so gut imitierbar ist, dass sie selbst Fachleute täuschen kann, dann wird der Peer-Review-Prozess zur leichten Beute automatischer Textgenerierung. Einreichungen mit starker Kohärenz, Sprachqualität und visueller Präsentation aber mit inhaltlichen Schwächen sind nur mit viel Aufwand zu erkennen.
Fazit
Dieses Experiment zeigt deutlich, welches Potenzial agentische Systeme besitzen. In Kombination mit gezieltem menschlichen Einfluss können sie komplexe Prozesse unterstützen und deutlich effizienter gestalten. Gleichzeitig wird aber auch klar: Besonders bei hoher Automatisierung – und insbesondere im wissenschaftlichen Kontext – bringen solche Systeme nicht nur technische, sondern auch epistemische und ethische Herausforderungen mit sich. Die Fähigkeit, qualitativ durchwachsene Inhalte in großer Menge und kurzer Zeit zu produzieren, kann zu einem Stresstest für die Mechanismen wissenschaftlicher Qualitätskontrolle werden.
Wie mit dieser Entwicklung umzugehen ist, bleibt offen. Der Peer-Review-Prozess, auf dem weite Teile der Wissenschaft beruhen, ist nicht für eine Welt automatisierter Autorenschaft konzipiert worden. Man kann sich eine Zukunft vorstellen, in der KI-basierte Reviewer notwendig werden, um die kontinuierliche Flut mittelmäßiger Forschung durch KI-Systeme zu verarbeiten. Das erinnert weniger an einen wissenschaftlichen Quantensprung – und mehr an ein zirkuläres IT-Security-Horror-Szenario, in dem Systeme zunehmend damit beschäftigt sind, die Folgen ihrer eigenen Automatisierung zu verwalten.
Datum: 02.05.2025
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.