Für ein präzises Entity Linking mit Doccano hat ontolux das Open-Source-Annotationstool um eine direkte Anbindung an unser hauseigenes Textanalyse-Framework TXTWerk erweitert. Dieser spezielle Fork ermöglicht es uns, maßgeschneiderte Annotationen für komplexe Disambiguierungs-Tasks zu erstellen.
Maschinelle Lernverfahren benötigen Trainingsdaten
Maschinelle Lernverfahren benötigen Trainingsdaten, die meist auch gelabelt sein müssen. Für das Labeling solcher Daten existieren bereits zahlreiche Tools zur Annotation. Viele bieten unterschiedliche Annotationsprojekte, wie Textklassifikation, Sequence Labeling, NER oder Text zu Text. Aus diesem Grund konnte an ein bestehendes Projekt angeknüpft werden, sodass keine komplette Neuimplementierung notwendig war. Das spart Zeit und verbessert das Ergebnis.
Unsere Kundenprojekte benötigen ebenfalls gelabelte Daten, um mithilfe von Machine Learning-Modellen aus vorhandenen Textdaten einen Mehrwert für das Unternehmen schöpfen zu können. Öffentlich verfügbare Daten, wie Wikipedia und Wikidata, bieten zwar eine solide Basis, aber diese reichen nicht aus, um individuelle Projekte oder Kundenwünsche abzubilden. Ein konkreter Anwendungsfall, bei dem es gelabelter Daten bedarf, sieht bei uns wie folgt aus:
Trainierte NER-Modelle bieten bereits viele Möglichkeiten: zum Beispiel kann solch ein Modell Thomas Müller als Person einordnen. Jedes Verfahren hat jedoch seine Grenze, die im Fall von NER bei der konkreten Zuordnung, der Disambiguierung, liegt: Wikipedia allein verzeichnet 36 Personen mit diesem Namen. Also, welcher Thomas Müller ist gemeint? Der bekannte Fußballspieler, der Schweizer SVP-Politiker oder der Unternehmer? Die Antwort gibt der Kontext vor, in dem Thomas Müller vorkommt. Die Herausforderung dabei ist, dass ein Computer Texte nicht verstehen wie ein Mensch kann. Hierfür können maschinelle Lernverfahren trainiert werden, um eine Disambiguierung durchzuführen, und diese Verfahren benötigen gelabelte Trainingsdaten. TXTWerk bietet hierfür eine Lösung und bildet in vielen Projekten damit einen wichtigen Baustein mit seinen Fähigkeiten, insbesondere bei der Erkennung bekannter Entitäten, dem sogenannten Entity Linking. Aus diesem Grund brauchten wir eine Möglichkeit, Entity Linking Daten mit einer Verbindung zu TXTWerk zu erstellen.
Um ein geeignetes Tool zu finden, das gut an TXTWerk angebunden werden kann, mussten zunächst Anforderungskriterien erstellt werden. Für uns waren folgende Kriterien entscheidend:
On-Premise Installation
Nutzung vorannotierter Daten
aktive Entwicklung
Nutzermanagement
Nutzerfreundlichkeit
keine oder möglichst niedrige Kosten in der Nutzung
Um eine geeignete Basis zu finden, evaluierten und testeten wir mehrere vorhandene Annotationsprogramme: Prodigy, INCEpTION, Doccano, Textae, Brat, Dandelion und Dataturks. Proprietäre Lösungen sind schwierig anzupassen und fielen aus diesem Grund schnell aus der Auswahl (Prodigy, Dandelion), auch wenn sie für viele Tasks sehr gute Lösungen bieten. Bei anderen Projekten fand schon seit längerer Zeit keine Weiterentwicklung mehr statt, sodass zwei Anwendungen in die Endauswahl kamen: INCEpTION und Doccano. Doccano konnte hier mit seiner einfachen Handhabung, Installation, einer sehr aktiven Community und der Möglichkeit schnell und einfach zu annotieren (zum Beispiel durch Label Shortcuts) am Ende überzeugen.
Doccano Features
Doccano bietet ein breites Spektrum an Features, wobei die Usability immer mitgedacht wird. Das beginnt bei der Installation, die je nach Anforderung unterschiedlich (Docker, Pip, AWS, Heroku) durchgeführt werden kann. Doccano wird einfach im Browser ausgeführt und unterstützt in der Weboberfläche insgesamt vier Sprachen (Englisch, Deutsch, Französisch, Chinesisch). Es stehen vonseiten des Hauptprojektes insgesamt fünf Annotationsprojekttypen zur Auswahl, die teils mehrere Einstellmöglichkeiten zulassen:
Textklassifikation
Sequenz Labeling
überlappende Sequenzen
Relationen zwischen Labeln
Sequenz zu Sequenz
Bildklassifikation
Audio zu Text
Für uns als ontolux ist Textklassifikation und Sequenz Labeling wichtig, da hiermit die Annotation von Sequenzen in Textdokumenten, zum Beispiel NER (Named Entity Recognition), vorgenommen werden kann.

In der Projektarbeit verwenden wir dies bereits, um Finetuning von bereits existierenden Modellen durchzuführen, sodass viele Kundenwünsche effektiv umgesetzt werden können. Jedoch fehlt noch ein weiterer wichtiger Baustein: Entity Linking mit Anbindung an TXTWerk.
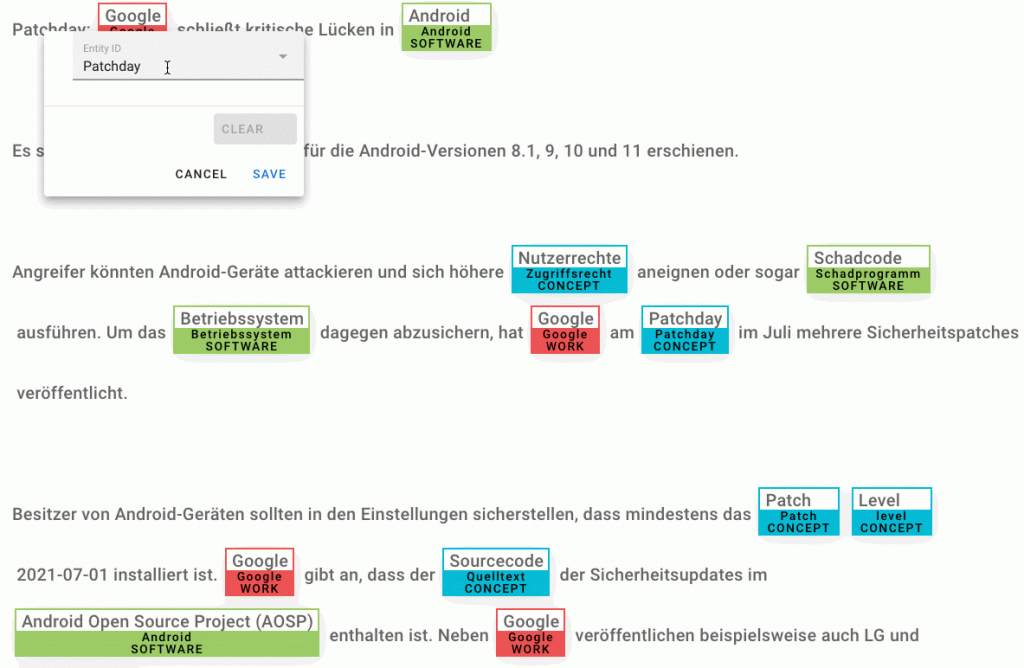
Entity Linking mit Doccano und TXTWerk
Workflow für das Entity Linking mit Doccano
Doccano unterstützt bisher noch kein Entity Linking, das heißt, dass Sequenzen (Wörter oder Wortgruppen) feste IDs bekommen und damit konkret einer Entität zuordenbar sind. Das TXTWerk-Lexikon enthält alle Wikidata-Einträge, die mit Wikipedia verknüpft wurden und in den von TXTWerk unterstützten Sprachen (Deutsch, Englisch) existieren. Das Lexikon bietet die Möglichkeit der kundenspezifischer Erweiterung, dass auch Entitäten, die in den Basisdaten nicht existieren, aber für Kunden relevant sind, aufgenommen werden können. Für das Labeling ergibt sich hierdurch natürlich das Problem, dass eine sehr hohe Anzahl von Labeln/IDs existiert (mehr als eine Million), zu denen auch noch bestimmte Informationen gespeichert und abgerufen werden müssen, wie zum Beispiel Name, Beschreibung, Flexionen oder andere Schreibweisen (Oberflächenformen).
Diese Features bietet Doccano nicht, sodass sie von ontolux eigens für die Verwendung mit TXTWerk implementiert wurden. Dafür waren Erweiterungen im Backend und Frontend notwendig. Die Einarbeitung und Implementierung war innerhalb weniger Monate möglich, da Doccano etablierte Standardtechnologien wie Postgre, Python und Django im Backend und VueJS für das Frontend nutzt. Das Ergebnis ist ein neuer Projekttyp für Entity Linking der Projekterstellung.
Die Annotation soll dabei möglichst einfach und übersichtlich vorgenommen werden können, weshalb nicht die ID einer Entität angezeigt werden soll, sondern der Name und der zugehörige Typ (zum Beispiel Organisation, Person, Ort). Klickt man eine gelabelte Sequenz an, öffnet sich eine Detailansicht, die weitere Informationen liefert. Das Erstellen eines neuen Labels erfolgt per Mausklick auf die gewünschte Sequenz. Es erscheint ein Menü, das die 5 besten Treffer aus TXTWerk für die Oberflächenform ausgibt. Ist der gewünschte Eintrag nicht dabei, hat der Nutzer zwei Möglichkeiten. Zum einen kann eine passende Oberflächenform eingegeben werden, sodass TXTWerk andere Entitäten anzeigt, zum anderen kann eine konkrete ID für die Entität eingegeben werden. So besteht auch die Möglichkeit, nicht oder selten angezeigte Verknüpfungen möglichst schnell herzustellen.
Kurz und Knapp
Doccano erweitert die Möglichkeiten von ontolux in Projekten und mit Kunden Trainingsdaten individuell zu annotieren und später zu trainieren. Dies gilt für alle Projekttypen, die Doccano standardmäßig zur Verfügung stellt – Dokumentklassifikation, Sequenz-Labeling, Sequenz-zu-Sequenz, Bildklassifikation, Audio-zu-Text – plus das zusätzlich implementierte Entity Linking mit TXTWerk-Anbindung. Das ganze kann On-Premise auf Servern von ontolux oder Kunden installiert werden.
Unsere Kundenprojekte benötigen gelabelte Daten, um einen echten Mehrwert schöpfen zu können. In unserer KI-Beratung sehen wir immer wieder, dass Standarddaten wie Wikipedia oft nicht ausreichen.
Datum: 22.04.2022
Autor

Gerhard Haß
Gerhard Haß ist Machine Learning Engineer bei der Neofonie. Der studierte Computerlinguist und Kunsthistoriker arbeitet seit Jahren in der Softwareentwicklung. Er ist für die Entwicklung von Tools, Machine Learning-Modellen und Datenanalyse bei ontolux verantwortlich.