Wenn wir Sprachmodelle wie ChatGPT testen, vergleichen wir sie oft mit dem Menschen. Wir fragen: „Versteht die KI Sprache wie ein Mensch?“ oder „Urteilt sie moralisch wie ein Mensch?“ Doch eine aktuelle Studie der Harvard University stellt die entscheidende Gegenfrage: Welcher Mensch?
Die Menschheit ist kein Monolith. Unsere Werte, Normen und Moralvorstellungen unterscheiden sich rund um den Globus drastisch. Das Paper mit dem Titel „Which Humans?“ (Atari et al., 2023) hat untersucht, wessen psychologisches Profil GPT-4 eigentlich widerspiegelt. Die Ergebnisse sind faszinierend – und sie zwingen uns zu einer unbequemen Diskussion darüber, was wir von einer KI eigentlich erwarten.
Das Ergebnis: ChatGPT ist WEIRD
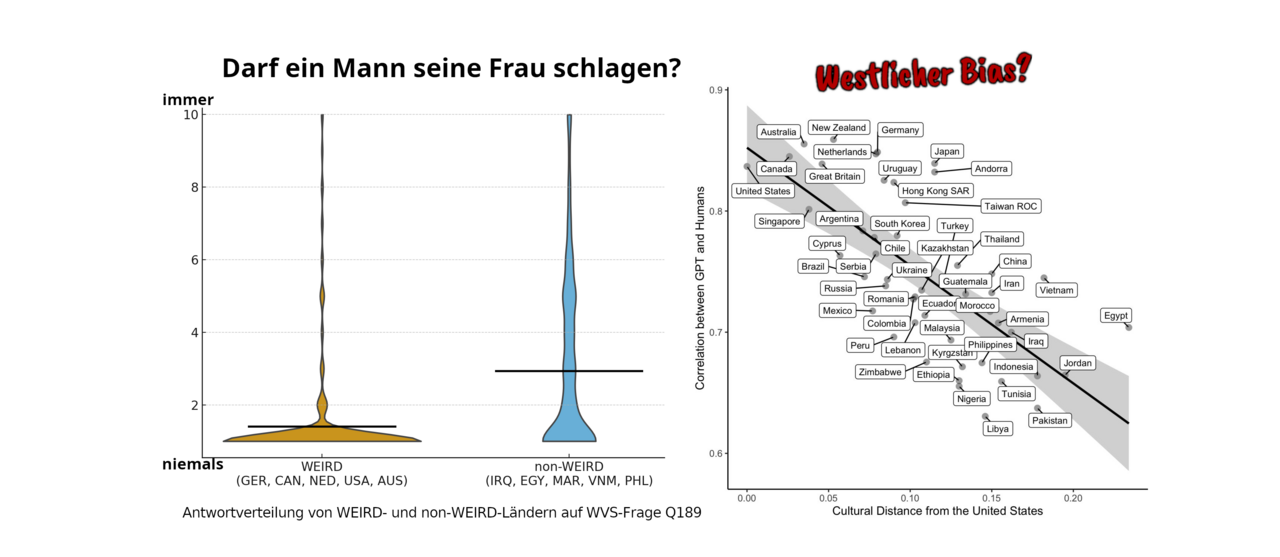
Die Forscher ließen ChatGPT (GPT-4) Fragen aus dem World Values Survey (WVS) beantworten – einem der umfangreichsten Datensätze zu menschlichen Werten weltweit.
Das Ergebnis ist eindeutig: Die Antworten der KI korrelieren extrem stark mit den Antworten von Menschen aus sogenannten WEIRD-Gesellschaften (Western, Educated, Industrialized, Rich, Democratic).
Hohe Übereinstimmung: USA, Kanada, Niederlande, Deutschland.
Geringe Übereinstimmung: Äthiopien, Pakistan, Jemen.
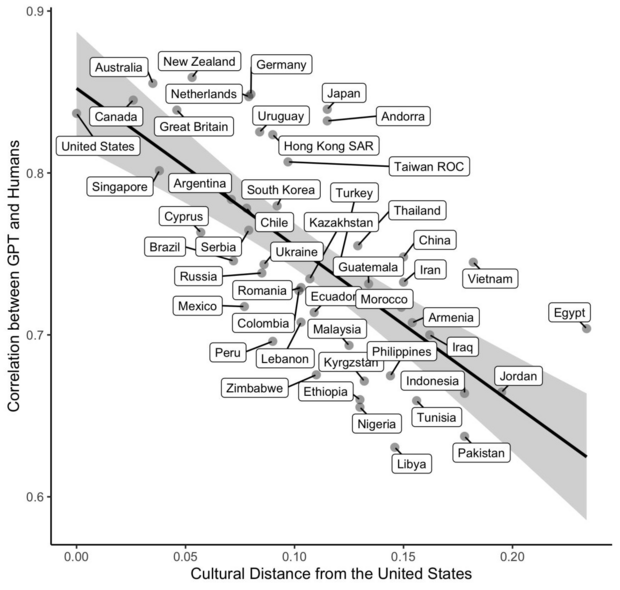
Die Korrelation zwischen der kulturellen Distanz zu den USA und der Ähnlichkeit der KI-Antworten liegt bei -0,70. Kurz gesagt: Je weniger „westlich“ ein Land ist, desto weniger repräsentiert ChatGPT dessen Durchschnittsmeinung. Die Autoren folgern: „WEIRD in, WEIRD out“ – die Trainingsdaten verzerren das Weltbild der KI.

Aber ist das wirklich ein Problem der Daten?
Hier lohnt sich ein genauerer Blick auf die Fragen des World Values Survey. Viele der Fragen, bei denen die KI stark von nicht-westlichen Ländern abweicht, betreffen harte moralische Konflikte.
Einige Beispiele aus dem Survey, die in vielen Teilen der Welt kontrovers beantwortet werden:
- „Würden Sie Homosexuelle, Menschen einer anderen Rasse oder Unverheiratete als Nachbarn akzeptieren?“ (Q18–Q26)
- „Ist es gerechtfertigt, wenn ein Mann seine Frau schlägt?“ (Q189)
- „Sind Männer die besseren politischen Führer als Frauen?“ (Q29)
In vielen Ländern, die im Paper als kulturell „weit entfernt“ von ChatGPT dargestellt werden, sind diskriminierende Antworten auf diese Fragen gesellschaftlicher Mainstream. Wenn ChatGPT also auf die Frage nach Gewalt in der Ehe mit absoluter Ablehnung reagiert, dann verhält es sich statistisch gesehen „untypisch“ für einen Durchschnittsmenschen aus bestimmten Weltregionen.
Das Dilemma: Repräsentation vs. Ethik
Das Paper kritisiert zu Recht, dass LLMs (Large Language Models) psychologische Vielfalt ignorieren. Aber hier stoßen wir auf ein fundamentales Design-Problem:
- Der Default-Modus: Ein Sprachmodell muss im „Zero-Shot“-Szenario (ohne spezifische Anweisungen) eine Standard-Antwort geben. Es kann nicht gleichzeitig alle kulturellen Perspektiven einnehmen.
- Die Safety-Leitplanken: Wir trainieren Modelle (RLHF), um harmlose, hilfreiche und ehrliche Assistenten zu sein. Das bedeutet zwangsläufig, dass sie bei Fragen zu Menschenrechten, Gleichberechtigung und Gewalt eine Position einnehmen, die wir im Westen als „fortschrittlich“ oder „universell“, andere aber als „kulturellen Imperialismus“ bezeichnen könnten.
Würde die KI den „Durchschnittsmenschen“ aus Pakistan oder Libyen perfekt simulieren, müsste sie laut WVS-Daten Aussagen zustimmen, die gegen die meisten Content-Policies der KI-Firmen verstoßen (z.B. Diskriminierung von Minderheiten).
Ein Ausblick: Kann die KI auch anders?
Die Kritik des Papers, dass die Default-Einstellung der Modelle westlich ist, ist valide. Aber bedeutet das, dass die Modelle unfähig sind, andere Perspektiven zu verstehen?
Wir führen aktuell Experimente durch, die genau hier ansetzen. Wir testen, ob wir diesen „Western Bias“ durch gezieltes Persona Prompting aufbrechen können. Was passiert, wenn wir ChatGPT bitten, nicht als neutraler Assistent, sondern aus der Perspektive einer bestimmten kulturellen Gruppe zu antworten?
Unsere ersten Daten deuten darauf hin, dass die Modelle durchaus in der Lage sind, kulturelle Nuancen abzubilden – wenn man sie explizit danach fragt. Die „westliche Brille“ scheint also eher eine Voreinstellung (Default) zu sein als eine unveränderliche Einschränkung der Repräsentationskraft.
Dazu bald mehr in einem detaillierten Deep-Dive mit unseren Ergebnissen.
Bis dahin bleibt die Frage an euch: Sollte ein globales KI-Modell im Standard-Modus „kulturell neutral“ sein (falls das überhaupt geht) – oder ist ein Bias hin zu Menschenrechten und liberalen Werten genau das, was wir wollen?
Datum: 25.11.2025
Bildquelle: Korrelationsplot aus „Which Humans?“ (Atari et al., 2023)
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.