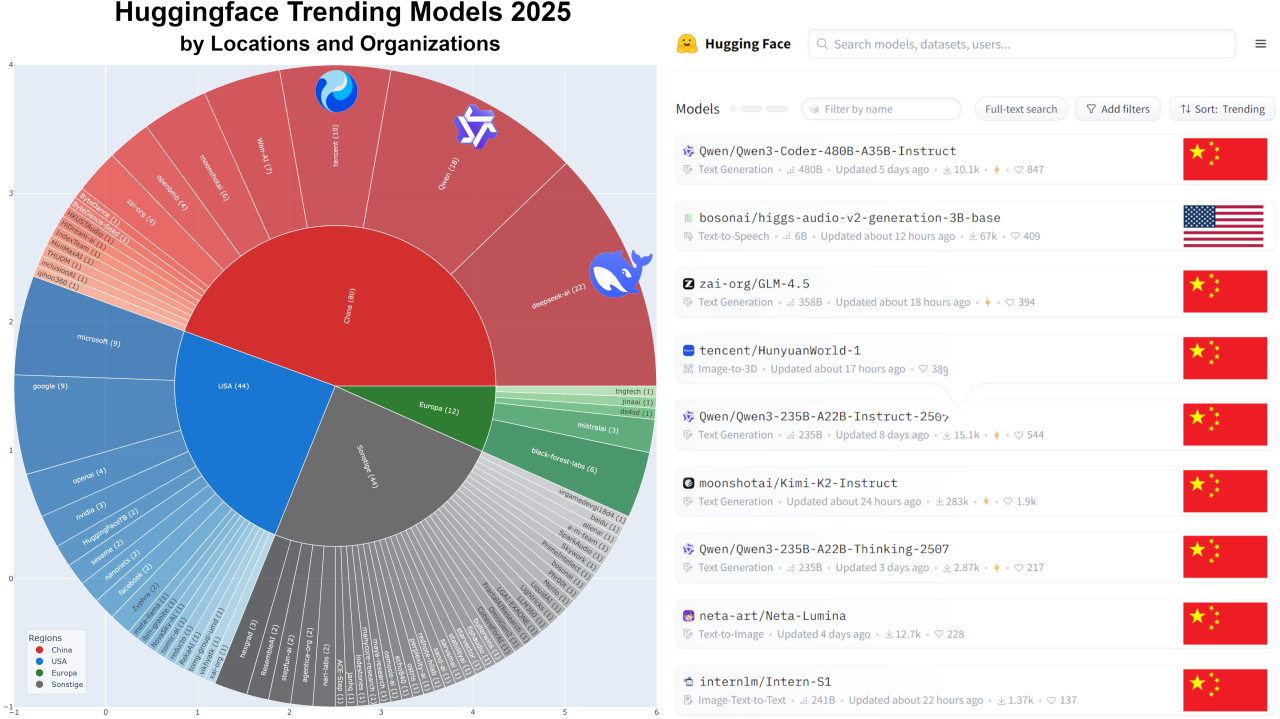
Eine Analyse der Top Trending Modelle auf Hugging Face über das letzte Jahr hinweg zeichnet ein klares Bild: China dominiert die Open-Source-KI-Welt. Namen wie DeepSeek, Alibaba Research und Tencent tauchen immer wieder auf, während westliche Player zunehmend ins Hintertreffen geraten.
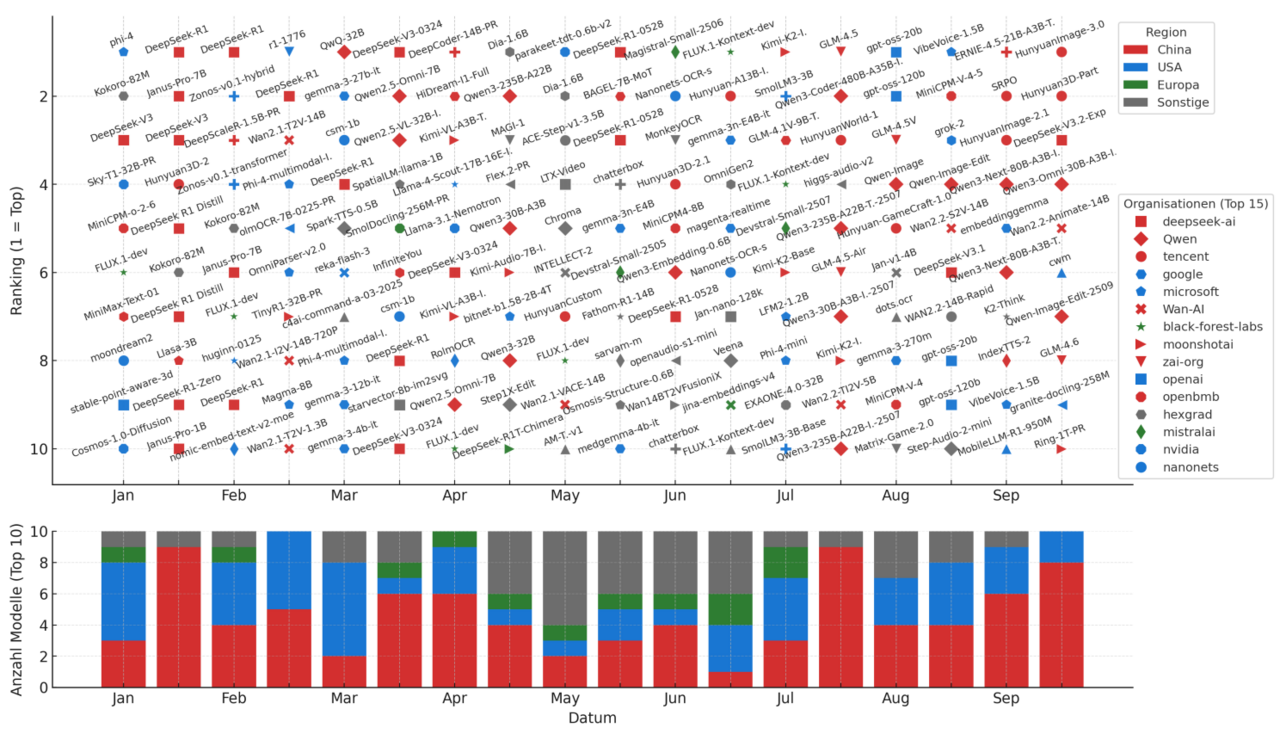
Es geht hier nicht um proprietäre Systeme wie GPT-5 oder Claude 4.5. Sondern um Open-Weights-Modelle – frei zugängliche Systeme, die jeder hosten, untersuchen und anpassen kann. Genau hier hat China die Führung übernommen.
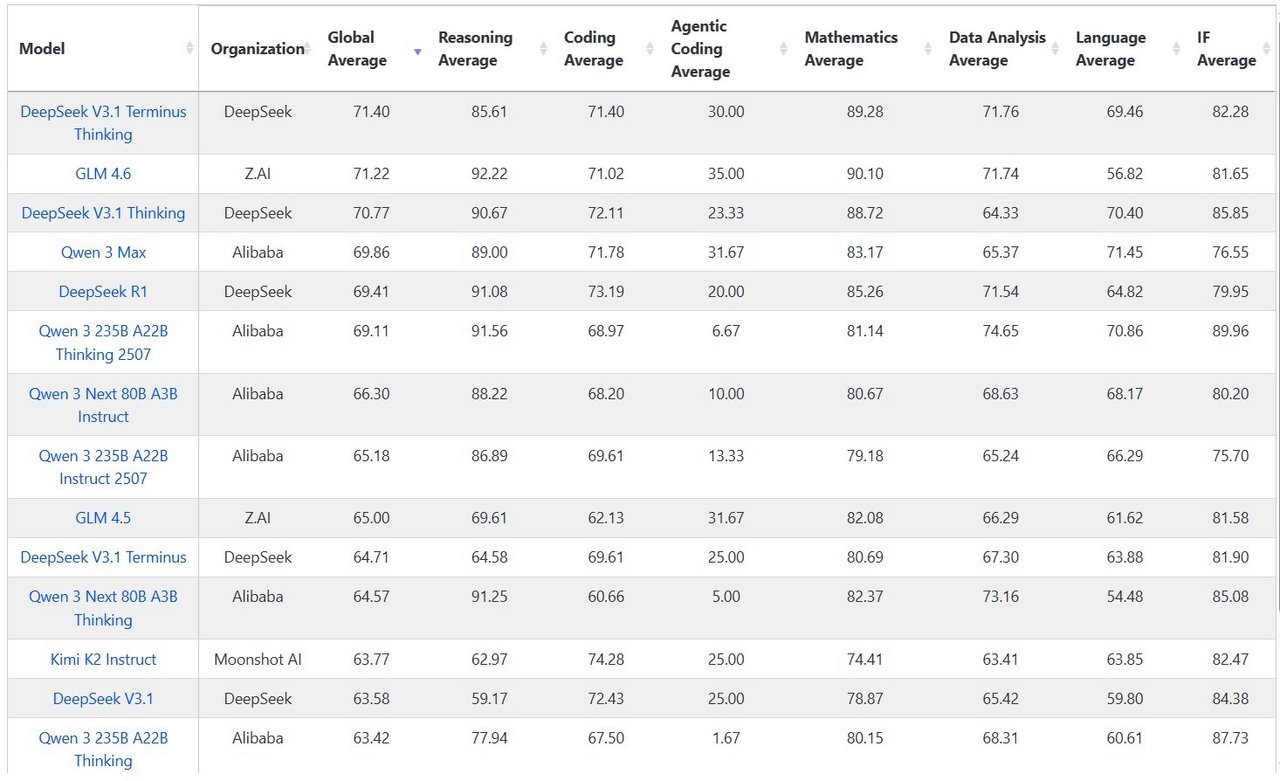
Spätestens seit Qwen 2.5 Instruct 72B (Alibaba, September 2024) hat sich das Kräfteverhältnis verschoben. Das Modell übertraf Llama 3.1 Instruct 405B in zentralen Benchmarks – und das bei deutlich geringerer Größe. Seitdem sind die stärksten Open-Weights-Modelle, die man heute für souveräne Anwendungen hosten kann allesamt chinesisch.
Die einzige westliche Ausnahme wäre vielleicht OpenAIs „GPT-OSS“ – aber auch das ist umstritten. Eine aktuelle Analyse Is GPT-OSS Good? zeigt: Die exzellenten Benchmark-Ergebnisse von GPT-OSS könnten irreführend sein – durch Overfitting auf öffentliche Testdaten und multilinguale Fähigkeiten lassen auch zu wünschen übrig. Auf Live-Bench, welches aktiv gegen Datenkontamination vorgeht, landet GPT-OSS nur im mittleren Feld.
Offenheit – Strategie oder aus Prinzip?
Doch Offenheit ist nicht automatisch Altruismus. Open-Weights-Modelle sind auch ein strategisches Werkzeugs – eine Möglichkeit für Firmen, die beim proprietären Wettrennen (noch) nicht ganz oben mitspielen, sich über die Community zu positionierenund Sichtbarkeit aufzubauen.
Metas LLaMA ist ein gutes Beispiel dafür: Das erste Modell wurde versehentlich geleakt, später dann offiziell freigegeben, als klar wurde, wie viel Aufmerksamkeit und Forschung sich dadurch erzeugen lässt.
Aber während westliche Firmen meist nur Modelle veröffentlichen, gehen chinesische Labs weiter: Sie teilen auch die Trainingsmethoden – also das eigentliche Wie hinter ihren Erfolgen.
Fünf Forschungsinnovationen, die Chinas Aufstieg prägen
China ist längst nicht mehr das Land der billigen Arbeitskräfte und Patentnachahmer, als das es im Westen oft dargestellt wurde. Der eigentliche Grund für Chinas wissenschaftlichen Aufstieg liegt in der Innovationskraft seiner Forschungslabore. Während die USA versuchen, den Export wichtiger GPU- und TPU-Chips nach China zu begrenzen, hat das Land genau daraus eine Art Innovationsbeschleuniger gemacht.
Wie das so oft ist: Druck erzeugt Kreativität. Gerade unter diesen Beschränkungen hat sich Chinas KI-Szene mit noch mehr Energie in das Feld gestürzt – gezwungen, effizientere Trainingsstrategien, stabilere Reinforcement-Learning-Pipelines und effiziente multimodale Systeme zu entwickeln.
Hier sind fünf Forschungsinnovationen, die diesen Aufstieg besonders geprägt haben – und die wir im Detail betrachten sollten:
Reinforcement Learning ohne Supervised Fine-Tuning – DeepSeek R1-Zero
Normalerweise werden Sprachmodelle in zwei Phasen trainiert:
Supervised Fine-Tuning (SFT) – das Modell lernt zunächst aus Beispielen, wie gute Antworten aussehen.
Reinforcement Learning (RL) – danach lernt es durch Belohnung, welche Antworten besser sind.
DeepSeek R1-Zero verzichtet für sein Reasoning-Training komplett auf diese erste Phase. Das Modell startet direkt mit einem Belohnungssignal, das erfolgreiche logische Schritte („Reasoning Chains“) honoriert – ohne vorherige menschliche Labels.
Das Modell zeigte bald mehrstufige Lösungsstrategien, sogenannte Chain-of-Thoughts, und begann, seine eigenen Zwischenschritte zu reflektieren. In den Trainingslogs finden sich Passagen, in denen das Modell etwa schreibt: „Warte – das stimmt so nicht“ und daraufhin den Lösungsweg korrigiert.
Auf komplexen Mathematikaufgaben steigerte sich R1-Zero von rund 15 % auf über 70 % korrekte Antworten – und erreichte mit einem einfachen Mehrheitsvoting über mehrere Versuche sogar über 86 %, also in Reichweite von GPT o1.
Das Ergebnis: weniger menschliche Labels, dafür mehr eigenständig erlernte Struktur im Schlussfolgern. R1-Zero zeigt, dass Reasoning-Verhalten aus dem Lernprozess selbst entstehen kann, ohne direkte Anleitung durch annotierte Daten. Das reine RL-Modell tendierte allerdings zu wirren, teils zweisprachigen Erklärungen.
Group-Relative Policy Optimization (GRPO) – DeepSeek R1
Klassische RL-Verfahren wie PPO benötigen ein zweites Modell („Critic“), das bewertet, wie gut eine Antwort war, indem er den sogenannten Advantage schätzt – also, vereinfacht gesagt, den Unterschied zwischen einer durchschnittlichen Antwort und einer wirklich guten. GRPO vereinfacht diesen Prozess radikal: Statt absolute Werte zu berechnen, vergleicht das Modell einfach mehrere Antworten in einer Gruppe.
Die Formel ist einfach: Jede Antwort erhält eine Belohnung, und das Modell lernt, welche im Vergleich zum Durchschnitt besser ist – ein eleganter Weg, komplexes RL effizienter und stabiler zu machen.
keine separate Value-Funktion,
stabilere Gradienten,
effizienteres RL-Feintuning auch bei großen Modellen.
In vorherigeren KI Journal Clubs sind wir bereits tiefer in diese Arbeiten eingestiegen und haben dort die Grundlagen von Reinforcement-Learning und Reasoning Modellen näher erklärt sowie Kritikpunkte besprochen.
Zweistufige RL: Cascade Reinforcement Learning (Qwen 2.5 & InternVL 3.5)
Die nächste Innovation kommt gleich bei mehreren chinesischen Modellen zum Einsatz: Sowohl Qwen 2.5 als auch InternVL 3.5 nutzen Cascade RL: ein zweiteiliger Ansatz, der das Reinforcement Learning in zwei aufeinander abgestimmte Phasen zerlegt – erst offline, dann online.
Phase 1 – Offline-RL: Das stabile Fundament: In der ersten Phase wird das Modell mit bewerteten Beispielen durch Direct Preference Optimization (DPO) trainiert. Statt aktiv zu experimentieren, lernt es zunächst aus vorhandenen Präferenzdaten, welche Antworten bevorzugt werden – stabil, effizient und ohne riskantes Explorationsverhalten.
Phase 2 – Online-RL: Die interaktive Verfeinerung: In der zweiten Phase darf das Modell frei generieren und erhält für seine Ausgaben Rewards und Penalties in Echtzeit. So lernt es, sein Verhalten adaptiv zu verfeinern – etwa bei ungewöhnlichen Eingaben, ambigen Fragen oder komplexen multimodalen Aufgaben.
Diese zweistufige Struktur erlaubt dem Modell, zuerst grob zu lernen und sich dann gezielt zu verbessern. Im Ergebnis entsteht eine stabile Lernkurve – robust gegen Überanpassung, aber sensibel für feine Verbesserungen.
Offline-DPO bringt das Modell schnell auf Kurs, Online-GRPO liefert den Feinschliff. Das Ergebnis: robustere Lernkurven, weniger Overfitting und bessere Generalisierung – etwa bei InternVL 3.5, das mit dieser Methode +16 % Leistungszuwachs und vierfache Inferenzgeschwindigkeit gegenüber seinem Vorgänger erreichte. Cascade RL zeigt, wie sich klassische Reinforcement-Learning-Prozesse durch einfache Strukturierung effizienter und stabiler gestalten lassen.
Flexible Bildgrößen – Dynamische Auflösung in Vision-Language-Modellen
Ein kleines Bild ist nicht so informationsreich wie ein großes, aber die meisten Architekturen behandelten sie bisher gleich. Qwen VL und InternVL 3.5 begegnen dieser Schwäche über das Konzept der dynamischen Auflösung.
Frühere Systeme mussten Bilder auf eine feste Größe skalieren, etwa 224 × 224 Pixel. Das war einfach, aber ineffizient: kleine Bilder wurden künstlich vergrößert, große verloren Details.
Die neuen Modelle brechen diese Beschränkung. Sie erzeugen variabel viele Bild-Tokens – große, detailreiche Bilder liefern mehr, kleine weniger. Das Modell sieht also dort genauer hin, wo es sich lohnt, und spart Rechenzeit, wenn nicht.
Das bringt zwei klare Vorteile:
Mehr Effizienz, weil nicht jedes Bild auf Maximalauflösung gerechnet wird.
Höhere Präzision, weil feine Details erhalten bleiben.
InternVL 3.5 erweitert das Prinzip mit einem Visual Resolution Router (ViR), der automatisch entscheidet, wie genau ein Bild analysiert wird – ein intelligenter Zoom-Schalter. In Kombination mit Dual-View Decoding (DvD), das Bild- und Textverarbeitung parallel auf zwei GPUs verteilt, wird die Inferenz bis zu viermal schneller.
Auch Qwen 2.5-VL nutzt das Konzept für Videos: unwichtige Abschnitte werden in niedriger Auflösung verarbeitet, nur entscheidende Szenen im Detail.
Denker und Sprecher: Qwens Thinker–Talker-Architektur
Mit Qwen Omni führt Alibaba eine neue Form der Multimodalität ein: Audio Speech durch das Zusammenspiel von Denker und Sprecher.
Zwei spezialisierte Komponenten arbeiten parallel – eine trennt das Verstehen vom Sprechen.
Der Thinker ist das „Gehirn“ des Systems: Er verarbeitet Text, Bilder, Audio-Transkripte oder Videoframes und formuliert intern eine textuelle Antwort.
Der Talker übernimmt diese Antwort und wandelt sie in Echtzeit in Sprache um – während der Thinker noch denkt – dank eines intelligenten Streaming-Ansatzes, der fortlaufend kleine Audiosegmente erzeugt, sobald Textteile verfügbar sind.
Dadurch reagiert das Modell nahezu ohne Verzögerung – in Dialogen oder bei multimodalen Aufgaben wie der Beschreibung eines Videos. Beide Module sind Teil eines gemeinsamen Modells und so eng abgestimmt, dass Qwen3-Omni Bild- oder Videoinhalte analysieren und gleichzeitig live kommentieren kann. Die Latenz ist laut Alibaba rund 40 % geringer als bei herkömmlichen Sprachpipelines.
Die Aufteilung in Thinker und Talker erlaubt, beide Systeme unabhängig zu optimieren: Der Thinker bleibt ein tiefes, verständnisorientiertes Modell; der Talker fokussiert sich auf effiziente, natürlich klingende Ausgabe. Das schafft die Grundlage für Echtzeit-Agenten, die zuhören, nachdenken und sprechen können – ohne die Komplexität eines einzigen, überladenen Modells.
Modelle wie Qwen2.5-Omni und Qwen3-Omni sind offen zugänglich und bieten damit Einblick in eine Architektur, die künftig für Anwendungen wie Übersetzer, Tutoren oder interaktive Assistenten prägend sein könnte.
Die Ironie der Transparenz
In den USA werden Investitionen in KI zunehmend mit spekulativen Risiko-Narrativen gerechtfertigt: General AI als potenziell zivilisationsbedrohende Technologie, deren Kontrolle höchste Priorität haben müsse. China wird in diesem Diskurs oft als der autoritäre Gegenspieler dargestellt – das abschreckende Beispiel, das amerikanische Verschwiegenheit legitimieren soll.
Doch gerade dort entsteht heute die sichtbarste offene Forschung. Während westliche Konzerne über Sicherheitsrisiken reden, veröffentlichen chinesische Labore detaillierte Paper, Trainingsmethoden und Modellgewichte – die Bausteine wissenschaftlicher Nachvollziehbarkeit. Und die USA sollte in der aktuellen politischen Situation vielleicht vorsichtig sein, mit dem Begriff „autoritär“ um sich zu werfen.
Datum: 20.10.2025
Bildquelle: KI-generiert mit ChatGPT
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.